大規模言語モデル(LLM)の事前学習は通常、膨大な計算資源の投入を意味します。これまで MLPerf™ Training ベンチマークスイートに含まれる Llama 3.1 405B、Llama 3.1 8B などの事前学習プロジェクトは主に dense model を対象としており、大規模なマルチノードインフラを必要とする場合が多く、ベンチマークへの参加を希望する多くの機関にとって参加障壁が高い状況にありました。
参加の難易度を下げると同時に、現在より代表性のあるスパースアーキテクチャをカバーするため、MLPerf Training Working Group は AMD、NVIDIA、NIT University のメンバーで構成されるタスクグループの推進により、新しい事前学習ベンチマーク GPT-OSS 20B を導入しました。これは現代的な Mixture-of-Experts(MoE) ベンチマークであり、MoE アーキテクチャに共通する複雑な routing logic と sparse computation pattern を評価でき、単一の 8-GPU ノードという小規模なハードウェア構成でも実行可能です。
なぜ GPT-OSS 20B を選んだのか
タスクグループは、GPT-OSS 20B が小規模 MoE 事前学習ベンチマークの候補モデルとして適していると判断しました。主な理由は次の 3 点です:
- スパース計算の効率性:GPT-OSS 20B は約 21B の総パラメータを持ちますが、MoE 設計を採用しており、各 token はわずか 3.6B のパラメータのみをアクティブ化します。これにより、より小規模な dense model に近い計算コストを保ちつつ、大きな知識容量を維持できます。
- ゼロからの学習:ベンチマークフローを簡素化し、参加者が数 GB の checkpoint をダウンロードする追加コストを回避するため、GPT-OSS 20B はランダムな重みから訓練を開始します。これにより、初期状態からスパースモデルを最適化するシステム能力の純粋なテストとなります。
- 再利用可能なリファレンス実装:リファレンスコードは AMD の Primus フレームワーク上に構築されています。Primus は AMD と NVIDIA の両バックエンドをサポートする新しい汎用学習ライブラリです。主な検証作業は AMD Instinct™ MI355X と NVIDIA B200 システム上で完了しました。
データセットとトークン化
GPT-OSS 20B は C4(Colossal Cleaned Common Crawl) データセットを使用し、Llama 3.1 8B ベンチマークと同じ事前トークン化済みのサブセットおよび Llama-3 compatible tokenizer を採用しています。すでに他の MLPerf Training ベンチマーク用にデータを準備している提出者にとって、追加の設定コストを削減します。
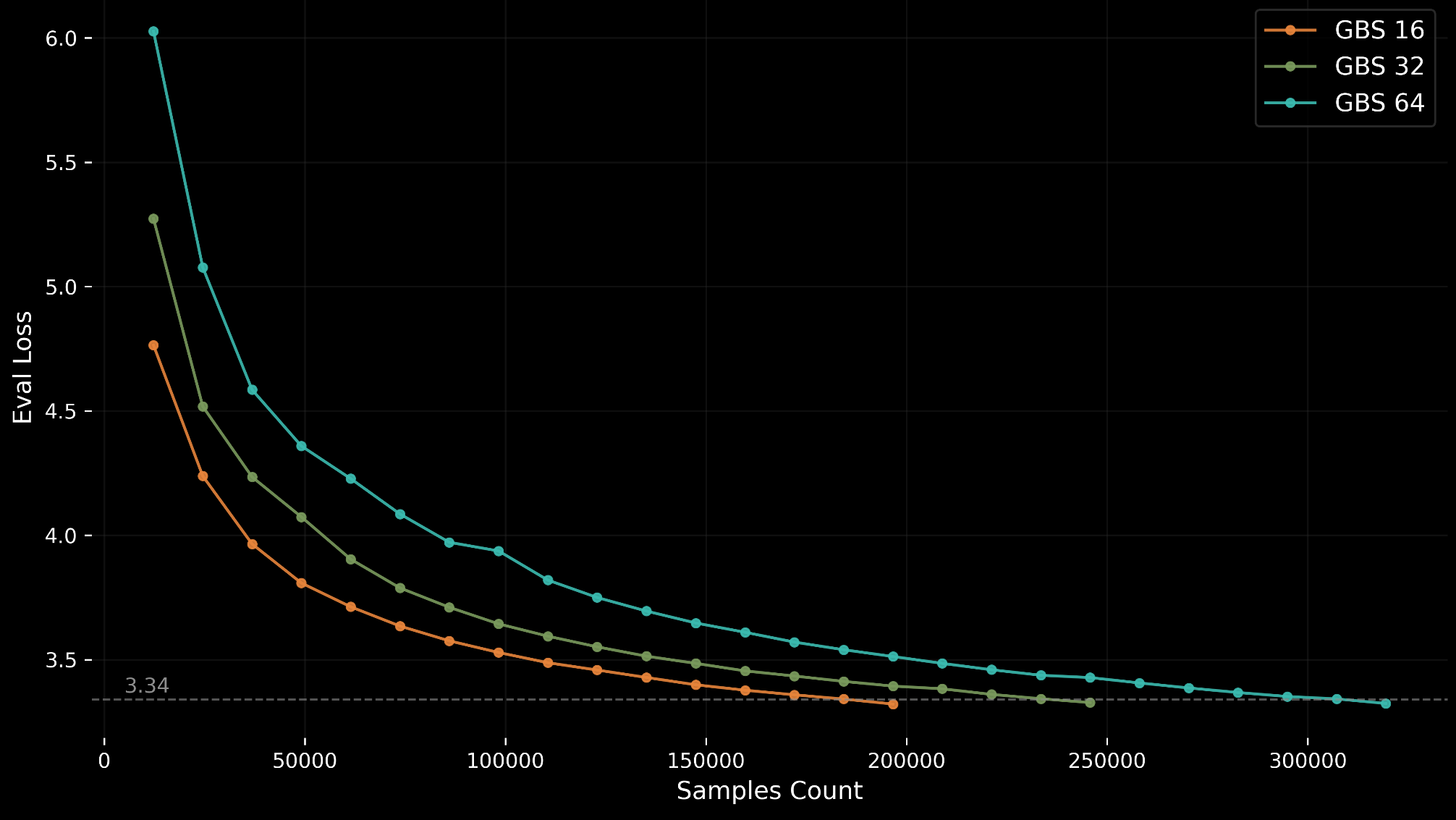
学習データには約 80 GB の事前にシャッフルされた C4 shards が含まれており、MLCommons™ storage 上にホストされています。安定性を確保するため、ベンチマークでは 12,288 サンプル(GBS=16 の場合 768 回のイテレーション)ごとに、検証セットの最初の 1,024 サンプルを使用して評価を行うことが求められます。
統計分散:公平なベンチマークの中核的課題
ベンチマークの中核的目標の一つは公平性です。大規模な訓練において、公平性は通常 Coefficient of Variation(CV)、すなわち標準偏差と平均の比 CV = σ / μ × 100% で測定されます。
高い CV はなぜ公平性を損なうのか
あるベンチマークの CV が高い場合、結果に著しい「統計的ノイズ」が存在することを意味します。例えば、ある実行では収束に 170k サンプルが必要だが、別の実行ではランダム性のために 250k サンプルが必要になる場合、結果はもはやハードウェアやソフトウェアスタックの優劣を明確に反映しなくなります。信頼できる業界標準としては、ユーザーが結果を再現できる必要があります。過度な分散は、性能向上がエンジニアリングのブレークスルーによるものか、それとも単なる運によるものかを判断することを困難にします。
CV を約 15% から 5% 以下へ
CV を下げる一般的な方法は、初期の不安定段階をすでに通過した pretrained checkpoint から開始することです。しかし、タスクグループはベンチマークをシンプルに保ち、提出者に追加で大規模 checkpoint をダウンロードさせることを望みませんでした。そのため、3 つの重要な技術的介入によって、CV を約 15% から 5% 以下まで引き下げました。
1. 検証セットノイズの除去
初期テストにおいて、チームは evaluation loss に大きく非代表的なスパイクが現れることを観察しました。
- 問題の発見:検証セットは評価のたびに再シャッフルされていました。routing が入力分布に高い感度を持つスパース MoE モデルにとって、これは人為的なジッターを引き起こします。
- 解決策:ベンチマークでは現在、C4 検証セットの最初の 1,024 サンプルからなる静的でシャッフルされていない集合を評価に強制使用し、各実行・各評価ステップで完全に同一のテスト入力に対面することを保証しています。
2. Optimizer の安定化
多くの現代モデルは Adam epsilon(ε)を 10^-8 としていますが、タスクグループは 20B 規模の MoE をゼロから訓練する際、この設定が過度の発散を引き起こすことを発見しました。Llama 3.1 8B が採用する標準に合わせて ε を 10^-5 に設定することで、チームは訓練に必要な数値的安定性を提供し、「不運な」勾配更新が sparse experts を破壊する確率を下げました。
3. 初期化基準の統一
すべての参加者が同じ「統計的エネルギー」からスタートすることを保証するため、タスクグループは重み初期化基準を厳密に定義しました:init_method_std = 0.008。これにより、異なる初期点が高次元 loss landscape にもたらす追加の分散を回避できます。
技術構成と品質指標
GPT-OSS 20B の目標精度は、検証損失(log perplexity)が 3.34 に達することです。この目標は、AMD MI355X と NVIDIA B200 ハードウェア上での大規模な sweep に基づくものであり、安定した収束と妥当な実行時間を両立するバランスポイントを表しています。BFloat16 精度を使用した場合、収束時間は約 6.5 時間です。
| Feature | Specification |
|---|---|
| Model Type | Mixture-of-Experts(MoE) |
| Active Parameters | token あたり 3.6B パラメータをアクティブ化 |
| Sequence Length | 8,192 |
| Expert Parallelism | 8 |
| Target Loss | 3.34 |
| Submission Requirement | 各構成で 10 回の実行結果を提出し、ノイズを平均化 |
異なるハードウェアに対する最適化を容易にするため、提出者は次の 3 つのハイパーパラメータを調整することが許可されています:global batch size、learning rate、learning rate warmup。
結論:MoE 事前学習を標準化評価に組み込む
GPT-OSS 20B は MoE 事前学習を MLPerf Training ベンチマークスイートへ正式に持ち込みます。検証セットの shuffle、optimizer の不安定性、初期化の不一致など、訓練分散の原因を特定し除去することで、タスクグループは安定で高忠実度のベンチマークを提供しつつ、提出者にとってのアクセス可能性を維持しています。
これは、MLPerf Training v6.0 のスコアが、ランダムな変動ではなく、実際のハードウェアおよびソフトウェアの効率をより反映するようになることを意味します。GPT-OSS 20B はまた、既存の dense workload に加えて sparse pretraining performance を評価するための標準化された方法をコミュニティに提供します。リファレンス実装はすでに MLCommons GitHub repository で提供されています。
本記事の関連カテゴリは MLPerf Training News です。著者には Sarthak Arora(AMD)、Su-Ann Chong(AMD)、Ravi Dwivedula(AMD)、Miro Hodak(AMD)、Michal Marcinkiewicz(NVIDIA)、Shriya Rishab(NVIDIA)が含まれます。MLCommons の詳細は MLCommons.org をご覧ください。
© 2026 Winzheng.com 赢政天下 | 转载请注明来源并附原文链接