SGLangとAMDチームは緊密に協力し、AMD Instinct™ MI355X GPU上で大規模なDeepSeek-R1の分離推論における競争力のある総所有コスト(TCO)を実現した。SGLangサービスフレームワークとAMD MoRI通信ライブラリを活用し、AMDは主要な運用ポイントにおいてNVIDIA B200(Dynamo + TRT-LLM)のTCO性能に匹敵し、あるいは上回る結果を達成。この結果はSemiAnalysisのInferenceXプラットフォームによって検証されている。
主要結果の概要
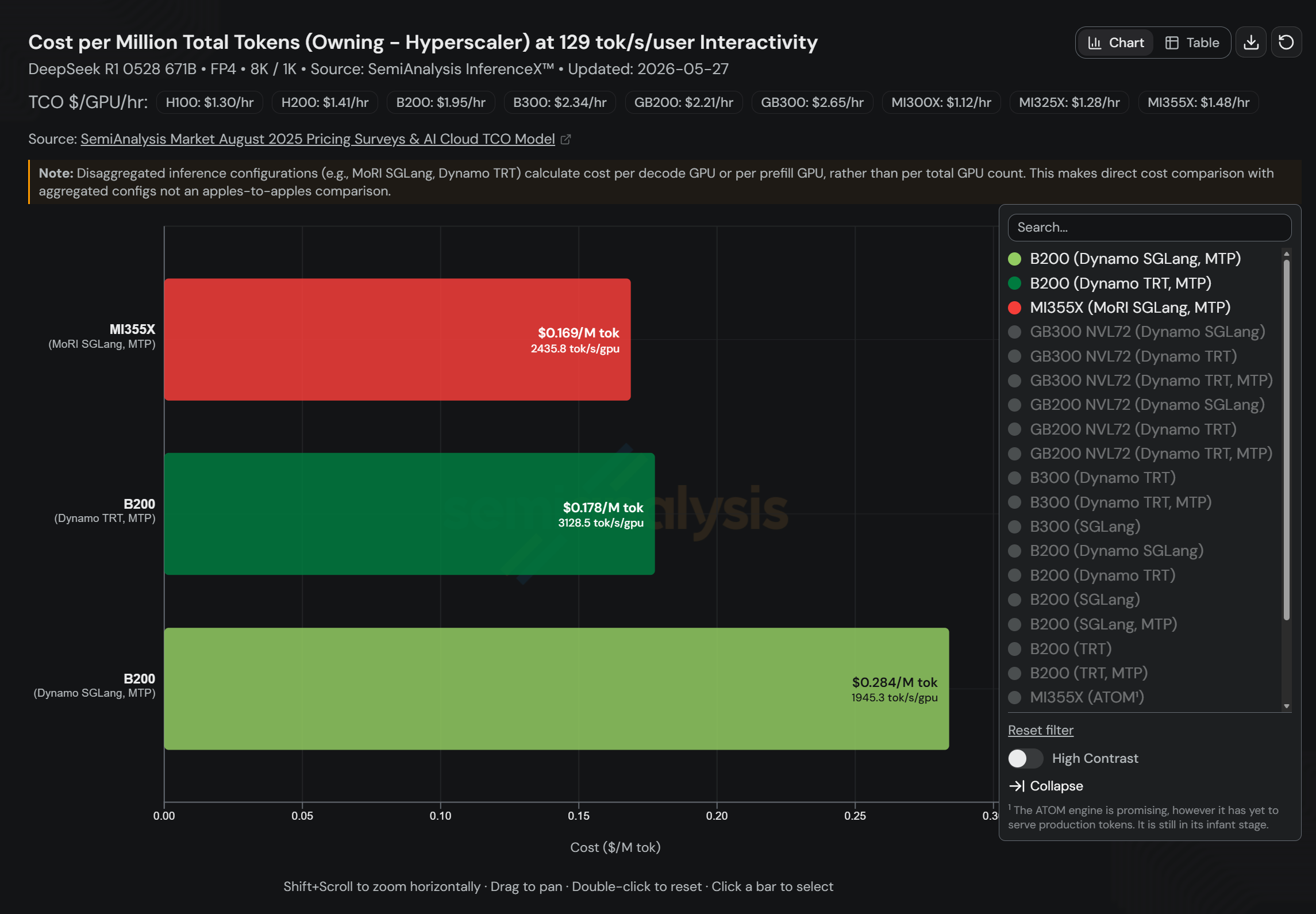
典型的な本番レベルのコーディングアシスタントおよびインタラクティブチャットボットシナリオ(129 tok/s/user のインタラクティブ性)において:
- AMD Instinct™ MI355X(MoRI SGLang MTP):100万トークンあたりのコスト0.169米ドル、GPU当たりスループット2436 tok/s(GPU 24枚)
- NVIDIA B200(Dynamo TRT-LLM MTP):100万トークンあたりのコスト0.178米ドル
- NVIDIA B200(Dynamo SGLang MTP):100万トークンあたりのコスト0.284米ドル
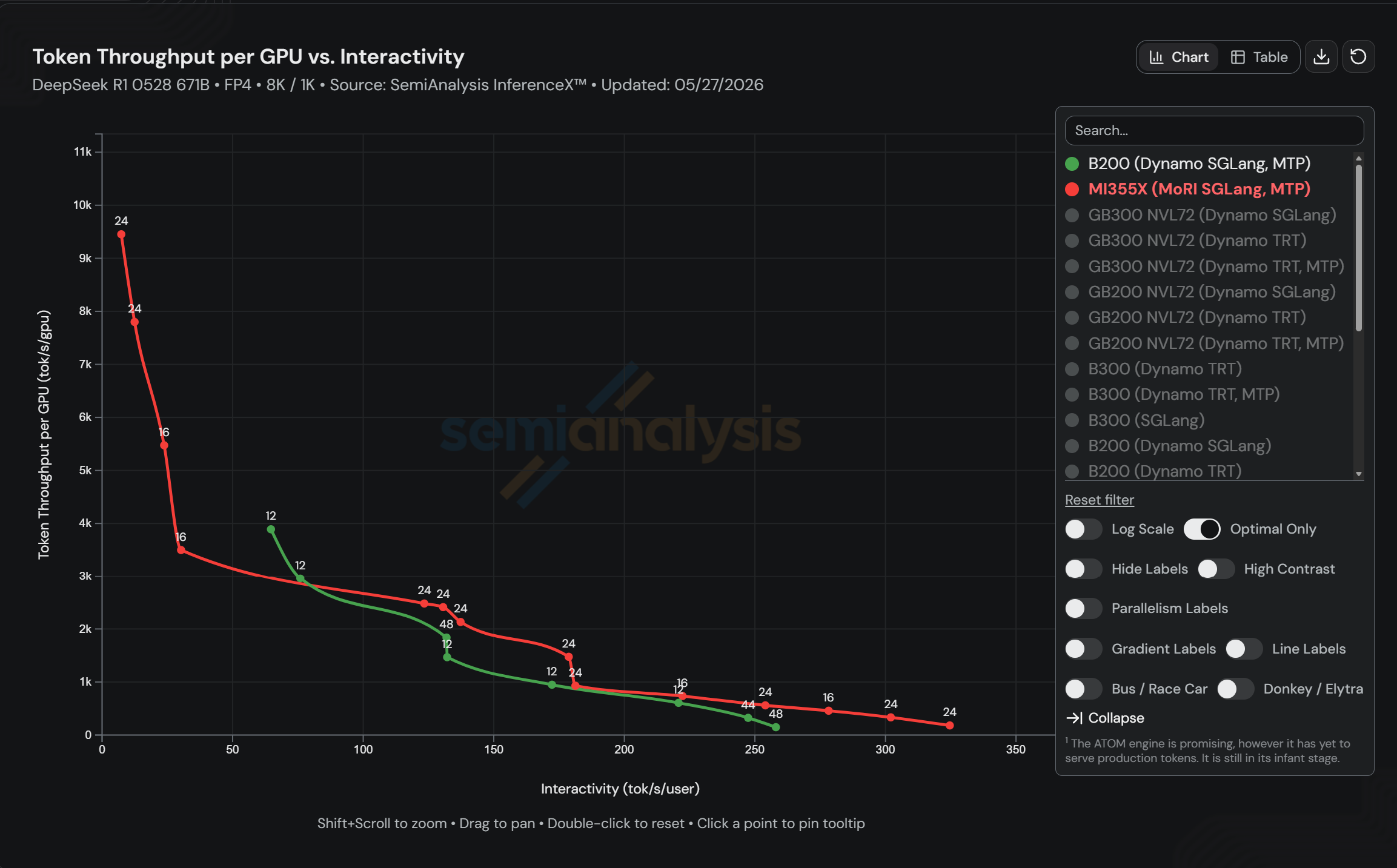
MI355XのコストはB200 TRT-LLMと比べて5%低く、B200 SGLangと比べて40%低い。また、GPU当たりスループットはB200 SGLangの1.25倍を上回る。
主要最適化技術
MoRI量化All-to-All
FP4 dispatch + FP8 combineの混合量化により、精度を維持しながら2.56倍の帯域幅削減を実現。Blockwise量化と適応的カーネル選択によりレイテンシをさらに低減。

MoRI-IO KVキャッシュバックエンド
ロックフリーインライン転送とマルチアーキテクチャ状態移行をサポートし、スループットはMooncakeより約10%高い。
Two-Batch OverlapとSDMA
デュアルマイクロバッチパイプラインにより通信レイテンシを隠蔽し、SDMAがゼロ計算オーバーヘッドのデータ移動を実現することで、全体的なスループットを大幅に向上。

© 2026 Winzheng.com 赢政天下 | 转载请注明来源并附原文链接