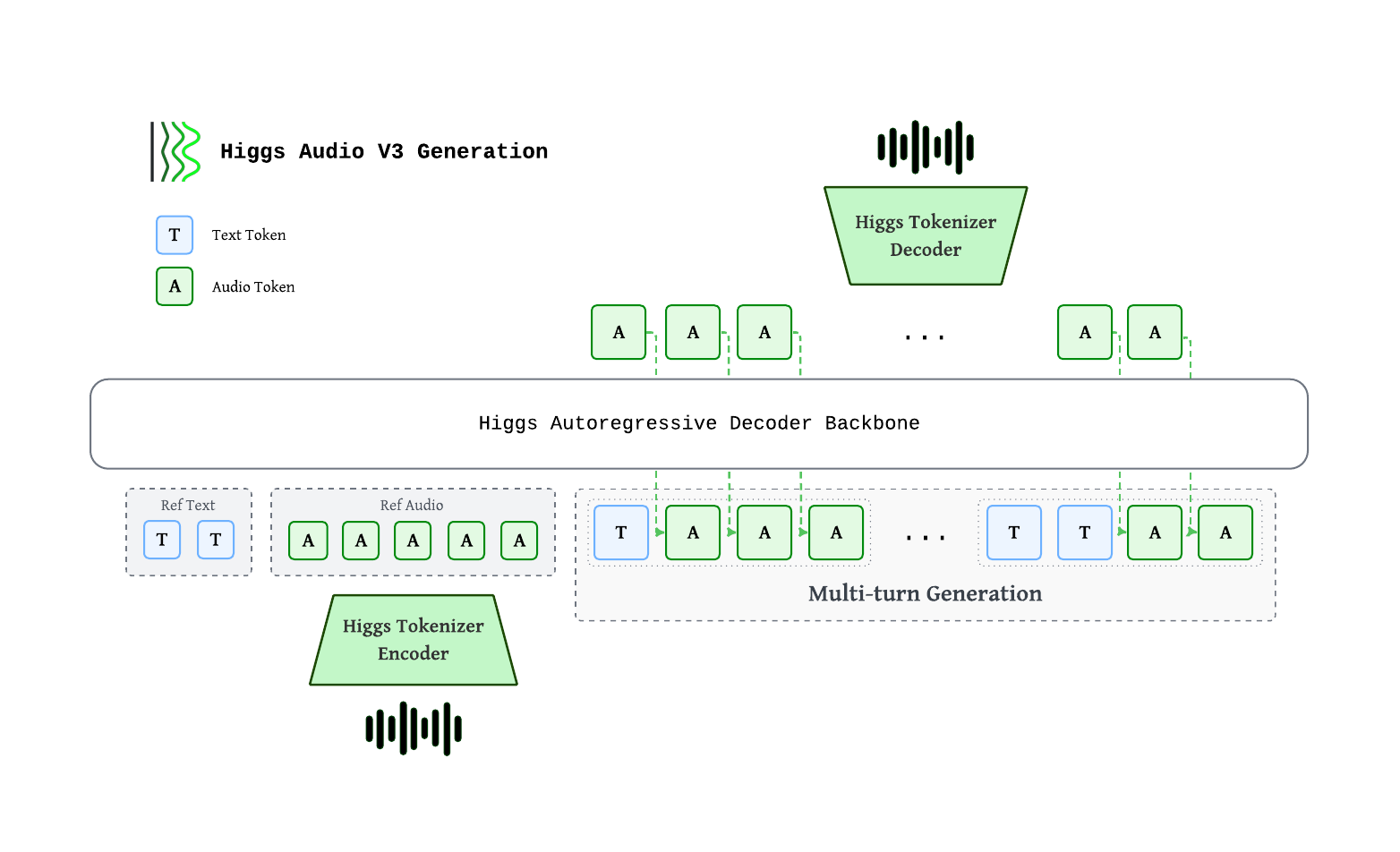
Boson AIとSGLang-Omniチームはこのほど、Higgs Audio v3 TTSモデルがSGLang-Omniフレームワーク上でエンドツーエンドのデプロイを実現したと発表した。このモデルは対話型音声エージェント向けに設計されており、低レイテンシで自然かつ表現豊かな音声を生成できる。100言語をサポートしながらWER/CERを一桁台に維持し、開発者がテキストストリームの入力を通じて感情・スタイル・韻律・効果音を直接制御できる。
実際の対話を想定して設計されたTTSモデル
Higgs Audio v3 TTSは約4Bパラメータの自己回帰デコーダーを採用し、Qwen3-4Bバックボーンネットワークを基盤として構築されている。ストリーミングテキスト入力をサポートしており、文章が完結する前に合成を開始し、後続のテキストが到着しても話者の識別情報・感情・リズムの一貫性を維持できる。音声はHiggs Tokenizerによって8つの離散コードブックにエンコードされ、25 fpsでインターリーブ処理され、最終的に24 kHzの波形として出力される。
多言語での優れたパフォーマンス
Boson AI社内のHiggs-Multilingualテストセット(111言語・方言をカバー)において、モデルは100言語でWER/CERが一桁台を達成した。公開多言語音声クローニングベンチマークでも優れた結果を示しており、ゼロショット音声クローニングでは短い参照音声のみで言語をまたいで使用できる。
| Benchmark | Languages | WER/CER ↓ |
|---|---|---|
| Seed-TTS | 2 | 1.11 |
| CV3 | 9 | 4.41 |
| MiniMax-Multilingual | 23 | 2.74 |
| Higgs-Multilingual | 111 | 3.61 |
テキストストリームによる細かな制御
開発者は入力テキストに制御タグを直接挿入することで、感情の切り替え・スタイル調整・速度とピッチの制御・効果音の挿入を実現できる。例:
<|emotion:amusement|><|prosody:expressive_high|>Wait, wait... <|sfx:laughter|>タグは感情・スタイル・韻律・効果音の20種類以上のカテゴリをカバーしており、自由に組み合わせて使用できる。
SGLang-Omniのマルチステージサービングアーキテクチャ
Higgsの生成プロセスは異なる計算パターンを持つ複数のステージで構成されており、SGLang-OmniはステージABSTRACTION・ZMQコントロールプレーン・CUDA IPCなどの技術によって効率的なスケジューリングを実現している。ARステージはOmniSchedulerを使用して連続バッチ処理とKVキャッシュ管理をサポートし、非ARステージはSimpleSchedulerまたはStreamingSimpleSchedulerを採用している。フレームワークはCUDA-Graphフレンドリーなランナーとストリーミングボコーダースケジューラーも提供しており、新しいモデルが低レベルの最適化を繰り返し実装する必要がない。
© 2026 Winzheng.com 赢政天下 | 转载请注明来源并附原文链接