SGLangとMilesチームは、NVIDIA Nemotron 3 UltraへのDay-0サポートの実現を発表し、長時間自律エージェントシステムの短いインタラクションから永続的ワークフローへの転換を後押しする。
エージェントAIシステムは、短いプロンプト・レスポンスモデルから、計画立案、ツール呼び出し、結果検証、エラーリカバリを行いながら長いタスクにわたって継続的に動作する永続的プロセスへと移行しつつある。これらのエージェントには、強力な推論能力、高速な推論処理、長いコンテキストの理解、および信頼性の高いツール使用能力が求められる。

Nemotron 3 Ultraの主要特性
Nemotron 3 UltraはNemotronファミリーにおけるオープンなフロンティア推論モデルであり、長時間自律エージェント向けに最適化されており、コーディング、ディープリサーチ、エンタープライズワークフロー、EDAなどのシナリオに適している。
- アーキテクチャ:ハイブリッドTransformer-MambaのMoEアーキテクチャ、総パラメータ数550B、アクティベーションパラメータ数55B、コンテキスト長は最大1Mトークン。
- 効率性:NVFP4およびBF16の高スループット推論をサポートし、NVFP4チェックポイントはBlackwell GPU上で動作可能。
- トレーニング:マルチ環境強化学習によるポストトレーニングを採用し、エージェント動作を強化。
- デプロイ:オープンな重み、データ、レシピを提供し、マルチGPU構成をサポート。
クイックスタートとデプロイ
ユーザーはSGLang Dockerコンテナを使用して迅速にデプロイできる。公式cookbookまたはNVIDIA Brev launchableの使用を推奨。
サービス起動コマンドは8x B200構成をサポートしており、OpenAI互換クライアントから呼び出してreasoning_contentと生成結果を取得することができる。
長時間エージェントワークロード向けの設計
Nemotron 3 Ultraは主要なエージェントフレームワークと統合されており、GRPO RLトレーニングをサポートする。主要なイノベーションには以下が含まれる:
- エージェントharnessに対するポストトレーニング
- Hybrid Mamba-Transformerアーキテクチャ
- Latent MoEおよびMulti-Token Prediction
- NVFP4精度のクロスアーキテクチャ互換性
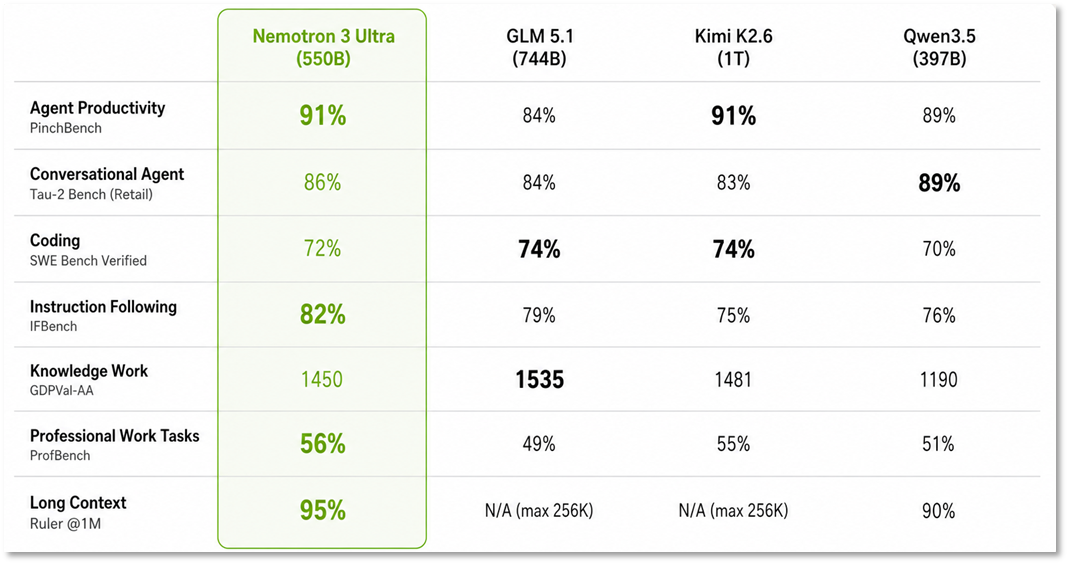
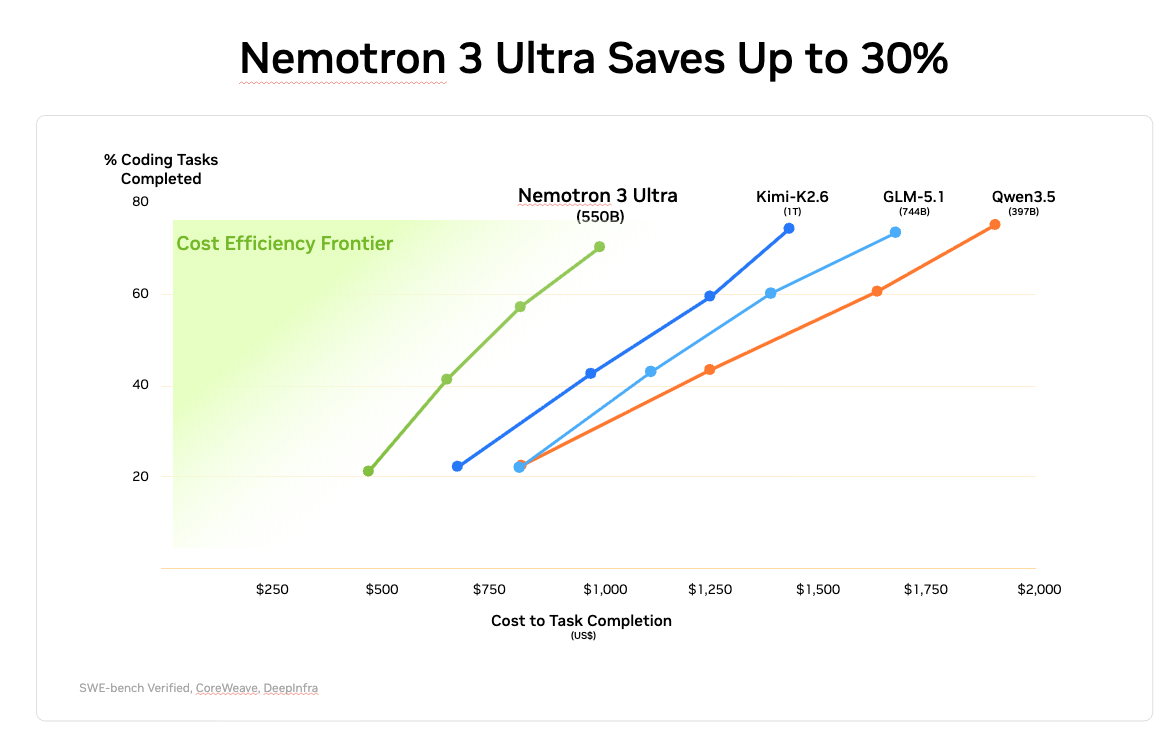
エージェント生産性、指示遵守、長いコンテキストタスクにおいてオープンソースモデルをリードし、コストを最大30%削減できる。
Milesによる強化学習サポート
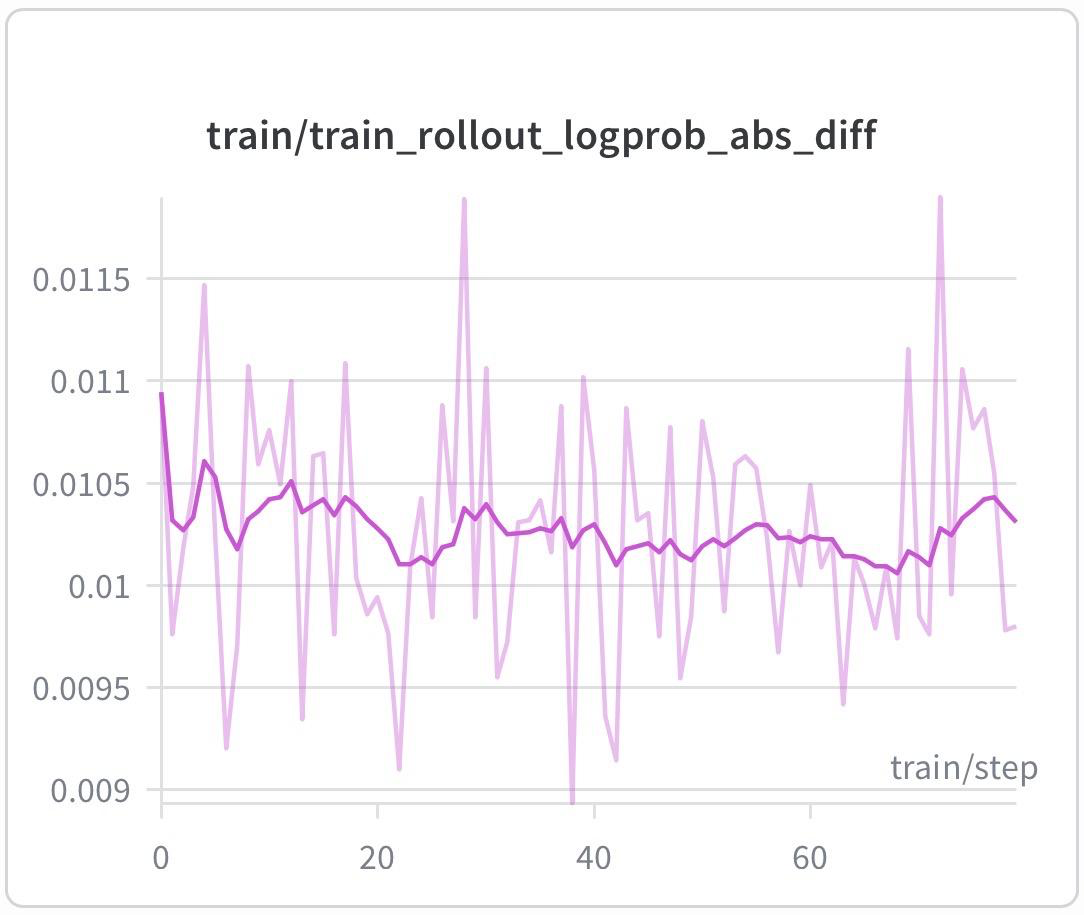
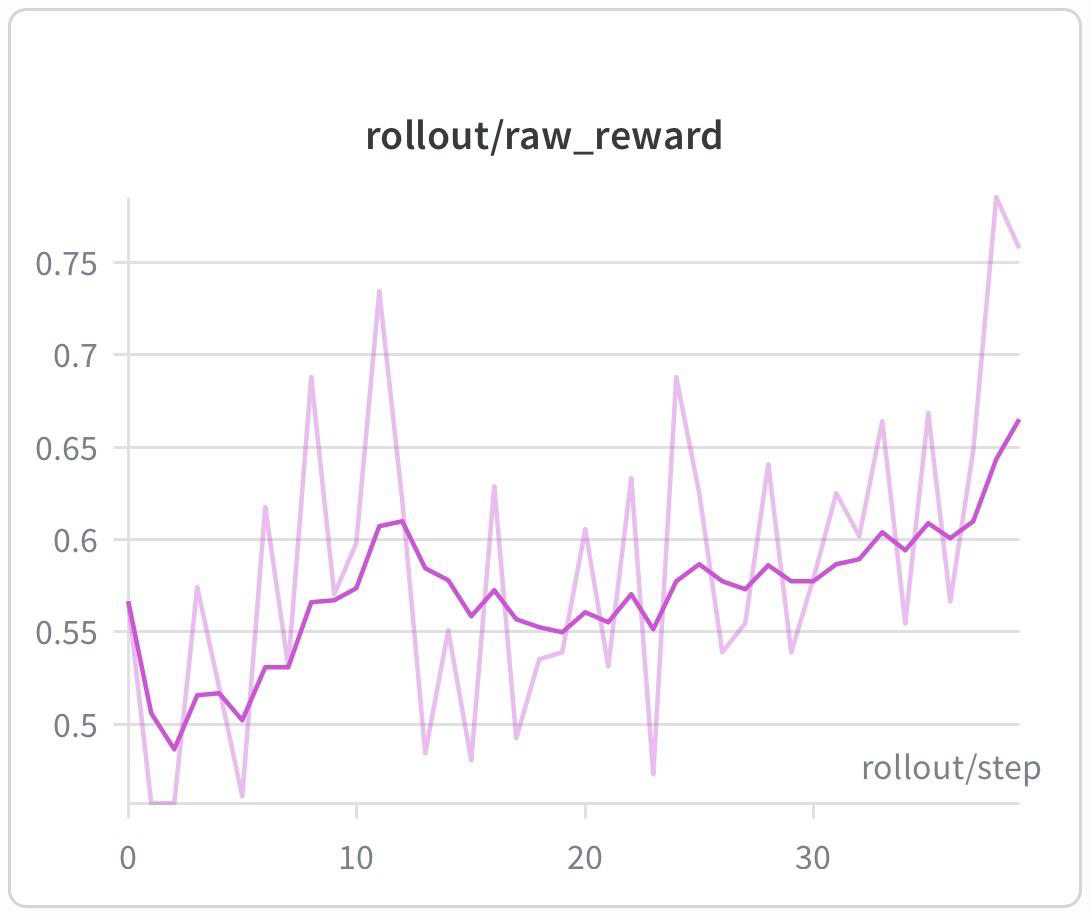
MilesフレームワークはすでにH200 GPU 128枚上でGRPO RLトレーニングを検証済みであり、TP/PP/EP/DP並列戦略とDP attentionをサポートしている。トレーニングとrolloutのlog-prob差異は0.01前後に保たれており、pipelineが高度にon-policyであることが証明されている。
© 2026 Winzheng.com 赢政天下 | 转载请注明来源并附原文链接