SGLang RLチームはKimi K2に着想を得て、INT4 Quantization-Aware Training(QAT)のエンドツーエンドソリューションを実現した。トレーニング段階のfake quantizationと推論段階のW4A16実量化を組み合わせることで、BF16フル精度と同等のトレーニング・推論一貫性と安定性を実現している。
はじめに
近年、SGLang RLチームはRLトレーニングの安定性・効率・応用シーンにおいて複数の進展を達成した。INT4 QATエンドツーエンドトレーニング、統合マルチターンVLM/LLMトレーニング、Rollout Router Replay、FP8エンドツーエンドトレーニング、RLにおけるSpeculative Decodingなどが含まれる。これを基盤として、チームはslimeフレームワーク上で完全なINT4 QATソリューションを再現・デプロイした。
本ソリューションはKimiチームによるK2-ThinkingのW4A16 QAT実践を深く参考にしており、安定性と性能を両立したオープンソースのリファレンス実装を提供することを目的としている。
技術概要
全体パイプライン
チームはトレーニングから推論までの完全なINT4 QATクローズドループを実現した。概要は以下の図に示す通りである:
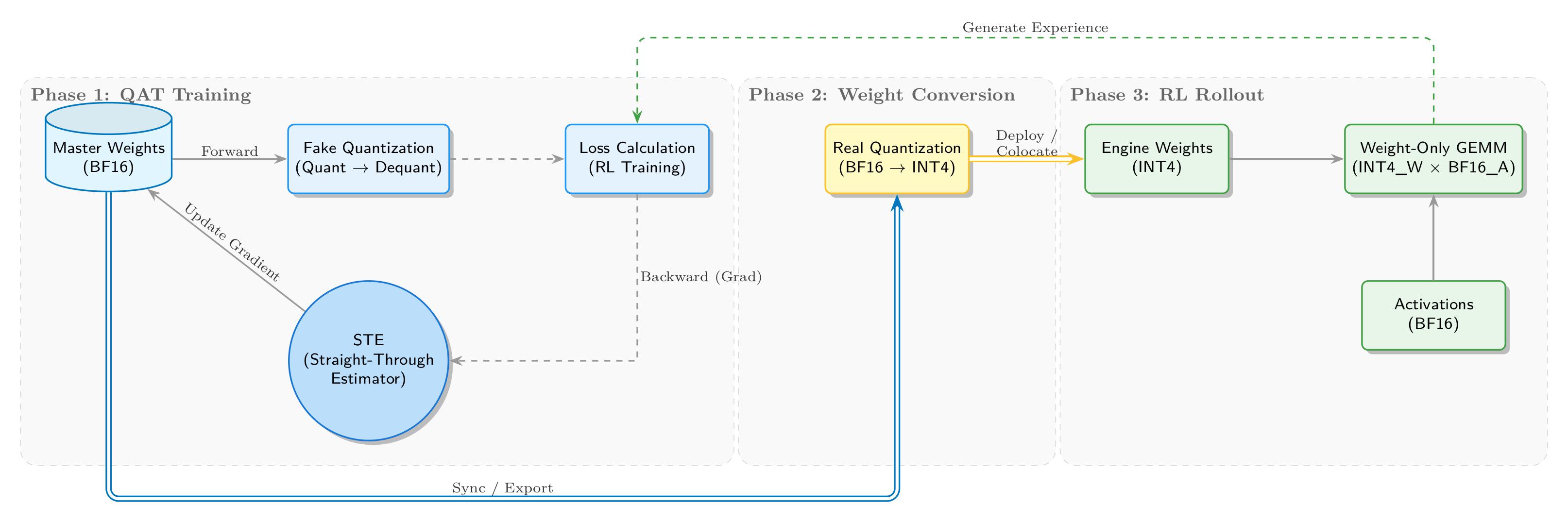
トレーニング段階ではBF16マスターウェイトを維持し、フォワードパスでfake quantizationにより量化ノイズを注入する。バックワードパスではSTE(Straight-Through Estimator)を用いて非微分可能問題を回避する。重み変換段階ではINT4フォーマットにエクスポートして推論エンジンで使用し、RLロールアウト段階ではSGLangがW4A16推論を実行することで、自己整合的なクローズドループを形成する。
主要な設計方針
量化フォーマットにはINT4(W4A16)を採用し、ハードウェアサポートと成熟したMarlinカーネルエコシステムを両立している。トレーニングにはfake quantization+STEの定番の組み合わせを用い、低精度トレーニングにおける収束安定性を最大化している。
トレーニング側:Megatron-LMへのFake Quantization統合
Fake QuantizationとSTEの実装
コアとなる目標は、トレーニング中にリアルタイムで量化誤差をシミュレートし、モデルを低精度表現に適応させることである。実装はmegatron/core/extensions/transformer_engine.py内の_FakeInt4QuantizationSTEクラスに位置し、per-group最大絶対値に基づく動的量化を行い、INT4範囲をシミュレートしてBF16に誤差を注入する。バックワードパスではSTEにより勾配のストレートスルーを維持する。
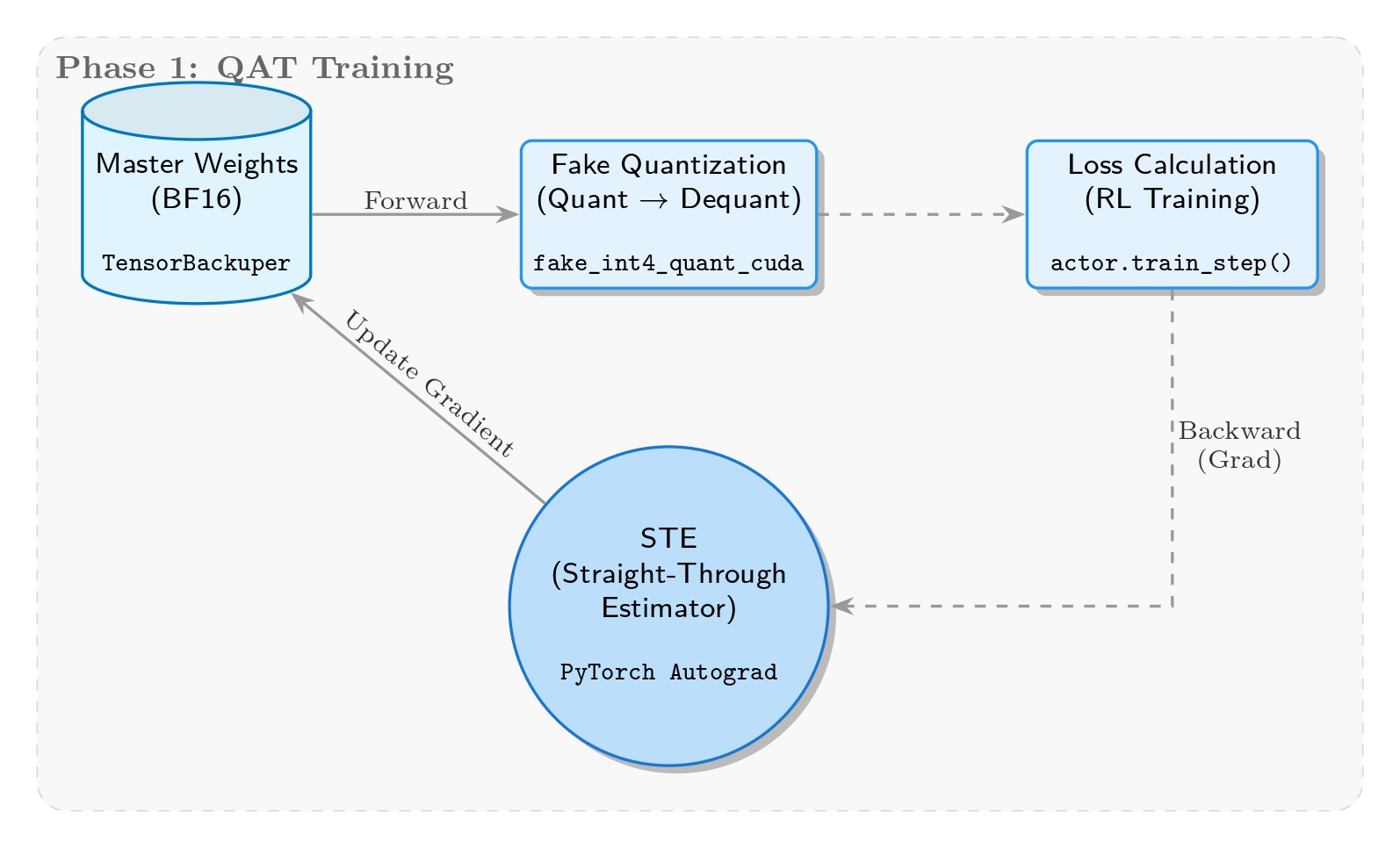
Fake Quantizationアブレーション実験
QATの必要性を検証するため、2種類の非対称シナリオによるアブレーション実験を設計した:QAT INT4トレーニング+BF16ロールアウト、およびQAT無しで直接INT4ロールアウトを行うケースである。トレーニングと推論の不一致性はLogprob Abs Diffで測定した。
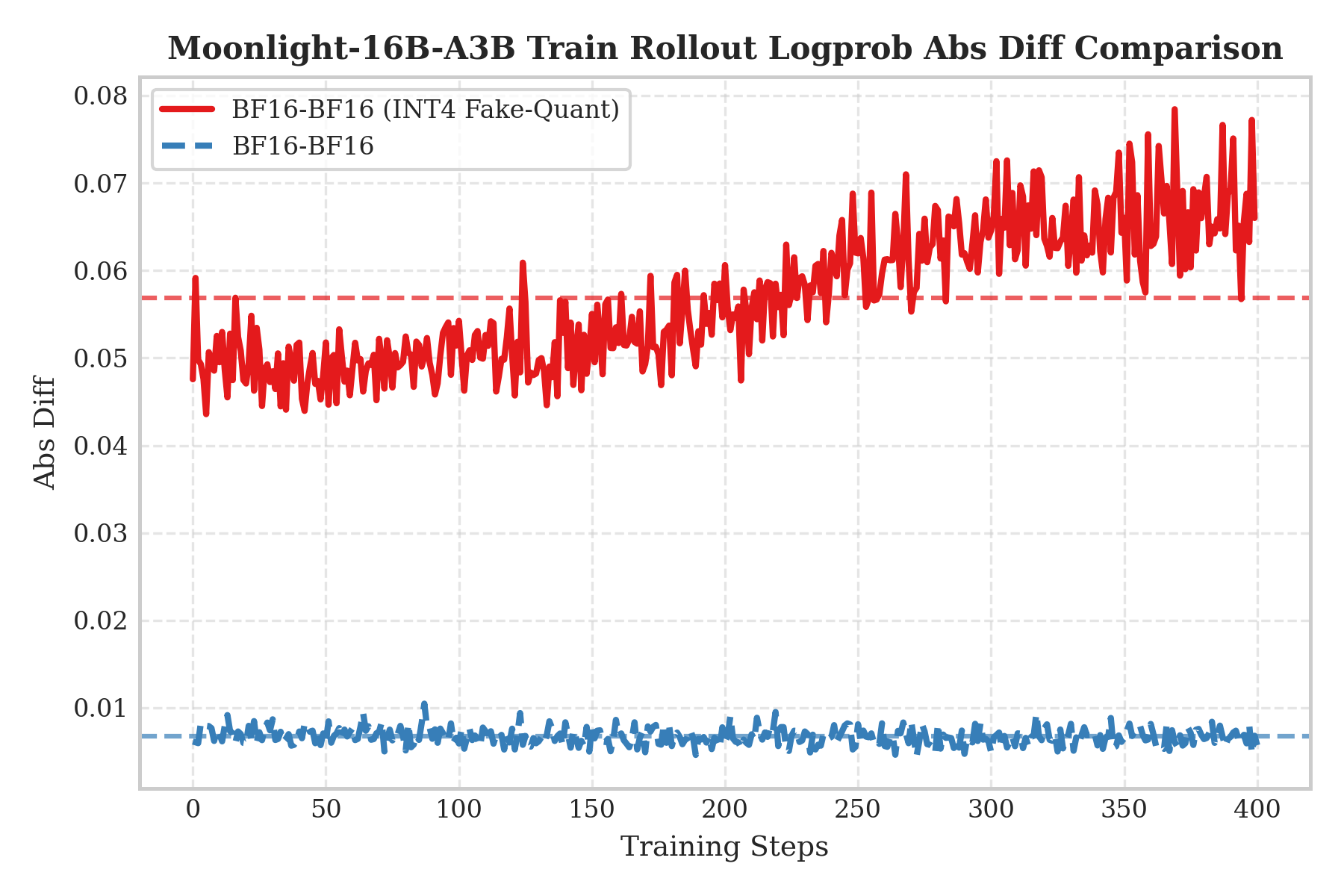
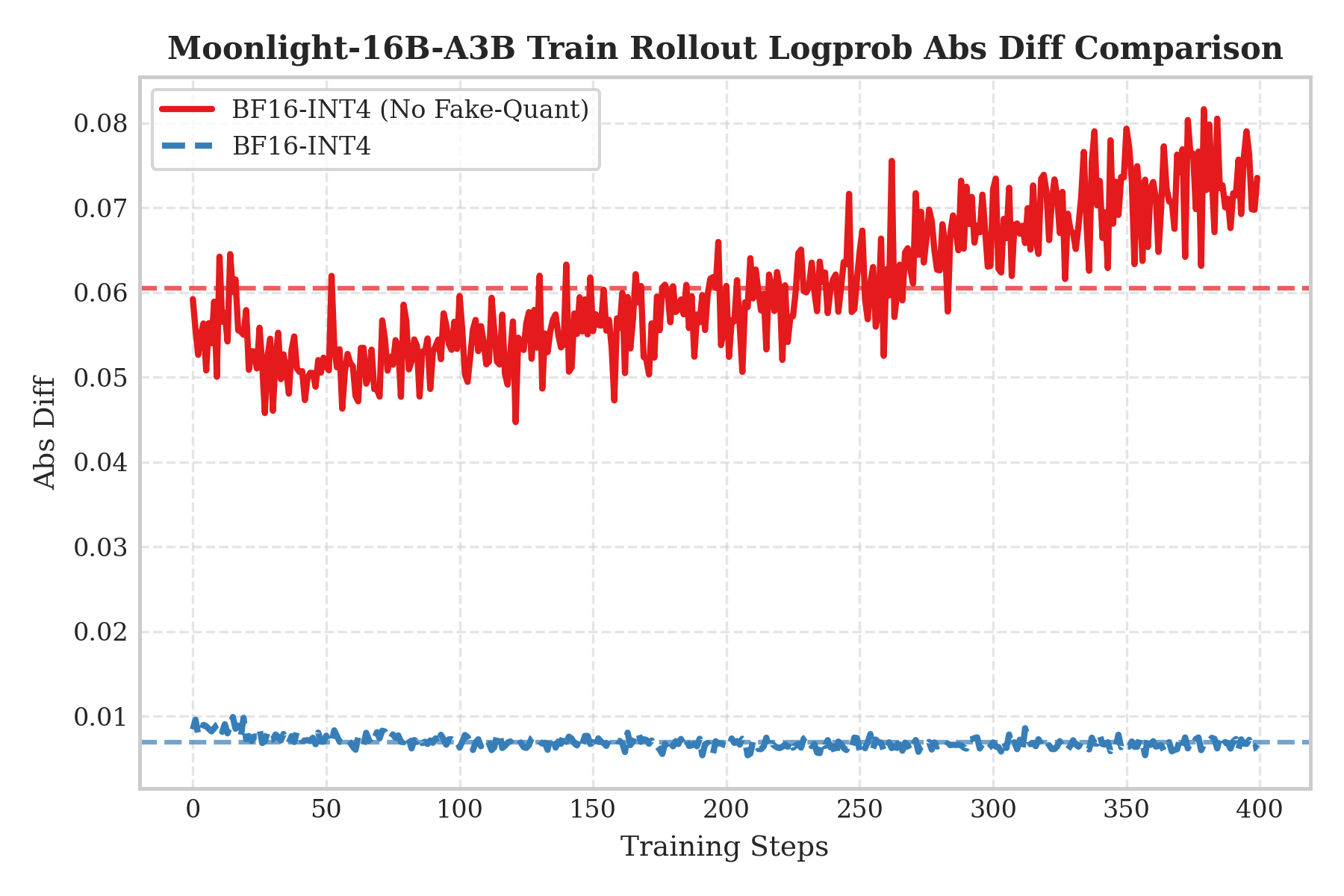
実験結果から、QATトレーニング後の重みはINT4ノイズに適応しており、量化を除去すると分布シフトが生じることが確認された。一方、QAT無しで直接INT4ロールアウトを行った場合は誤差が著しく大きくなった。
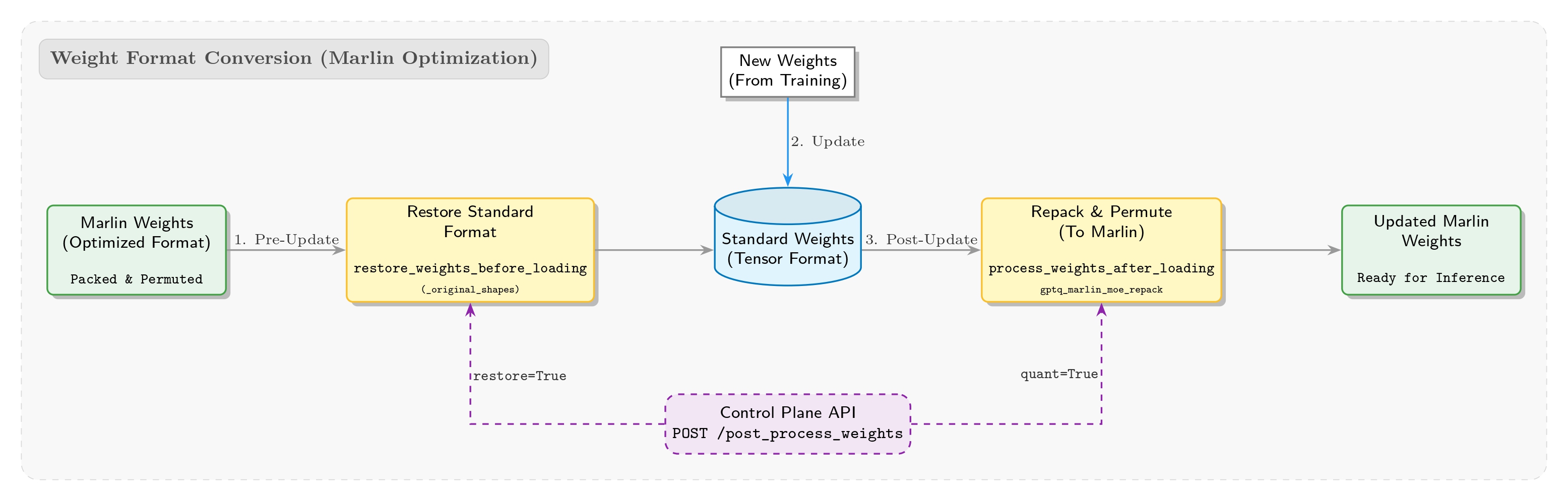
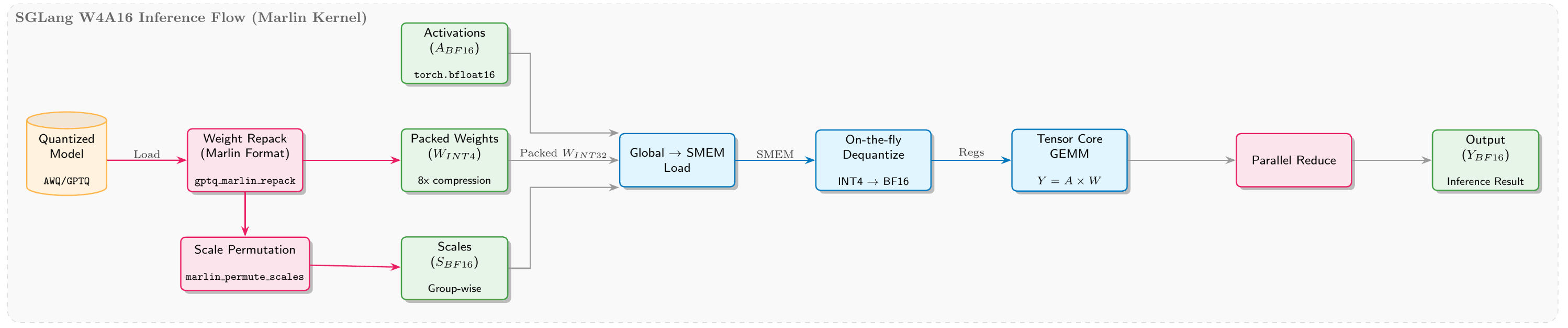
推論側:SGLang W4A16パイプライン
SGLang側の重み処理パイプラインは以下の通りである:

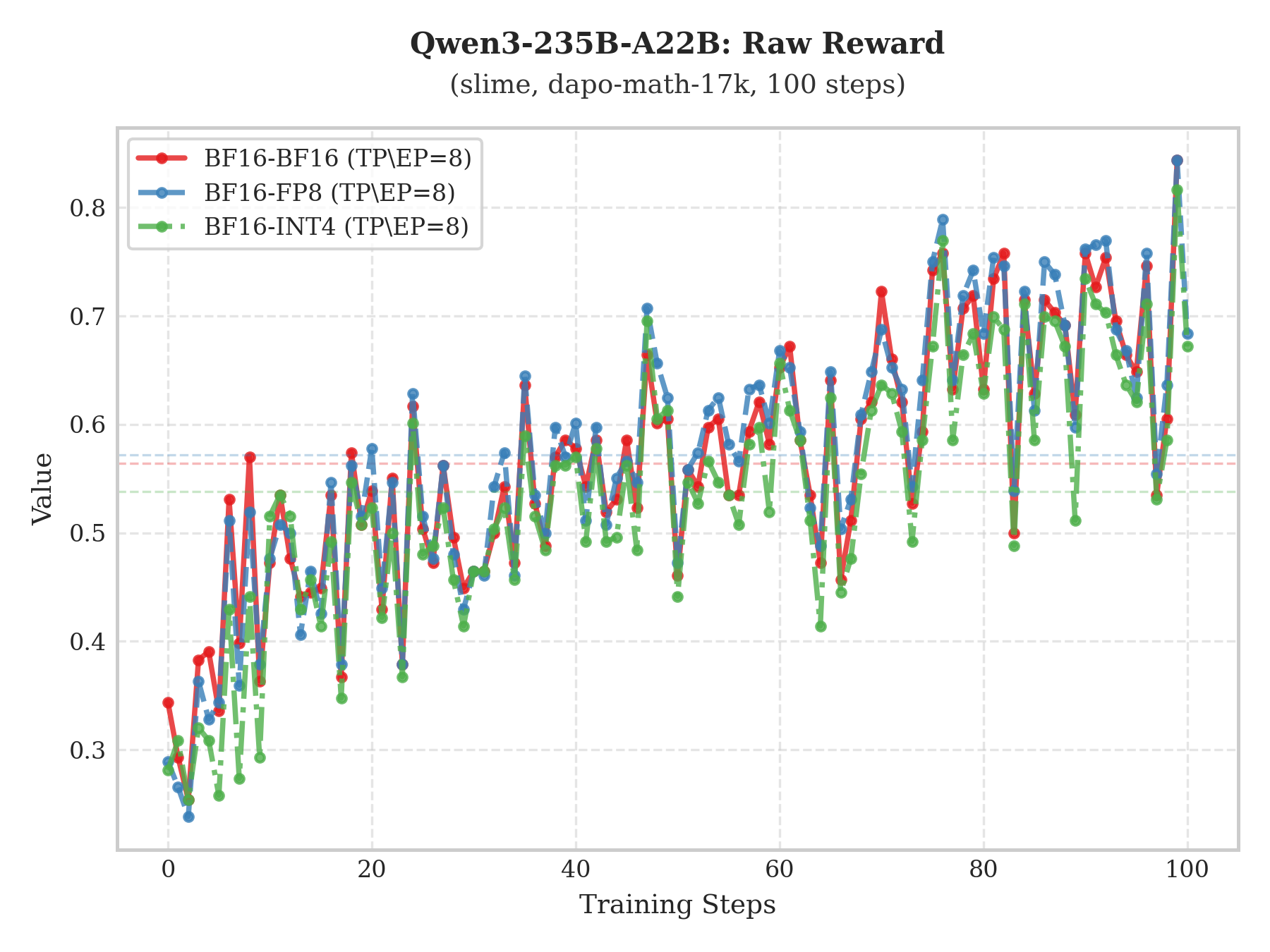
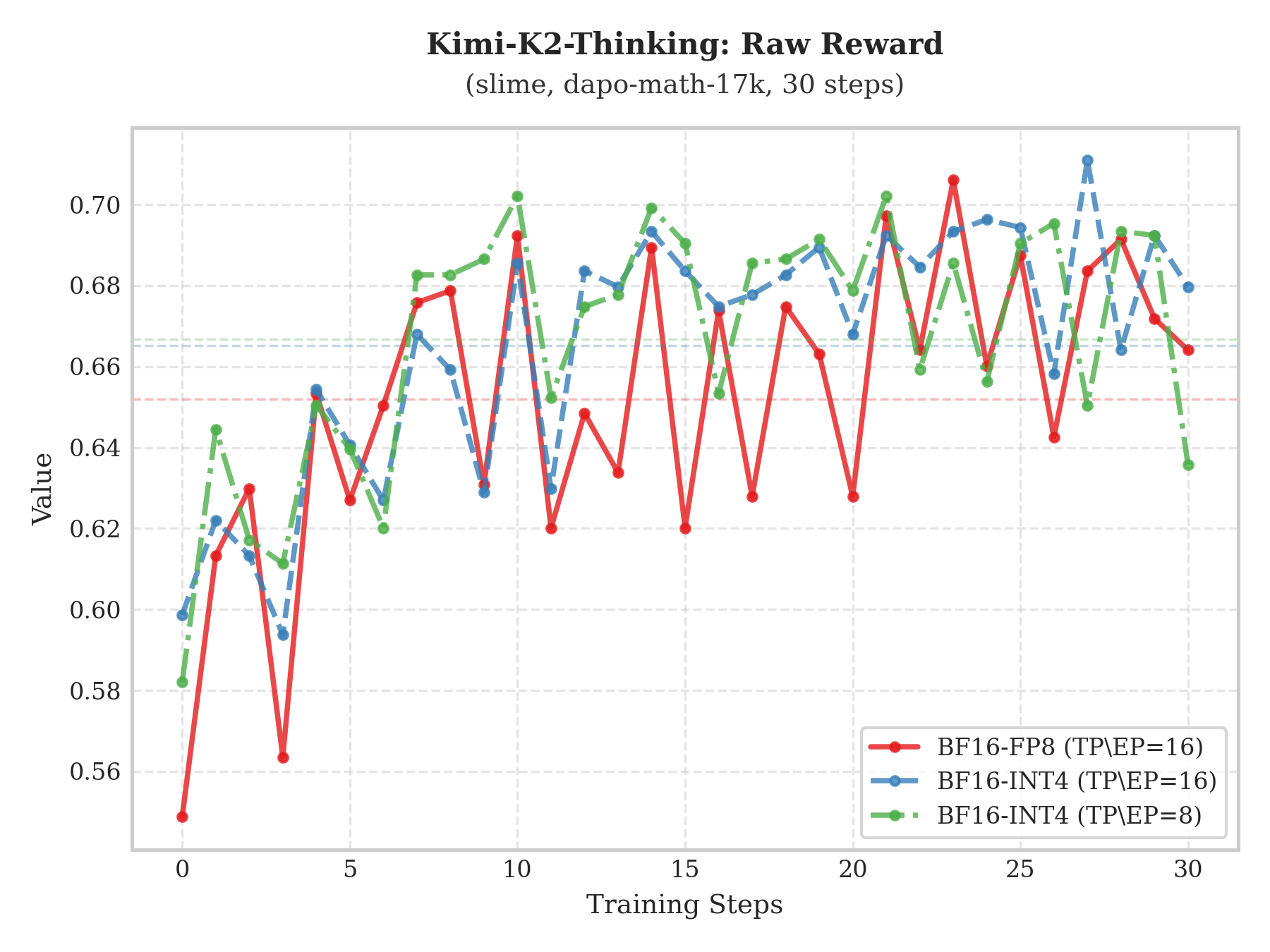
実験結果
複数モデルにおけるRaw-RewardおよびAIME評価の比較により、INT4 QATソリューションはBF16ベースラインと高度に一致することが示された。
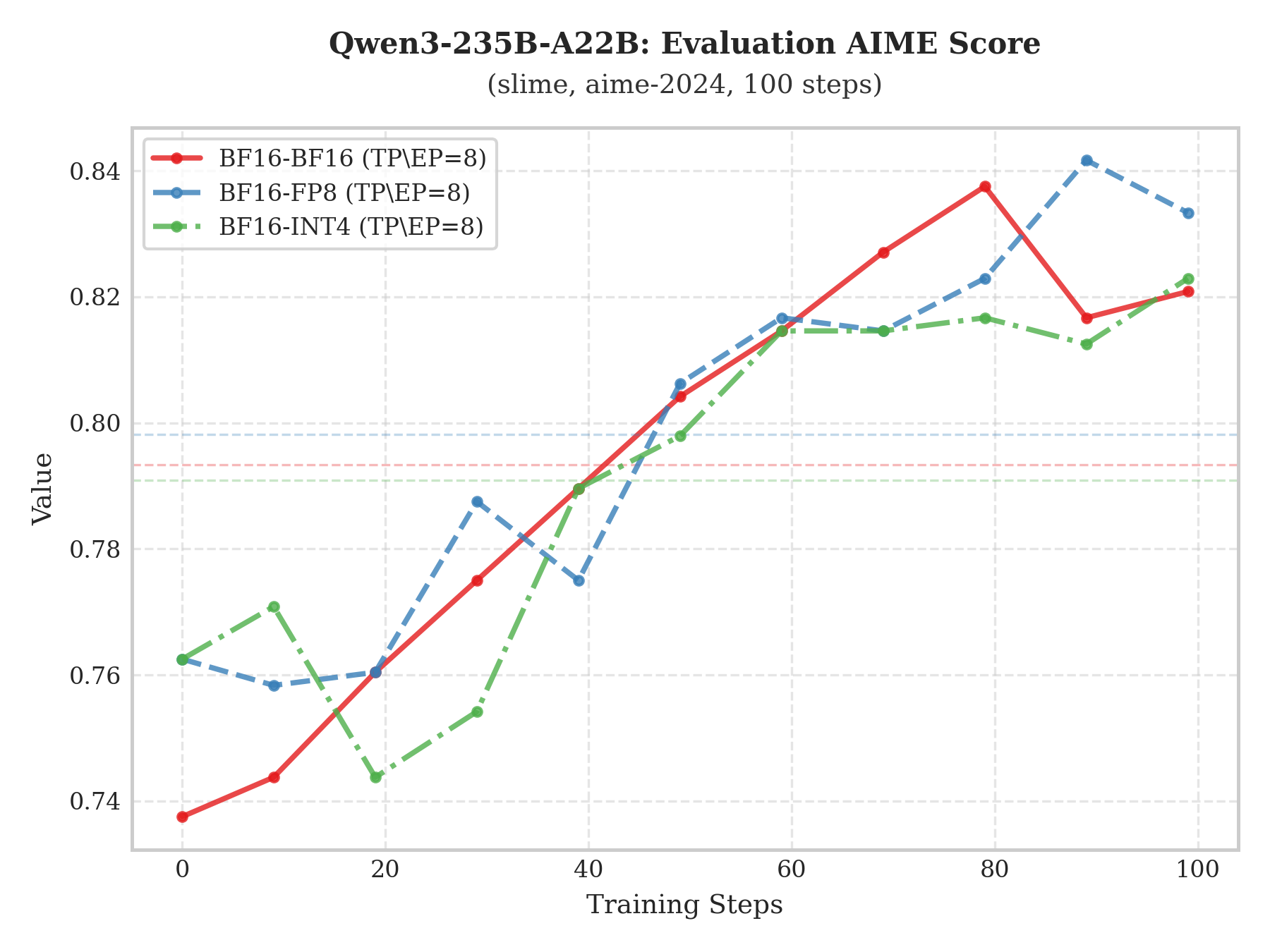
本プロジェクトはSGLang RLチーム、InfiXAIチームなどが共同で完成させたものであり、関連機能はslimeおよびMilesコミュニティにも同期されている。
© 2026 Winzheng.com 赢政天下 | 转载请注明来源并附原文链接