
Novita AI は SGLang をベースに、GLM4-MoE モデル向けの本番環境検証済み高インパクト最適化ソリューションを開発しました。カーネル実行効率からクロスノードデータ転送スケジューリングまで、推論パイプライン全体をカバーするエンドツーエンドのパフォーマンス最適化戦略を提案します。Shared Experts Fusion と Suffix Decoding を統合することで、エージェントコーディングワークロードにおける主要指標を大幅に向上させました。
本番環境向けコア最適化の実装
1. Shared Experts Fusion
この最適化は Deepseek モデルに関連する研究に由来しています。GLM4.7 はすべての入力トークンを共有エキスパートに通すと同時に、各トークンを top-k エキスパートにルーティングし、最終的に加重集約して出力します。共有エキスパートをルーティング MoE 構造に統合する(161 個のエキスパートから top 9 を選択)ことで、TP8 FP8 構成において SM 利用率を大幅に向上させ、メモリ I/O オーバーヘッドを削減します。
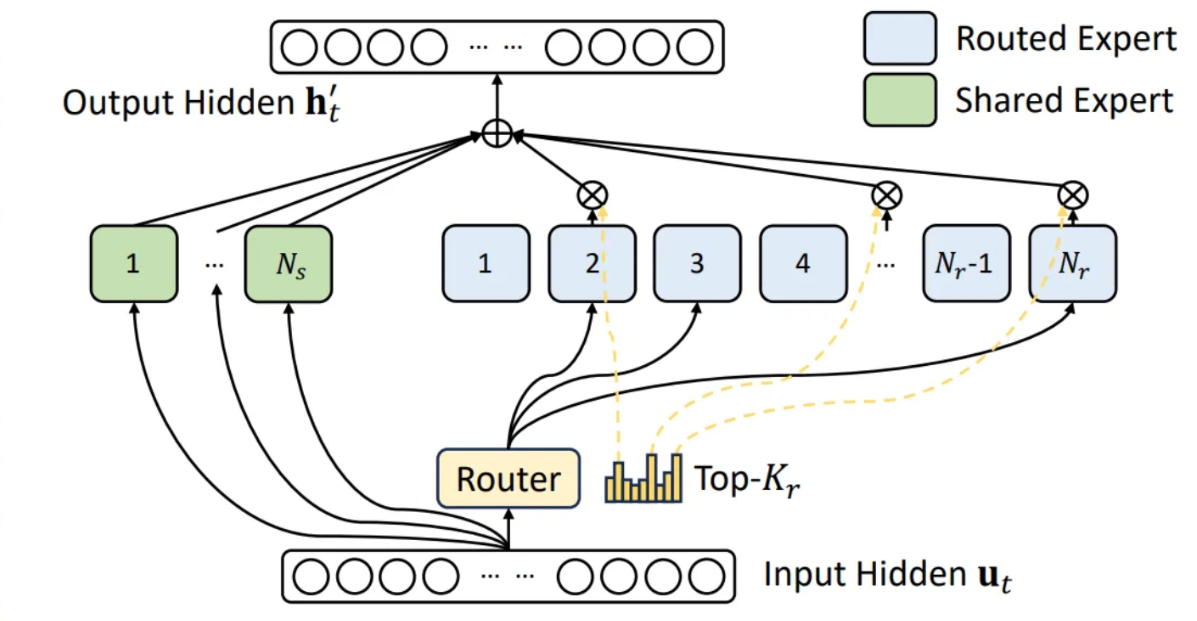
この最適化により、TTFT 最大 23.7%、ITL 最大 20.8% の改善が得られます。
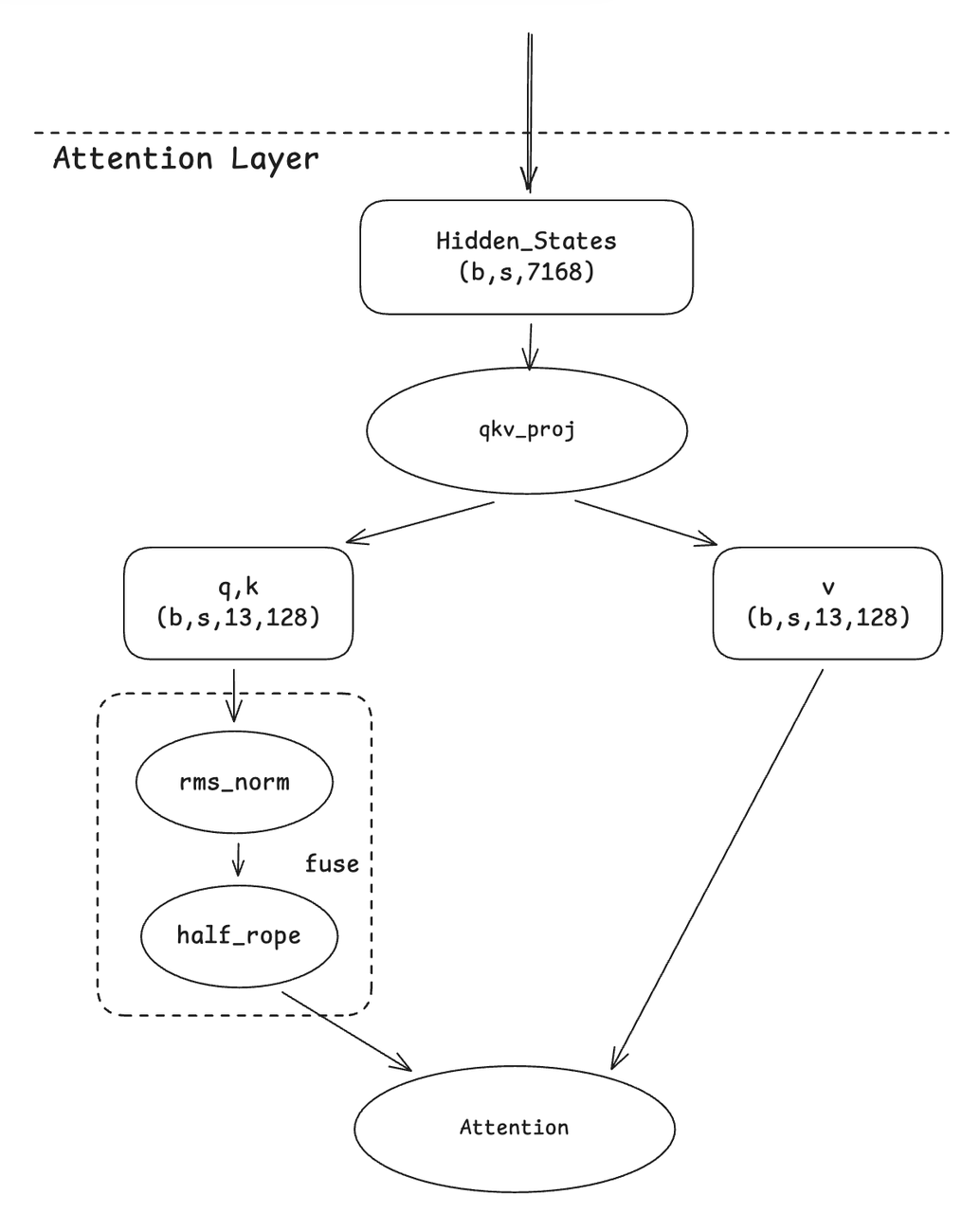
2. Qknorm Fusion
Qwen-MoE の最適化アプローチをベースに、head-wise で計算するオペレーターを単一カーネルに融合し、GLM4-MoE が head 内の半分の次元のみをローテーションするという特性に適応しています。
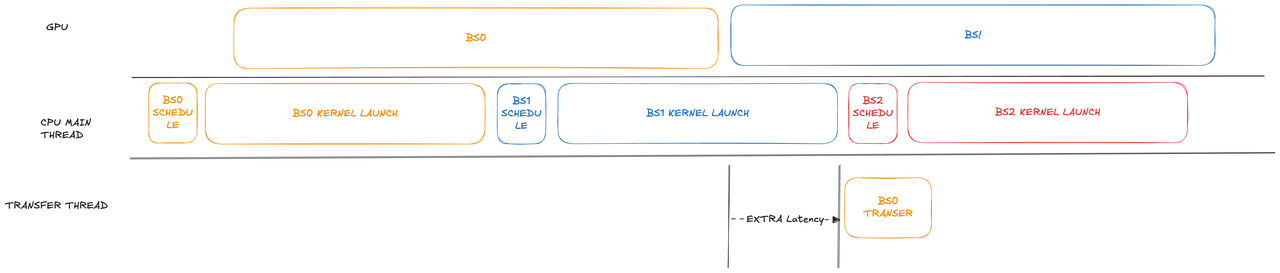
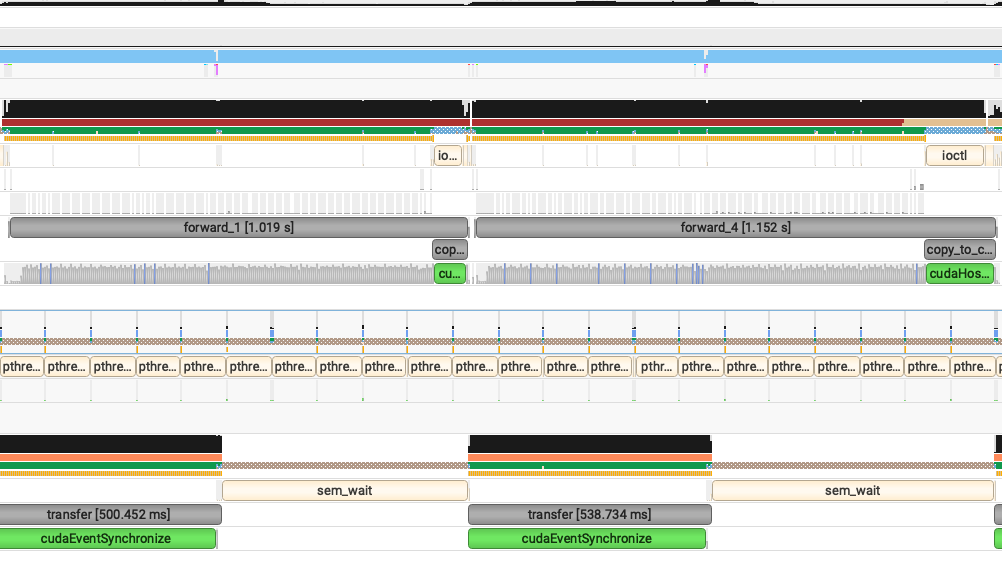
3. Async Transfer
PD 分離オーバーラップスケジューリング環境において、データ転送を事前にスケジュールして独立スレッドに配置し、メインスレッドのブロッキングを回避します。92 層モデルに対して、高負荷時に最大 1 秒の TTFT 節約が可能です。
本番環境ベンチマーク結果
テスト構成:入力長 4096、出力長 1000、リクエストレート 14 req/s、モデル GLM-4.7 FP8 (TP8)。
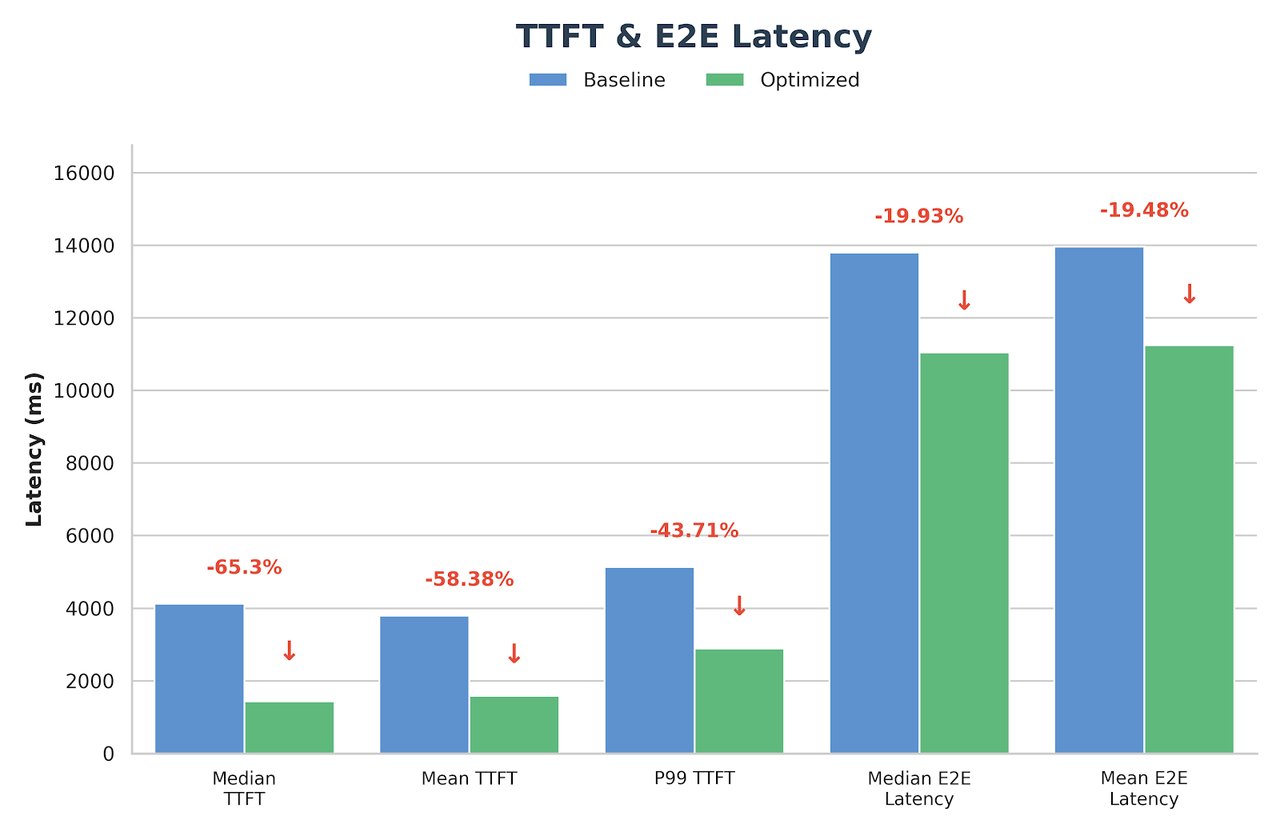
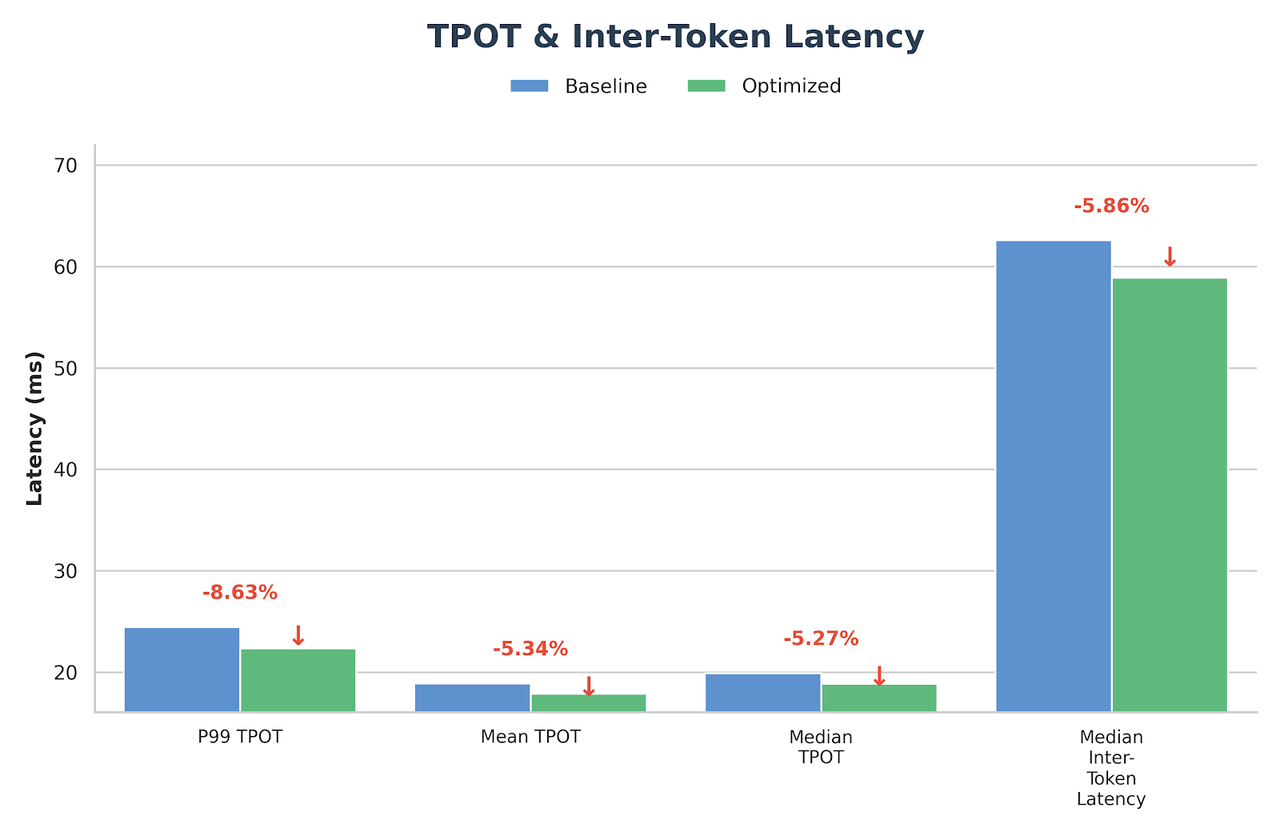
Suffix Decoding
エージェントコーディングシナリオにおいて、Suffix Decoding は追加のモデルウェイトを必要とせず、過去の出力パターンを活用した投機的デコーディングにより、TPOT をさらに 22% 削減します(25.13ms から 19.63ms へ)。
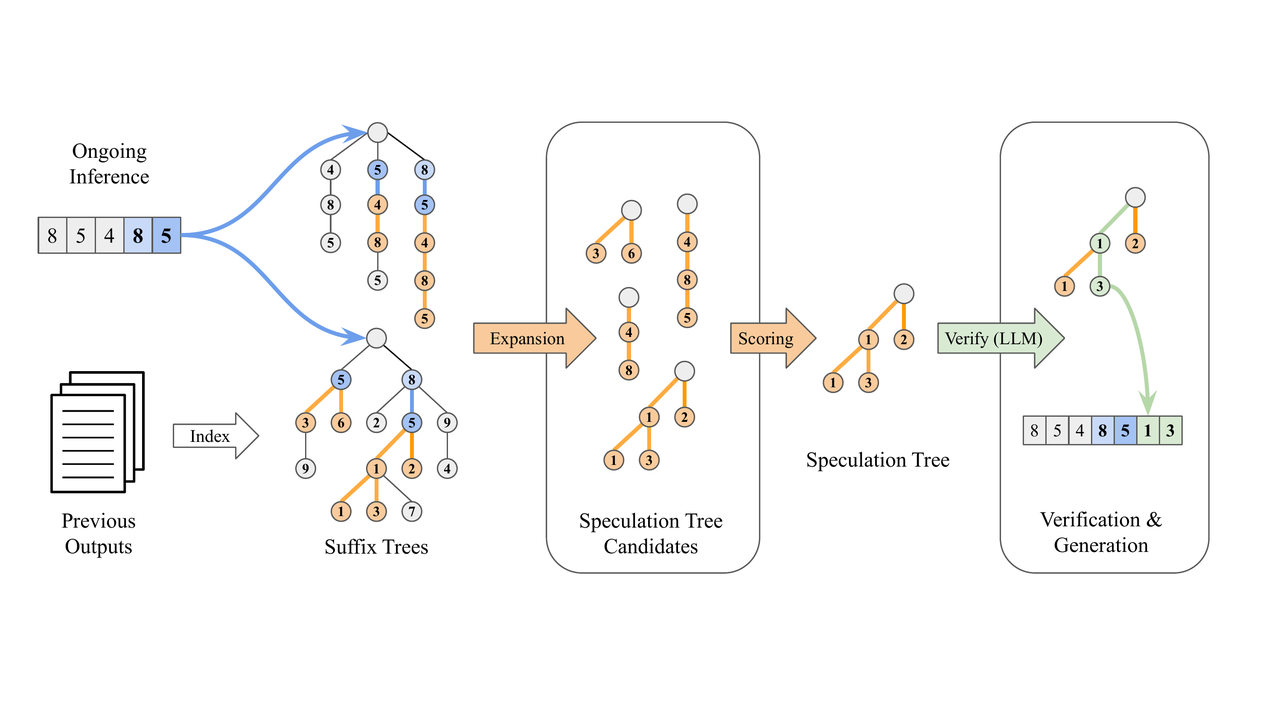
まとめ
これらの最適化は Novita AI の本番推論サービスにデプロイ済みであり、大部分のコンポーネントは SGLang のアップストリームリポジトリにマージされています。
© 2026 Winzheng.com 赢政天下 | 转载请注明来源并附原文链接