TL;DR
Mixture-of-Experts(MoE)モデルはExpert Parallelism(EP)を活用して複数GPU上での推論をスケールアウトします。SGLangのDeepEPとEPLBはすでにEP環境下で高性能なサービスを提供していますが、トークンルーティングの不均一性により、各rankの負荷がアンバランスになる場合があります。
本記事では、SGLangにおける2つのスケジューリング時負荷分散機能を紹介します:
- Waterfill:DeepEP向けの軽量な共有エキスパート負荷分散手法であり、共有エキスパートを負荷の低いrankに振り分けます。2ノードHopper GPU上において、DeepSeek-V3/R1系ワークロードで総スループットが+1.48%〜+4.66%向上し、DeepSeek V4のピークは49,253 tok/sから51,677 tok/s(+4.92%)に改善されました。
- LPLB:線形計画法に基づく冗長エキスパートレプリカの負荷分散器であり、各層の割り当て最適化問題を解きます。同一ハードウェア上でスループットが+0.84%〜+7.34%向上します。
関連PRはSGLangにマージ済みです。
はじめに
DeepSeek-V3/R1などの大規模MoEモデルは、スパースなエキスパート活性化によって容量を向上させています。EPはエキスパートをそれぞれ異なるGPUに分散し、トークンは対応するrankにルーティングされますが、ルーターが完全に均衡したトラフィックを生成することはできないため、一部のrankがボトルネックになる場合があります。静的なEPLBは長期的な配置を最適化できるものの、単一バッチ内の残余不均衡を完全に解消することはできません。WaterfillとLPLBは、スケジューリング時点で動的なバランシングを実施します。
DeepEP MoE推論における負荷不均衡
DeepEPは最適化されたトークンdispatchおよびcombineカーネルを提供します。典型的なDeepSeekスタイルのMoE層では、各トークンが複数のrouted expertにルーティングされ、一部のモデルではすべてのトークンに適用されるshared expertも含まれます。静的配置では実行時の不均衡を完全に解消できないため、WaterfillとLPLBがこの問題への解決策として提案されています。
Waterfill:共有エキスパートの軽量負荷分散
Waterfillは共有エキスパートをスケジューリング可能なスロットとして扱い、各rankの現在のrouted負荷に基づいて動的にターゲットrankを選択します。負荷の低いrankを優先的に埋めることで、最も遅いMoE層のパスを短縮します。
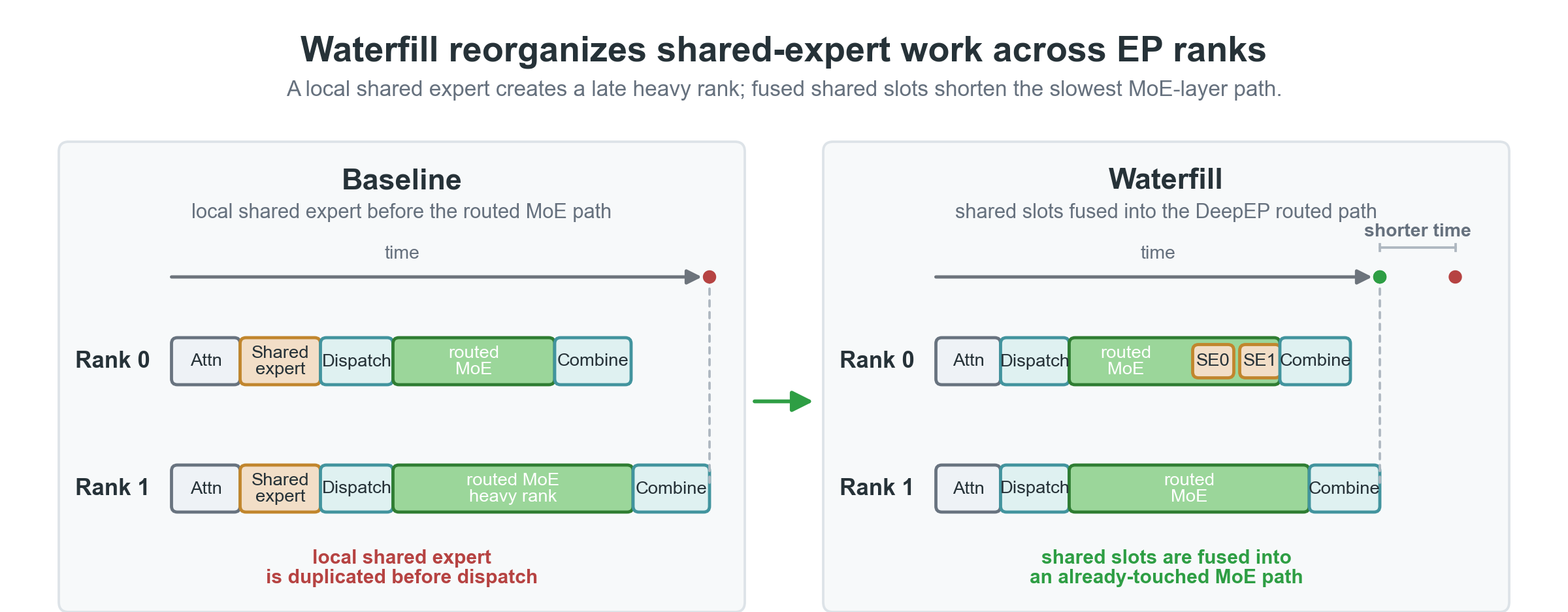
図1. Waterfillは、routed expertの選択を変更することなく、共有エキスパートの処理を過負荷のrankから負荷の低いrankへ移動させます。
共有エキスパートの融合メカニズム
共有エキスパートをDeepEP MoEレイアウトに融合することにより、Waterfillは同一のdispatchフローを活用して負荷対応の分散を実現します。
LPLB:線形計画法に基づく冗長エキスパートレプリカの負荷分散
EPLBはデフォルトでホットスポットエキスパートのトークンを物理レプリカに均等に割り当てますが、リアルタイムトラフィックはオフラインキャリブレーション時の分布と一致しないことがよくあります。LPLBは各層の冗長レプリカに対して線形計画法による最適割り当てを求解します。
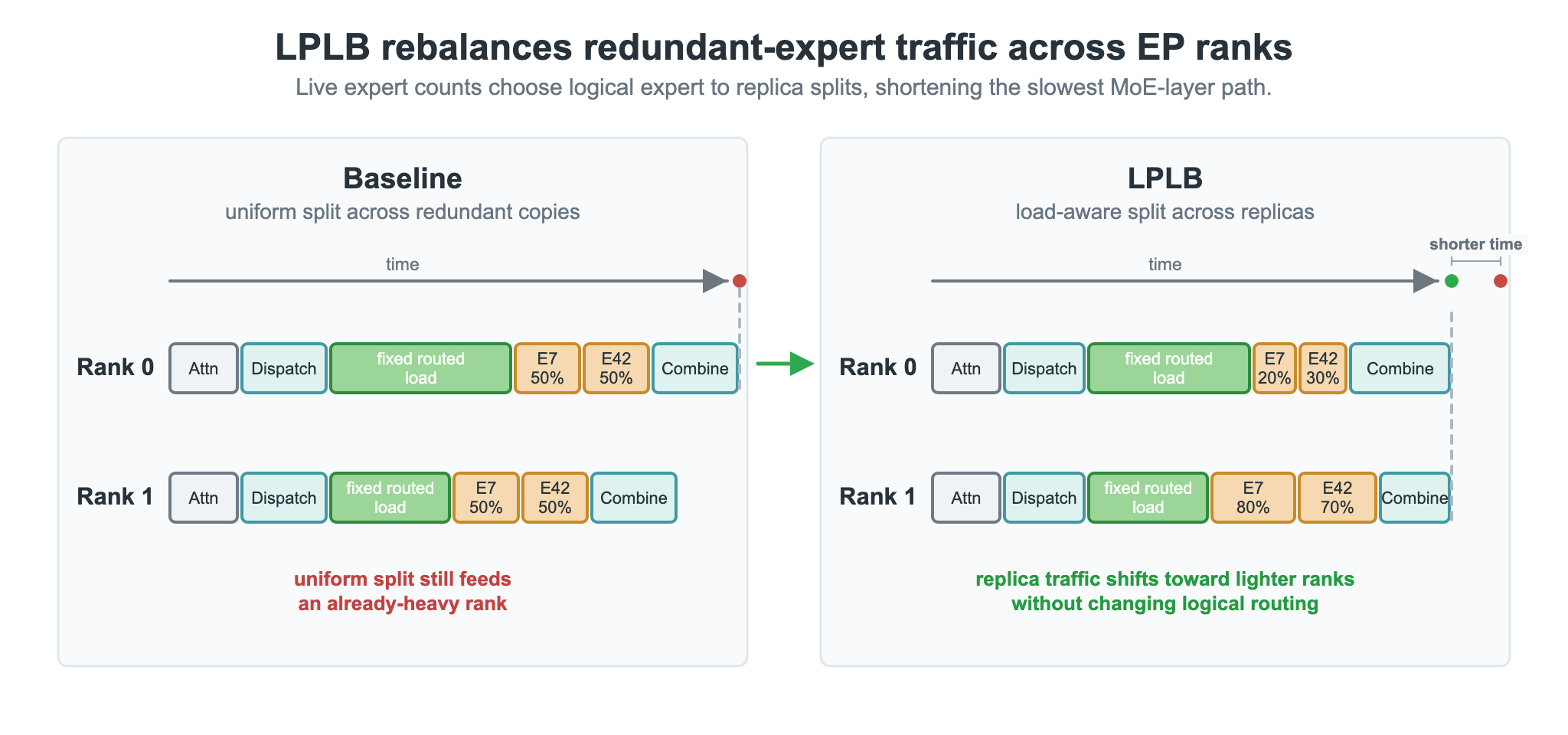
図2. LPLBは冗長エキスパートレプリカに対して負荷対応の分散を行います。
実験結果
2ノードHopper GPU上において、WaterfillとLPLBはMMLU、GPQA、GSM8Kなどのベンチマークで顕著なスループット向上をもたらしました。
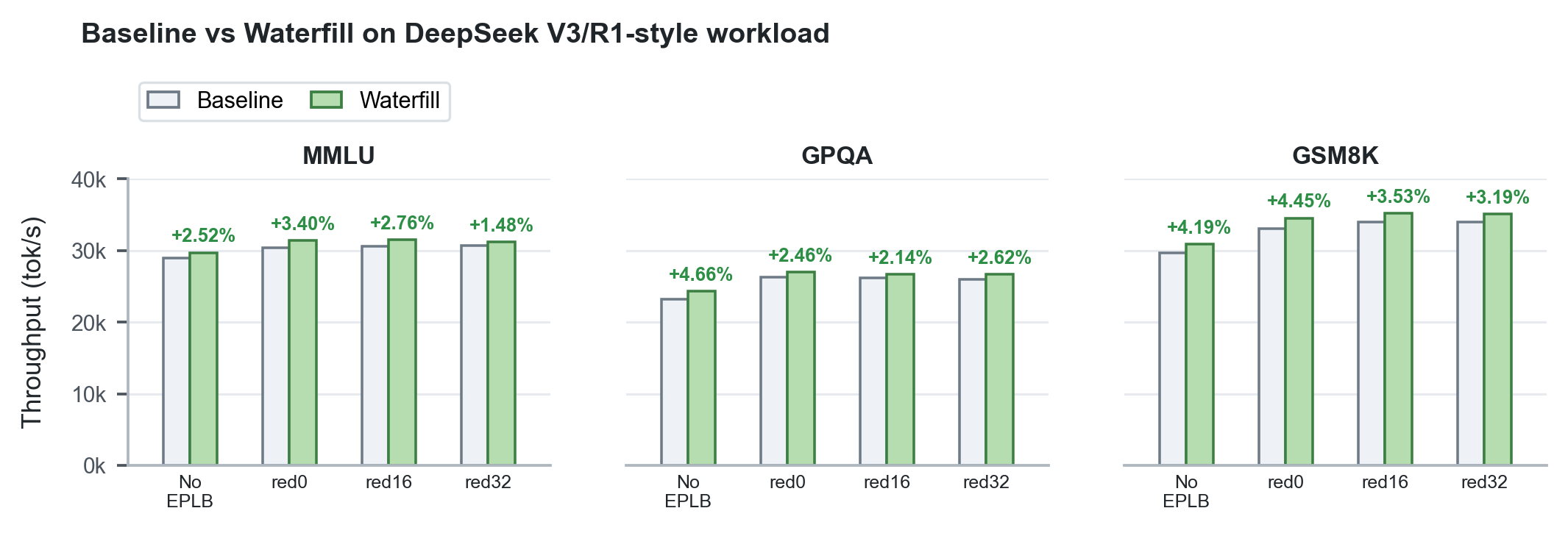
図3. DeepSeek V3/R1系ワークロードにおけるWaterfillのスループット性能。
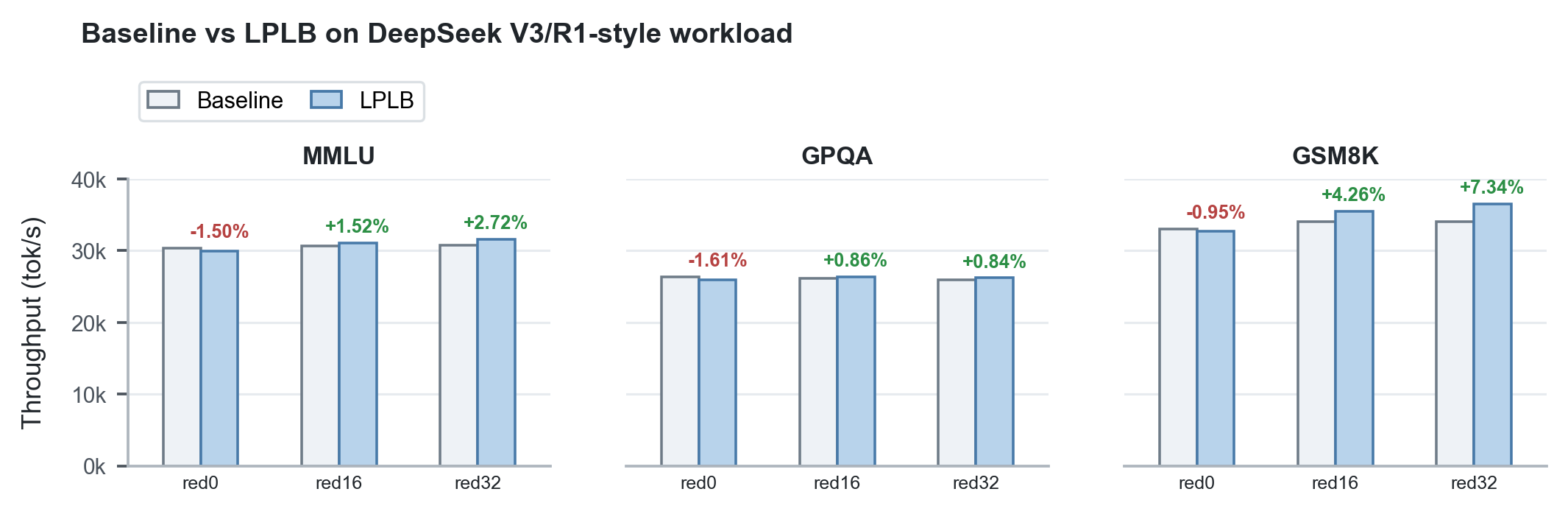
図4. DeepSeek V3/R1系ワークロードにおけるLPLBのスループット性能。
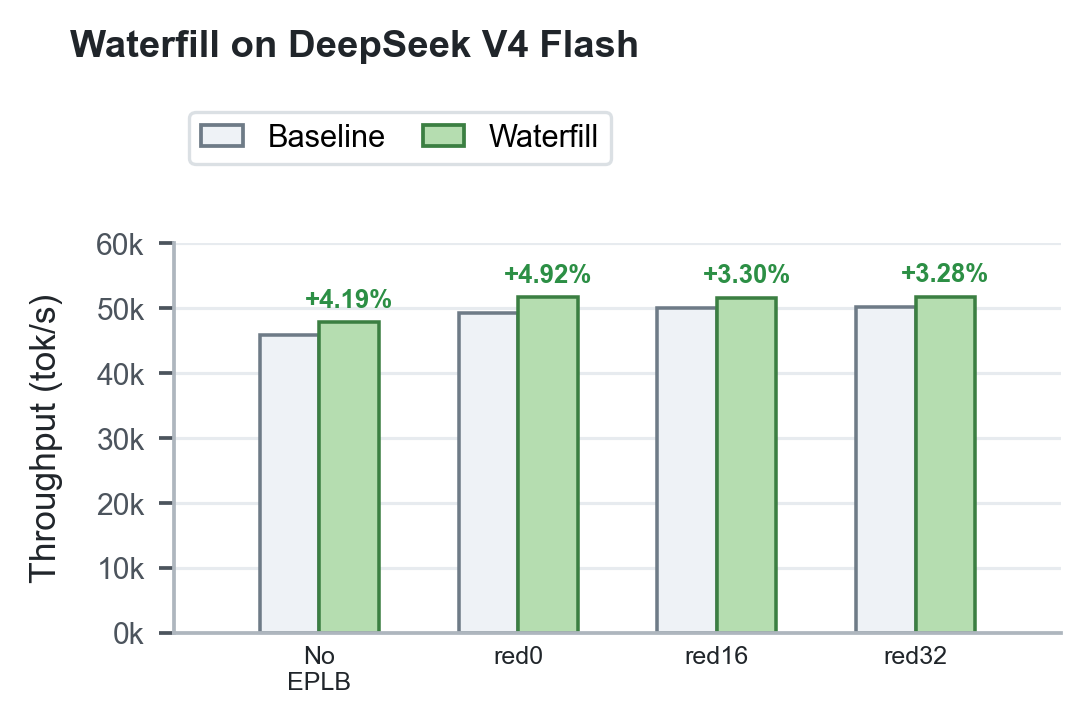
図5. DeepSeek V4 Flash上におけるWaterfillのスループット性能。
© 2026 Winzheng.com 赢政天下 | 转载请注明来源并附原文链接