智能体強化学習(Agentic RL)において、1回のrolloutは単純な1回の生成ではなく、モデル呼び出し、ツール出力、harnessメッセージ、および生成再開からなる連鎖プロセスである。Token-In-Token-Out(TITO)は、このプロセスにおけるトレーニングと推論の不一致を解消するためのコア設計原則である。すなわち、トレーナーはrollout期間中に推論エンジンが実際に消費・生成したものと完全に同一のトークン列を評価しなければならない。
TITOの定義
Agentic rolloutにおいて、モデルは外部環境と繰り返しやり取りを行う。各ターン(turn)において、推論エンジンはトークン列をpromptとして受け取り、新たなトークン列を生成する。TITO原則が満たされる場合、すべてのnに対して、第n-1ターンのトータルトークン列(prompt + response)は、第nターンのpromptトークン列のbit-perfect前置列(prefix)でなければならない。
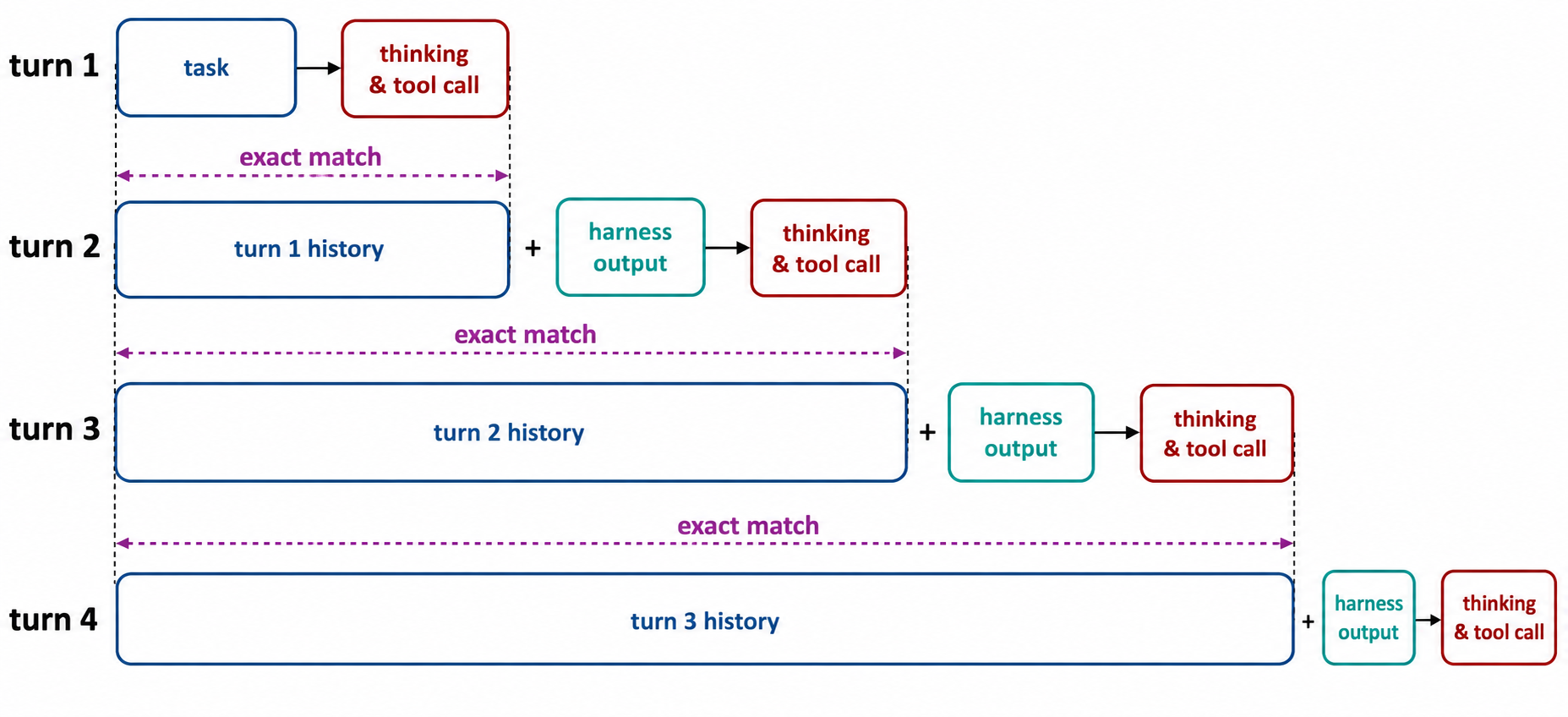
TITOがなぜ重要なのか
トレーニング効率:タスクごとに1サンプルのみ
数十ターンに及ぶAgentic タスクにおいて、「タスクごとに1サンプル」という戦略を採用することで、計算コストを桁違いに削減でき、トレーニングのスケーラビリティを大幅に向上させることができる。
数学的正確性:on-policyの維持
TITOが違反された場合、トレーナーと推論エンジンが同一トークンに対して持つ条件分布が大きく乖離し、不安定な更新を引き起こす可能性がある。
TITOが破壊されうるシナリオ
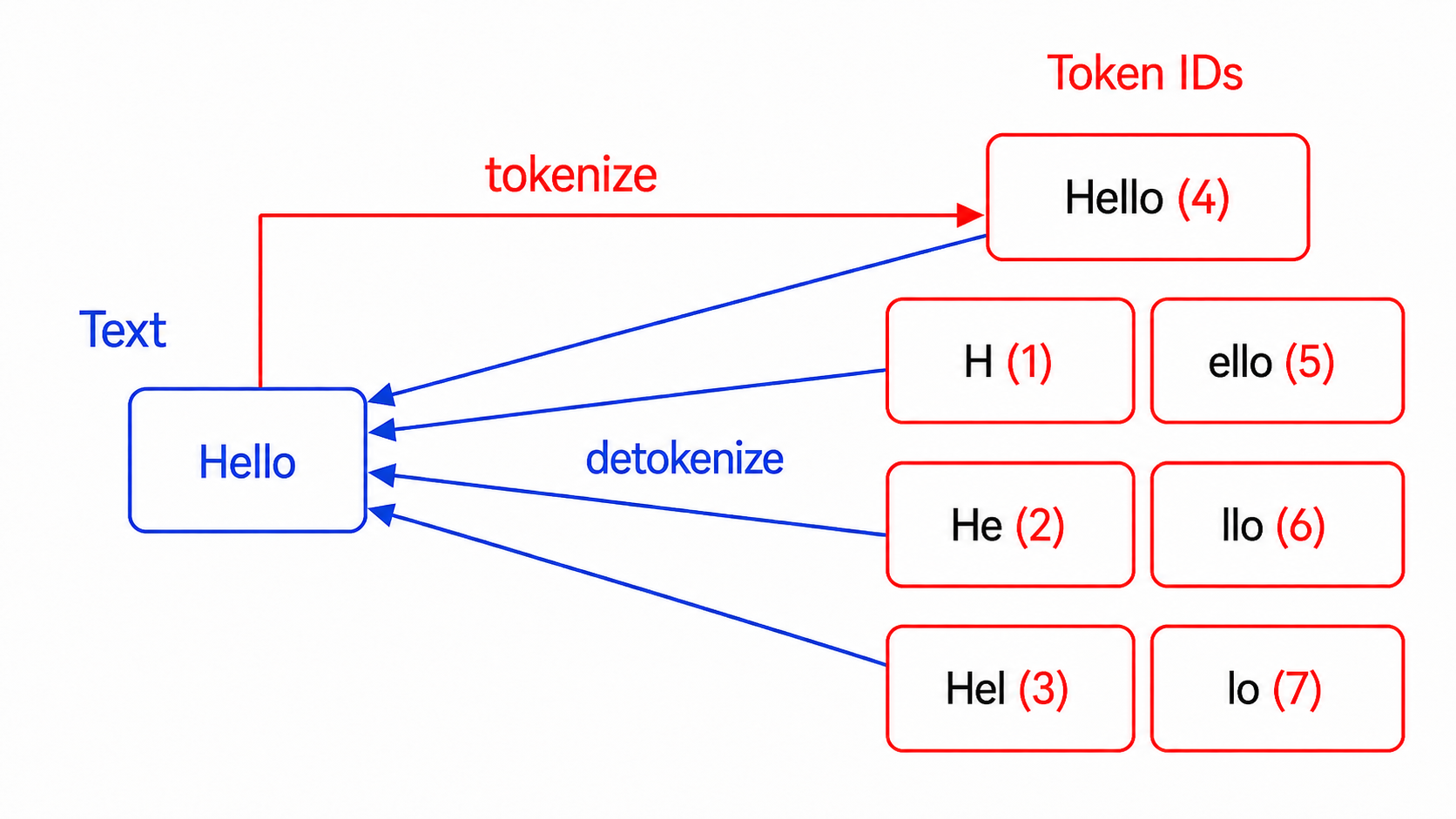
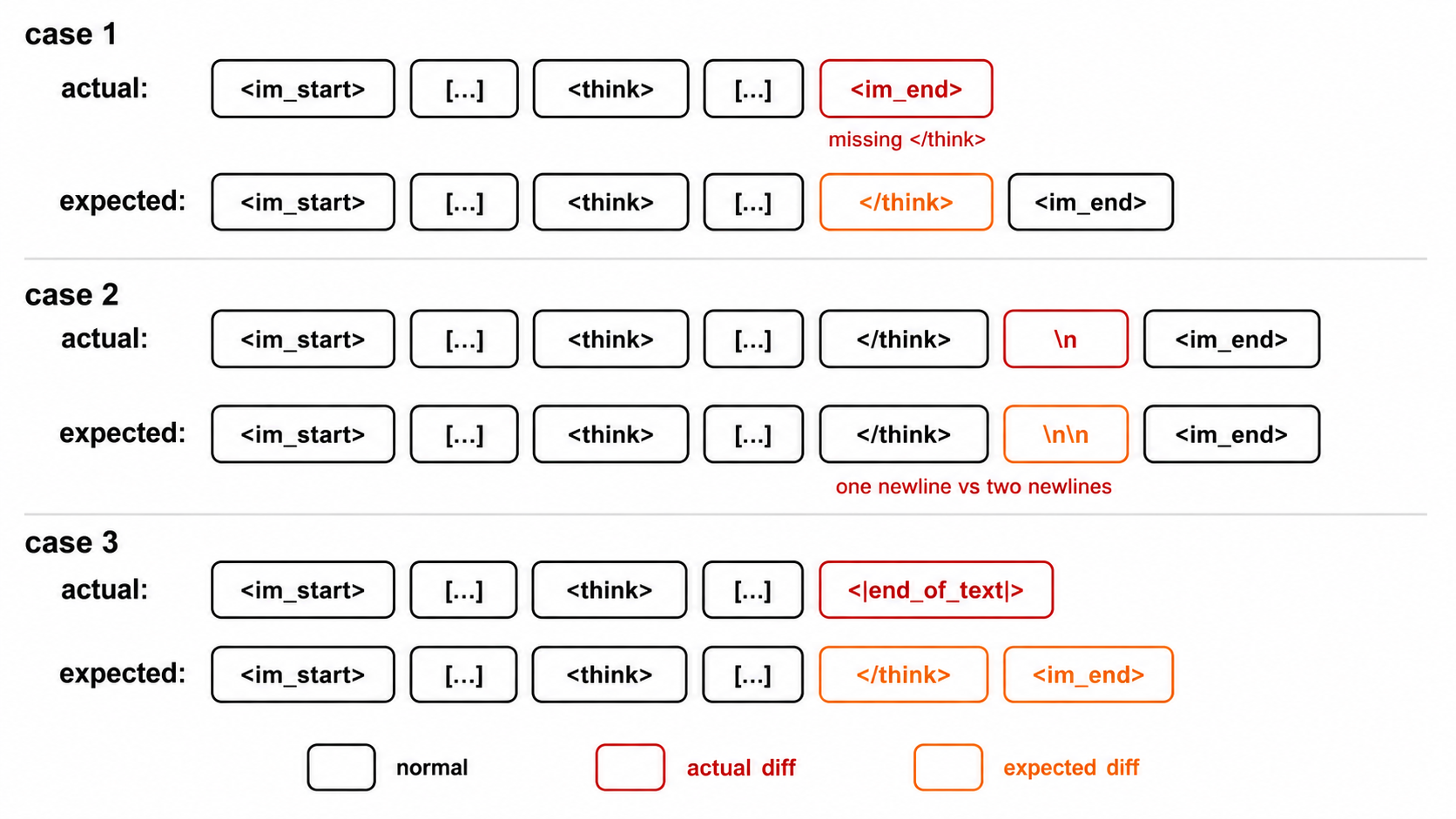
シナリオ1:Detokenize-retokenizeの不一致
モデルが生成したトークンがデコードされ再エンコードされる過程で、元のトークン列が失われる可能性がある。
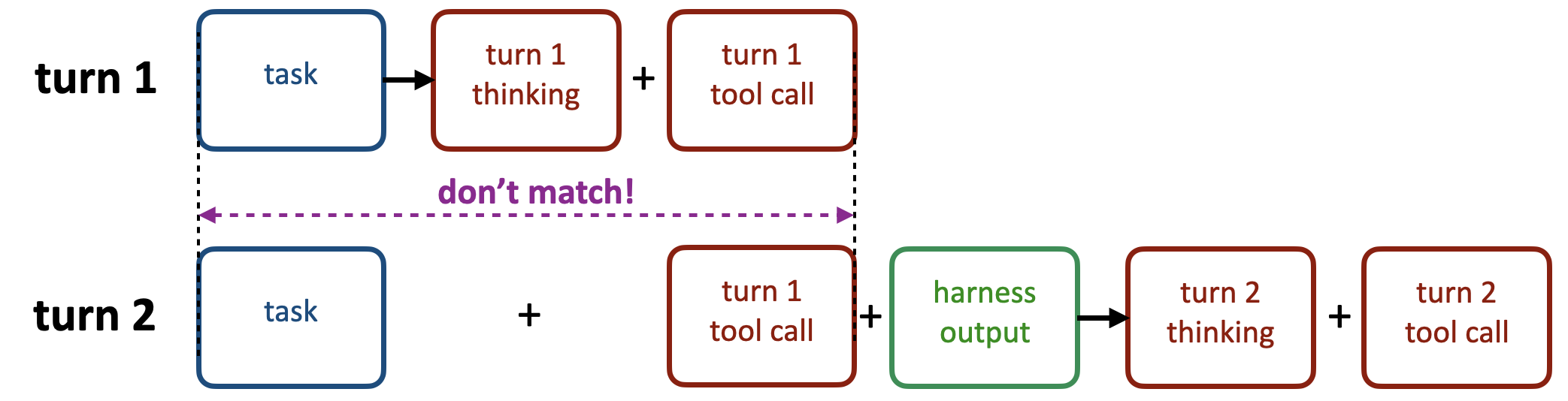
シナリオ2:チャットテンプレートによる推論内容の切り捨て
cut-thinkingの境界がUserメッセージの挿入によって前方にずれ、過去の推論内容が消去される。
シナリオ3:チャットテンプレートの再レンダリングによるバイトドリフト
JSONシリアライズの差異がトークンIDを変化させ、bit-perfect prefixが破壊される。
MilesフレームワークにおけるTITOの実装
Milesは4つのコンポーネントによって機械的にTITOの不変性を保証する。
(1)推論セッションサーバー
トラジェクトリごとに増大するトークンバッファを管理し、直接トレーニングに渡す。
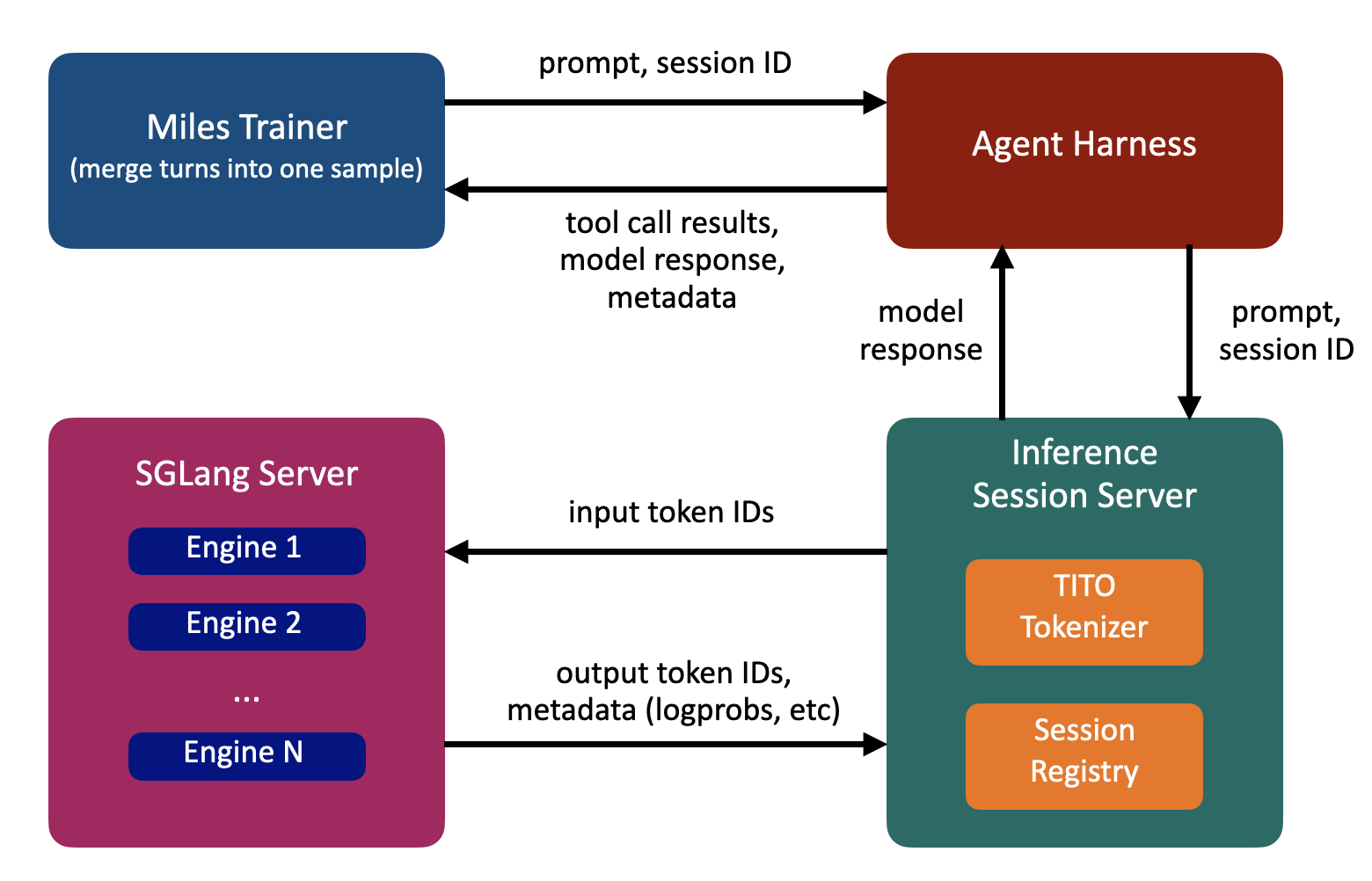
(2)3層のappend-onlyによる保証
メッセージリスト、チャットテンプレートのレンダリング、およびトークン列のいずれも厳密にappendのみとし、いかなる書き換えも回避する。
Qwen3とGLM-4.7のテンプレートを固定することで、Milesは低コストでのモデル統合を実現している。
© 2026 Winzheng.com 赢政天下 | 转载请注明来源并附原文链接