SGLang-JAXは現在、inclusionAIのLing-2.6-1TのTPU v7x上への効率的なデプロイをサポートしている。ベースライン実行後、性能分析によりMixture-of-Experts(MoE)パスが主要なボトルネックであることが判明した。各層でトークンを32台のJAXデバイス(v7xチップ1基につき2デバイス)にスキャタリングし、エキスパートFFNを実行した後、出力をギャザリングする必要がある。本記事では、Fused MoE V2——scatter・expert FFN・gatherを融合しつつTPUの計算とデータ移動を同時に隠蔽する全く新しいPallasカーネル——を中心に紹介する。
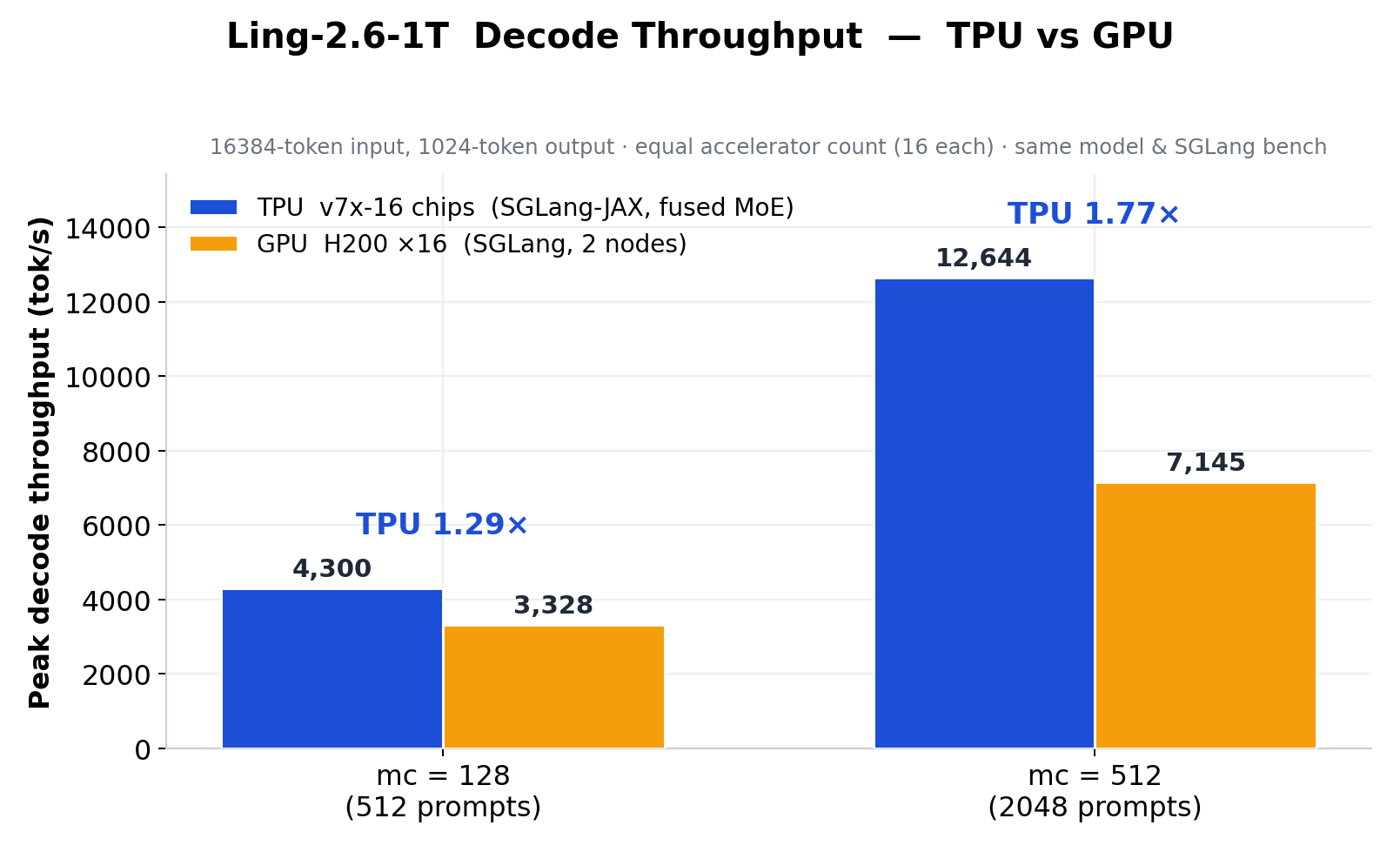
Fused MoE V2により、MoE prefillレイテンシが5.16 msから2.42 msに短縮され、同一のSGLangデコードベンチマークにおいて、16チップTPU v7xの出力スループットは16基のH200 GPUの1.29×〜1.77×を達成した。
TL;DR
- Fused MoE V2:MoE prefillレイテンシがV1比53%低下(5.16→2.42 ms)、デコードカーネルレイテンシが約15%低下(0.249→0.211 ms)。
- エンドツーエンドの効果:MoEカーネルの置き換えのみで、prefillスループットが24.8%向上、デコードスループットが18.5%〜35.3%向上。
- TPU vs H200:TPU v7x-16は、mc=128においてデコード出力スループットがH200×16の1.29倍、mc=512において1.77倍を達成。
Ling-2.6-1Tモデル概要
Ling-2.6-1Tは1Tパラメータのスパース MoEモデルであり、トークンあたり63Bパラメータを活性化する。256個のrouted expert(top-8ルーティング)に加えてshared expertを1つ備え、per-channel fp8重みとMLA + Lightning Linearのハイブリッドバックボーンネットワークを採用している。
融合MoEカーネルの最適化
すべてのMoEデータはjax.profilerのデバイストレースから取得した。テスト環境は16チップTPU v7xスライス(ep=32、2×2×4 ICIトーラス、チップあたり2デバイス)であり、入力は16,384トークンのprefillと512トークンのデコードバッチである。
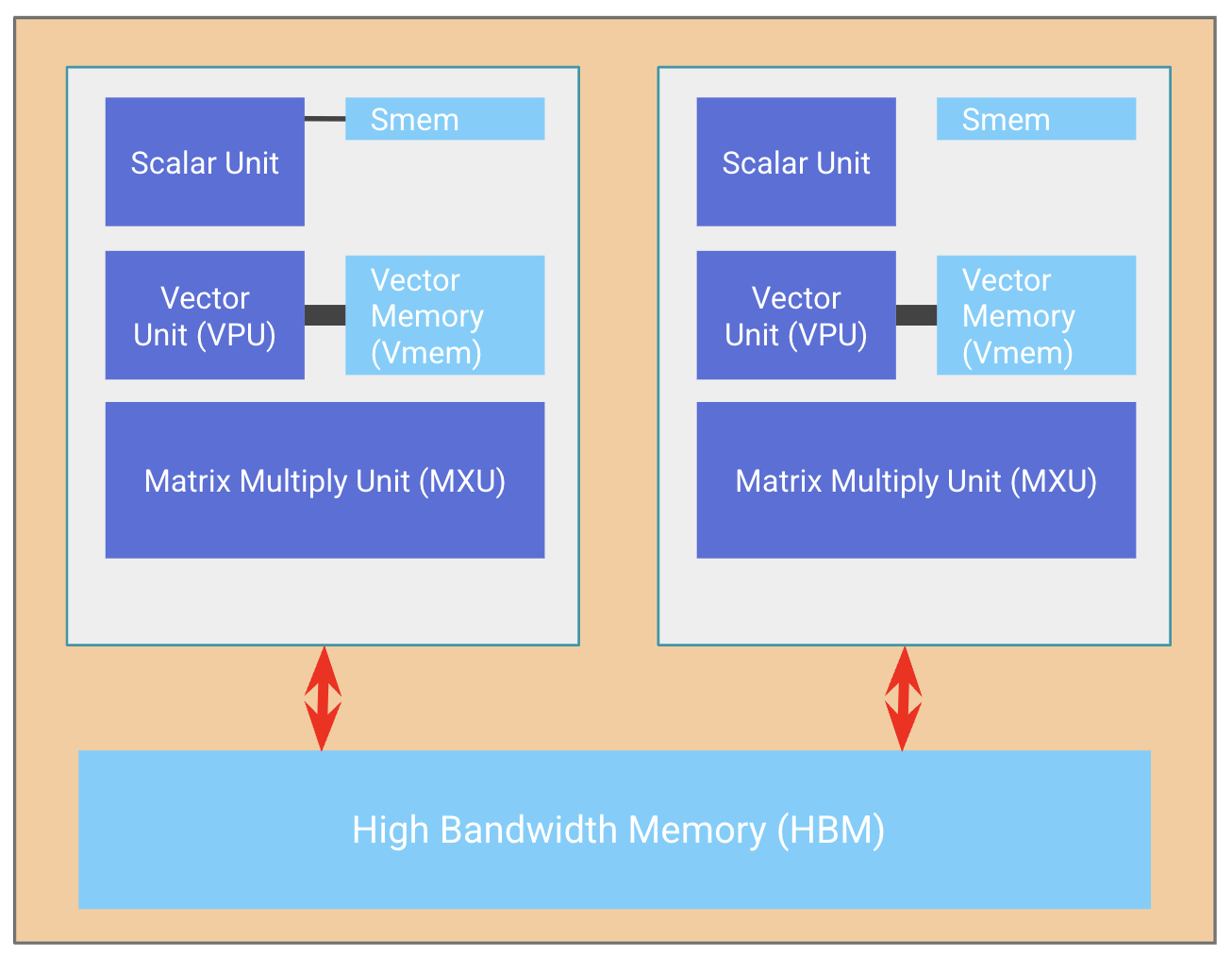
1. MoEカーネルコストモデル
各デバイスは8個のローカルrouted expertを持つ。routedパスはscatter → local expert FFN → gatherとなる。理想的な計算下限は約0.36 msであるが、実測値の2.42 msはなお約7倍高く、データ移動がボトルネックであることを示している。

2. Pallas融合カーネルが必要な理由
純粋なJAXでは、単一MoE層内部のICI-DMA・HBMプリフェッチ・MXUのオーバーラップを細かくスケジューリングすることができない。Fused MoE V2はダブルバッファリングとパイプライニングにより重みのプリフェッチを隠蔽する。
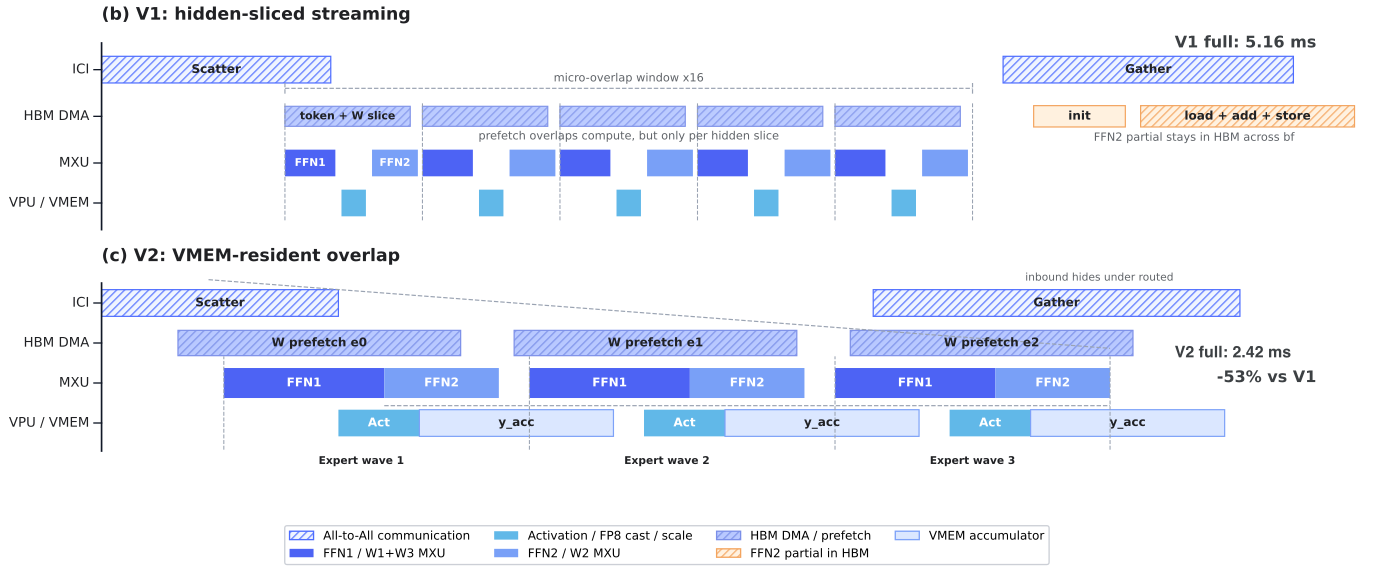
3. 性能結果
prefillクリティカルパスのブレークダウンとスループット比較により、V2がV1を大幅に上回ることが確認された。
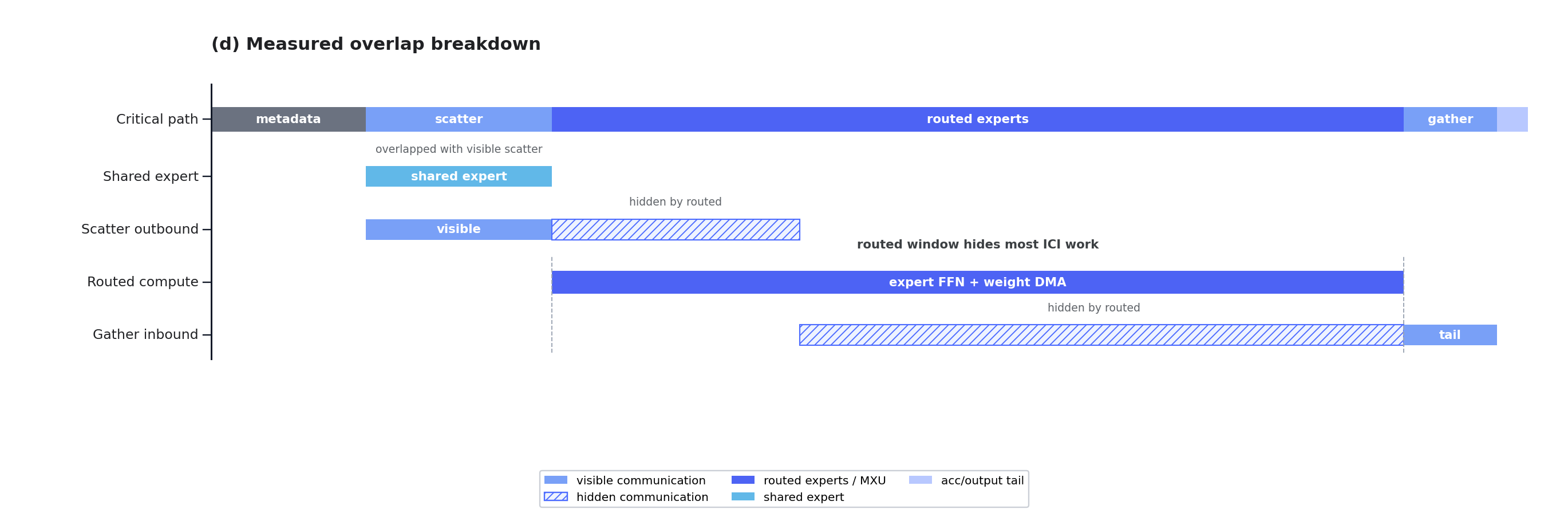
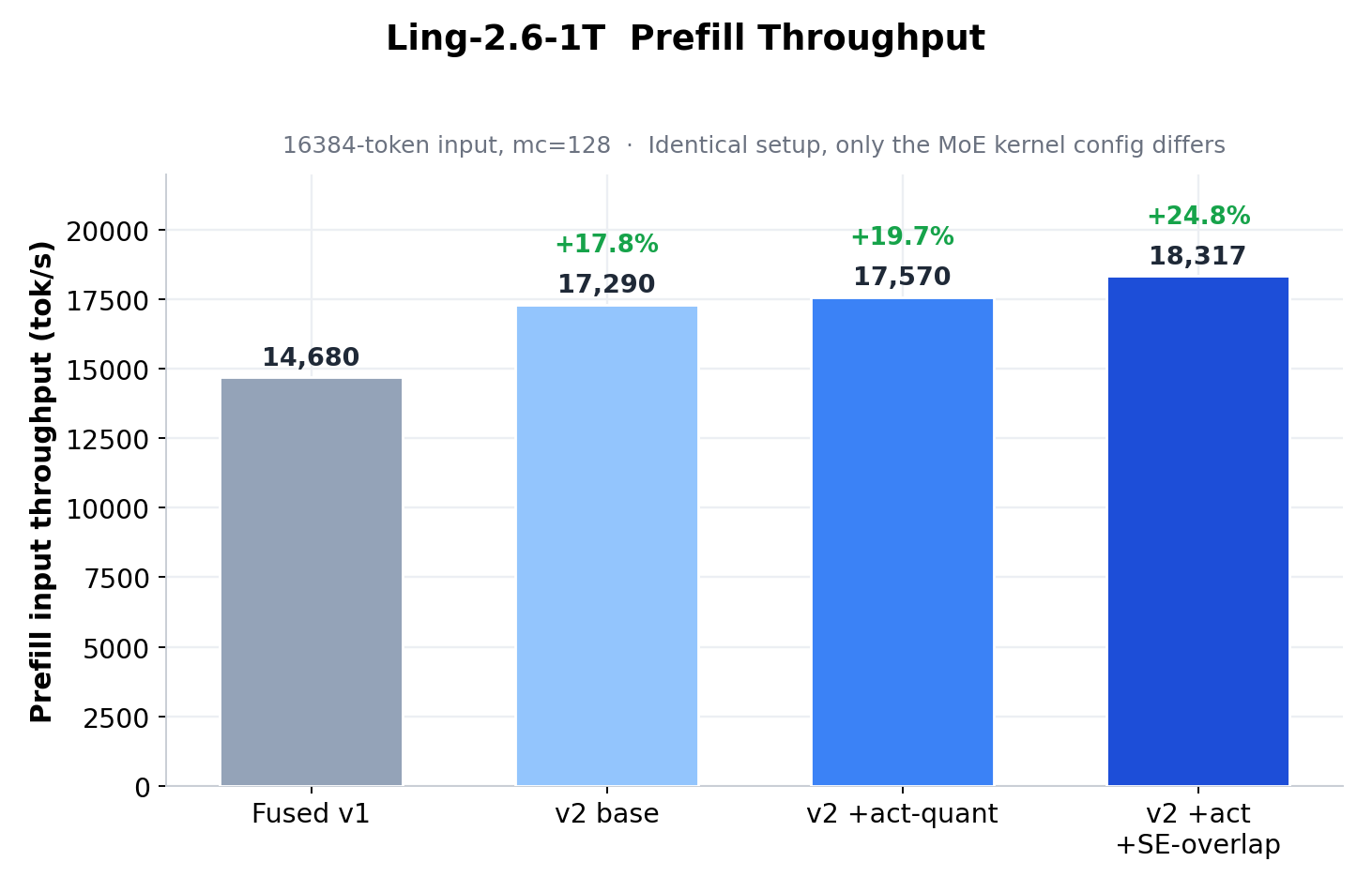
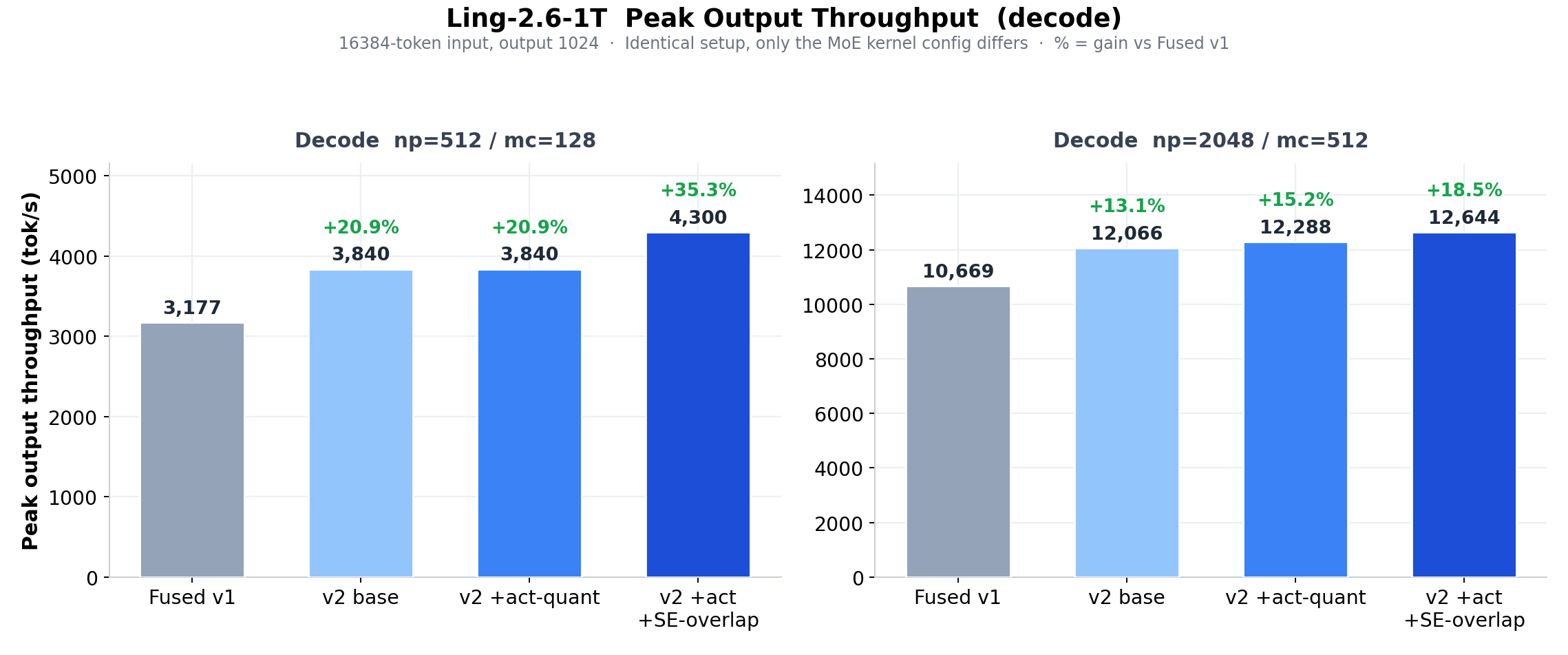
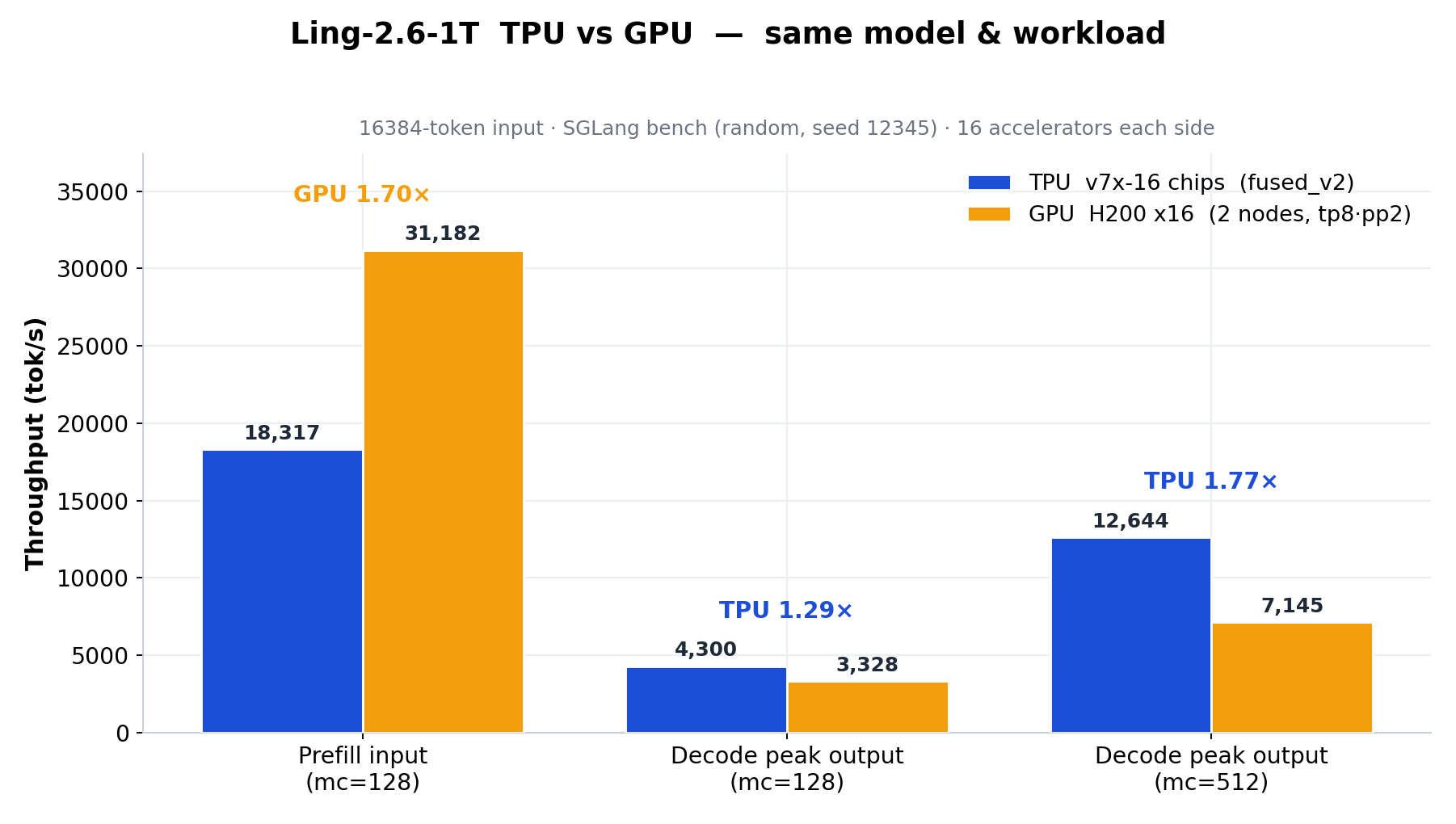
最終的に、16チップTPU v7xは同一モデル・同一ワークロード下で16基のH200を全面的に上回る結果となった。
© 2026 Winzheng.com 赢政天下 | 转载请注明来源并附原文链接