MLCommonsは本日、MLPerf Training v6.0ベンチマークテストスイートの最新結果を発表した。今回新たに追加された2つのベンチマークと多数の提出結果は、AIエコシステムの急速な変革を浮き彫りにしている。
「コミュニティにとって非常に刺激的な瞬間です」と、MLPerf Trainingワーキンググループの共同議長Shriya Rishabhは述べた。「AIモデルトレーニングのベストプラクティスが収束しつつある一方で、基盤となるフレームワークやシステムの技術的多様性も増しています。」
新ベンチマークがスパース計算を重視
MLPerf Trainingベンチマークは、完全なシステムテストを通じてモデル・ソフトウェア・ハードウェアを網羅する。v6.0ではDeepSeek V3とGPT-OSS 20Bの2つのベンチマークが新たに追加され、いずれもMixture-of-Experts(MoE)アーキテクチャを採用しており、業界のスパース計算への移行を体現している。
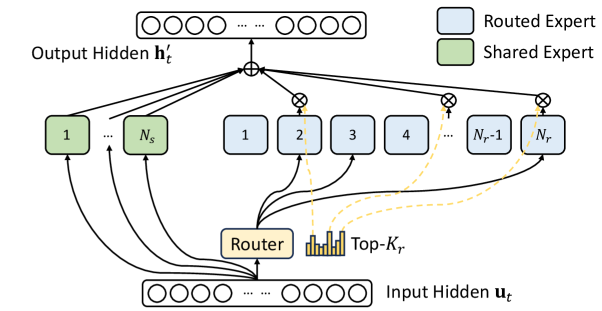
DeepSeek V3は総パラメータ数6710億、1トークンあたりのアクティブパラメータ数370億を誇り、現在のスイートの中で最大規模のベンチマークである。一方、GPT-OSS 20Bは規模が小さく、総パラメータ数210億、1トークンあたりのアクティブパラメータ数36億で、単一の8-GPUノードによるテストに適している。
提出システムの多様性が過去最高を更新
v6.0では合計95の固有システムが提出され、13種類のハードウェアアクセラレータ、19種類のホストプロセッサが使用され、60%がマルチノードシステムである。クラウドシステムの数はv5.1と比較して2倍以上に増加した。
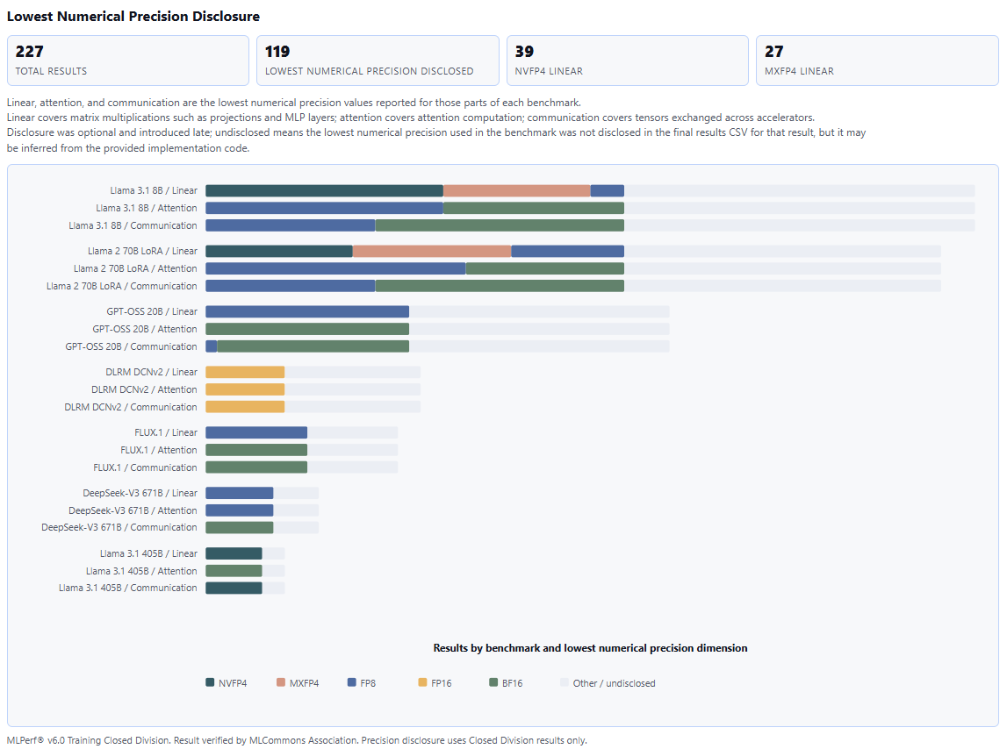
提出者は複数のFP4精度スキームを使用しており、低精度トレーニングに対する業界の探求が際立っている。MLPerfの精度閾値要件は、異なる実装間の性能差を業界が明確に比較する上で役立っている。
24機関が参加しエコシステムが継続拡大
今回の結果はAMD、NVIDIA、Google、Azureなど24機関から提出され、そのうちInventec、Netweb Technologies India LTD、TTA、Vultrが初めての提出者となった。MLCommonsはさらに多くの組織がワーキンググループに参加し、ベンチマークの改善に共同で取り組むことを歓迎している。
完全な結果はMLCommons公式サイトで確認できる。
© 2026 Winzheng.com 赢政天下 | 转载请注明来源并附原文链接