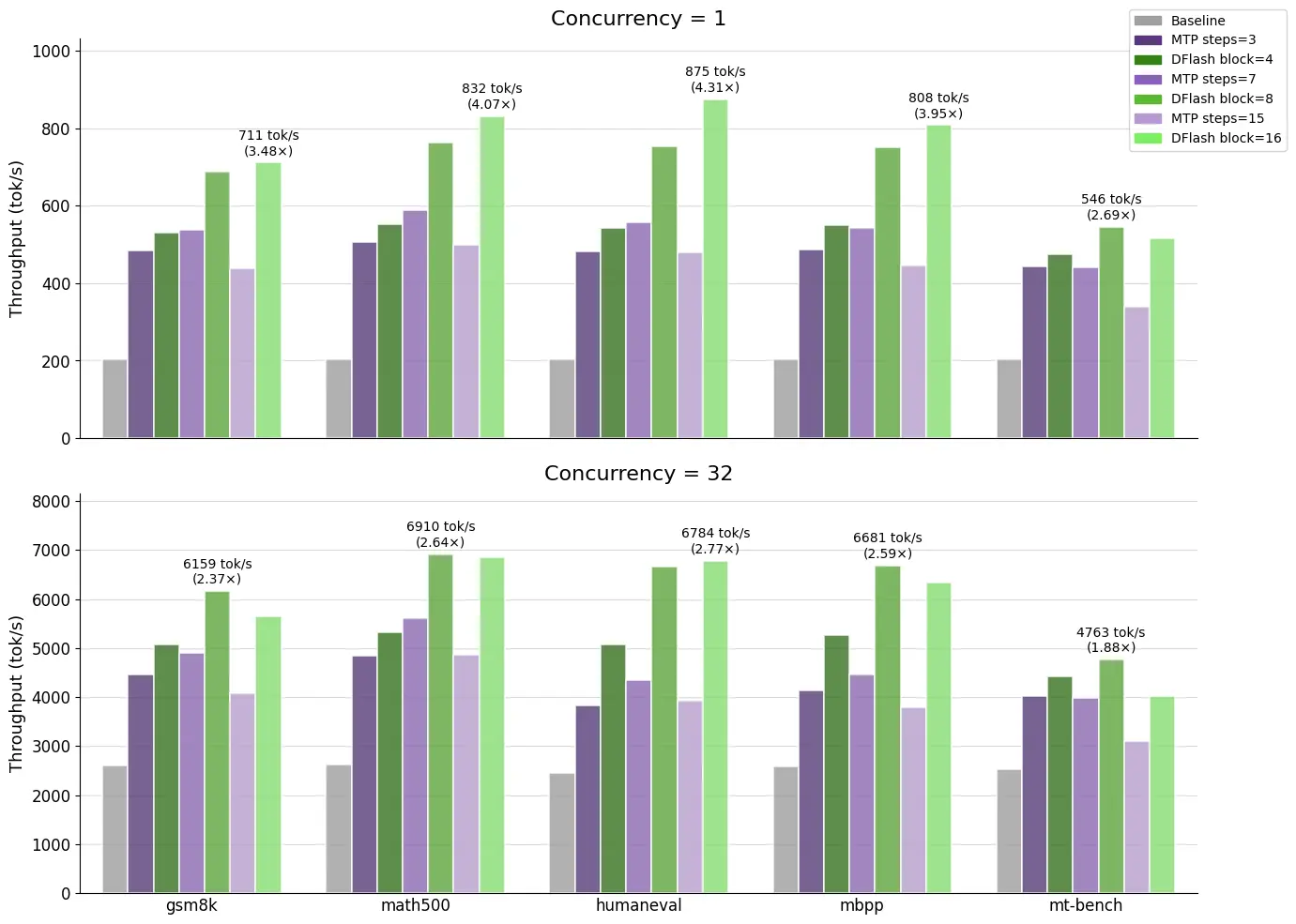
Modal、Z Lab、SGLangチームが共同でDFlash投機的デコーディングモデルを発表し、SGLangの新デフォルトエンジンSpec V2と組み合わせることで、LLM推論サービスの最適レイテンシを実現する。新たに公開されたQwen 3.5 397B-A17B専用DFlashモデルは、全ベンチマークテストにおいて、スループットがベースラインモデルとネイティブMTPの両方を上回った。
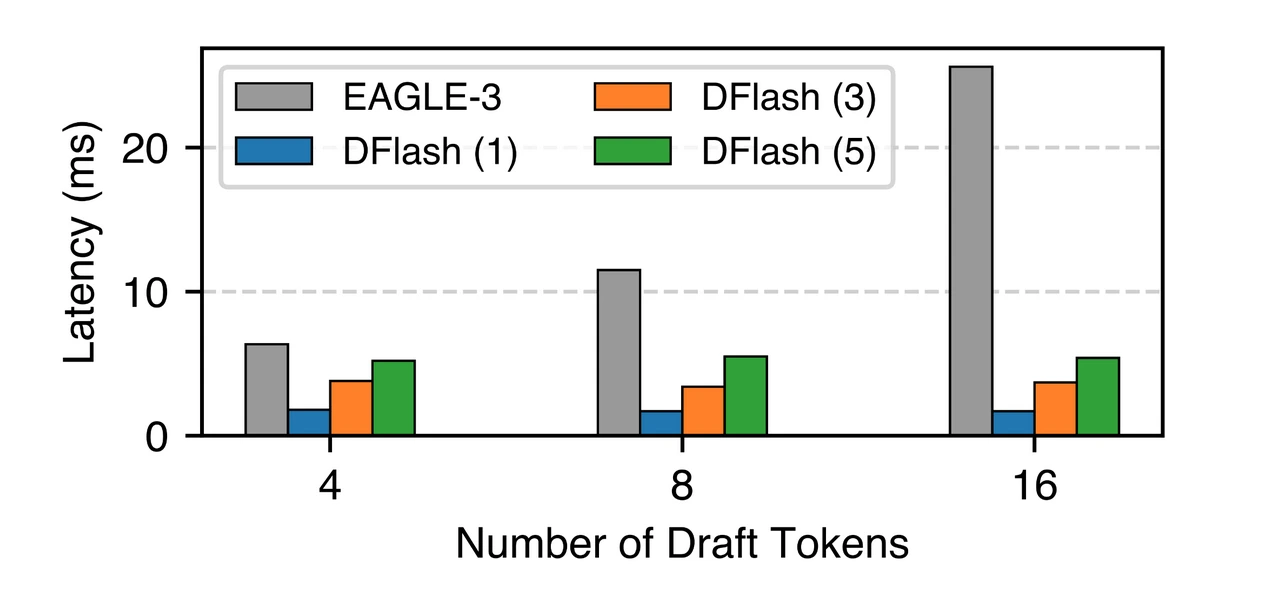
HumanEvalコーディングデータセット、同時実行数1、貪欲デコーディング設定において、そのスループットはベースラインの4.3倍以上、MTPの1.5倍を達成した。
3プラットフォーム同時オープンソース公開
今回のコラボレーションを記念し、モデルはHugging Faceの3つの組織で同時公開された:z-lab/Qwen3.5-397B-A17B-DFlash、modal-labs/Qwen3.5-397B-A17B-DFlash、およびlmsys/Qwen3.5-397B-A17B-DFlash。
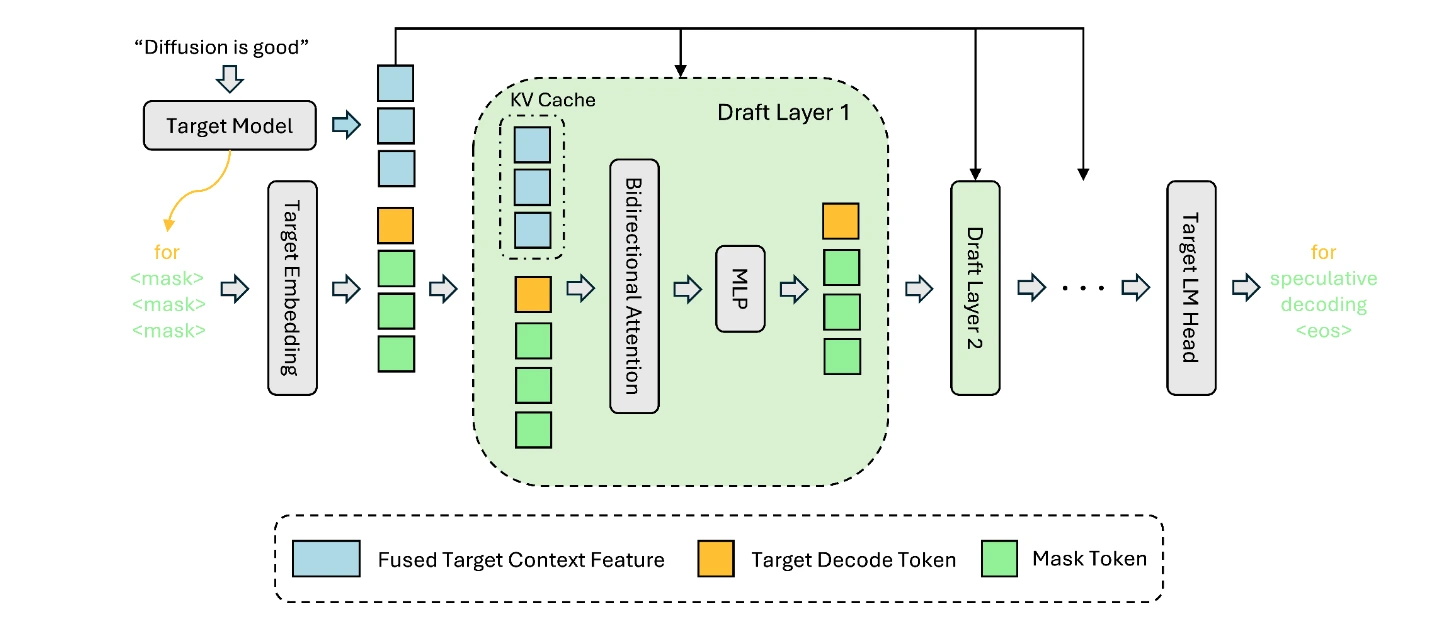
DFlashのコア技術:ブロック拡散+KV注入
従来の自己回帰デコーディングは効率が低く、投機的デコーディングは小さなドラフトモデルで複数のトークンを並列提案し、ターゲットモデルが検証することで、品質を損なわずに大幅な高速化を実現する。しかしEAGLEシリーズとネイティブMTPは依然として順次生成に依存しており、高速化の上限を制限している。
Z Labが開発したDFlashは軽量なブロック拡散ドラフトモデルを採用し、トークンのブロック全体を一度に並列生成できるため、GPU/TPUの特性に完全にマッチする。重要な革新は、ターゲットモデルの隠れ表現をドラフトモデルのKVキャッシュに直接注入する点にあり、これによりドラフトモデルはコンテキストをゼロから構築する必要がなく、次のトークンブロックの予測に集中できる。
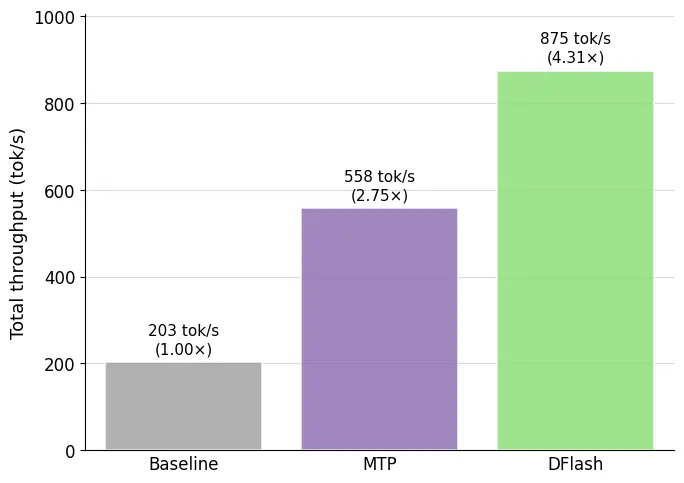
DFlashはなぜ速いのか?
高速化の効果は受け入れ長さとドラフトのオーバーヘッドに依存する。DFlashは両方を同時に最適化する:拡散ドラフトがコストを削減し、KV注入が受け入れ長さを向上させる。5層DFlashはGSM8K、HumanEval、MT-Benchのすべてにおいてに対してEAGLE-3を大幅に上回った。
SGLang Spec V2との統合
SGLangチームはDFlashを研究プロトタイプから本番グレードのエンジンへと最適化し、まずV1エンジンに統合してKVキャッシュ共有を実現し、次にV2エンジンへ移行してホスト同期を削減することでさらなる性能向上を達成した。ユーザーはパラメータを指定するだけで高性能サービスをワンクリックで起動できる。
© 2026 Winzheng.com 赢政天下 | 转载请注明来源并附原文链接