我々はSGLangのRLワークロード向けに、従来のNCCLブロードキャスト方式を補完するものとして、RDMAベースのポイントツーポイント重み更新メカニズムを導入しました。このメカニズムは主流のすべてのオープンソースモデルと互換性があります。送信元のCPU engine replicaとMooncake TransferEngineで実現されるP2P RDMA transfersを活用することで、1TパラメータのKimi-K2モデルの重み転送時間を7倍高速化し(53秒から7.2秒へ)、各トレーニングrankごとに32GのCPUメモリを追加消費するだけで実現しました。これらの最適化はネットワーク冗長性を最小化し、推論サーバーが大幅に速くrollout操作を再開できるようにします。
背景
NVIDIAのNCCLは、ハードウェアトポロジを自動検出してデータフローを協調させること(リング型やツリー型アルゴリズムなど)により、all-gatherやbroadcastのようなプリミティブを最適化します。PyTorch FSDP、DeepSpeed、Megatron-LMのデフォルト通信バックエンドとして、対称的なトレーニングの業界標準となっています。しかし、集合的セマンティクスに依存しており、すべてのrankが同時に同じ操作を呼び出し、データ形状を一致させることが要求されます。負荷が均衡している場合は効率的ですが、この設計は動的な環境では負担となります:NCCLはロックステップで動作するため、単一の受信側の「スロースタート」がグループ全体をハングさせ、リソースをアイドル状態にしてしまう可能性があります。
RDMA(Remote Direct Memory Access)は、リモートCPUとカーネルネットワークスタックを完全にバイパスして、マシンがリモートメモリに直接アクセスできるようにします。その効率性は3つの中核的特性に由来します:
- Kernel Bypass:アプリケーションがNICに直接ワークリクエストを送信し、コストの高いシステムコールとコンテキストスイッチを排除します。
- Zero Copy:登録されたメモリ領域とネットワーク間でDMAによってデータが直接移動し、カーネルバッファでの中間コピーを回避します。
- One-Sided Operations:RDMA READ/WRITE操作は片側から開始され、リモート側のアクティブなCPU参加や割り込み処理は不要です。
NCCLのグローバル同期とは異なり、RDMAは任意の2つのエンドポイントが独立して並行通信できるため、高速重み転送の理想的な基盤となります。これがまさに本記事で説明するP2P重み更新メカニズムが、Mooncake TransferEngineで実現されるRDMA転送を基盤として活用する理由です。
RL重み転送問題:大規模分散RLトレーニングにおいて、トレーナーから推論エンジンへの重み転送はクリティカルパス操作です:転送中、RLトレーニング全体が停滞し、トレーナーと推論ともに進捗せず、リソースは通常アイドル状態になります。モデルが大きくなるにつれて、この転送は複数のホストとラックに拡張する必要があり、すべてが限られた帯域幅を奪い合います。既存のNCCLベースのオープンソースソリューション(miles/slime/verlなど)は、単一のソースrankのbroadcastプリミティブに依存しており、これがすぐに転送のボトルネックとなります。
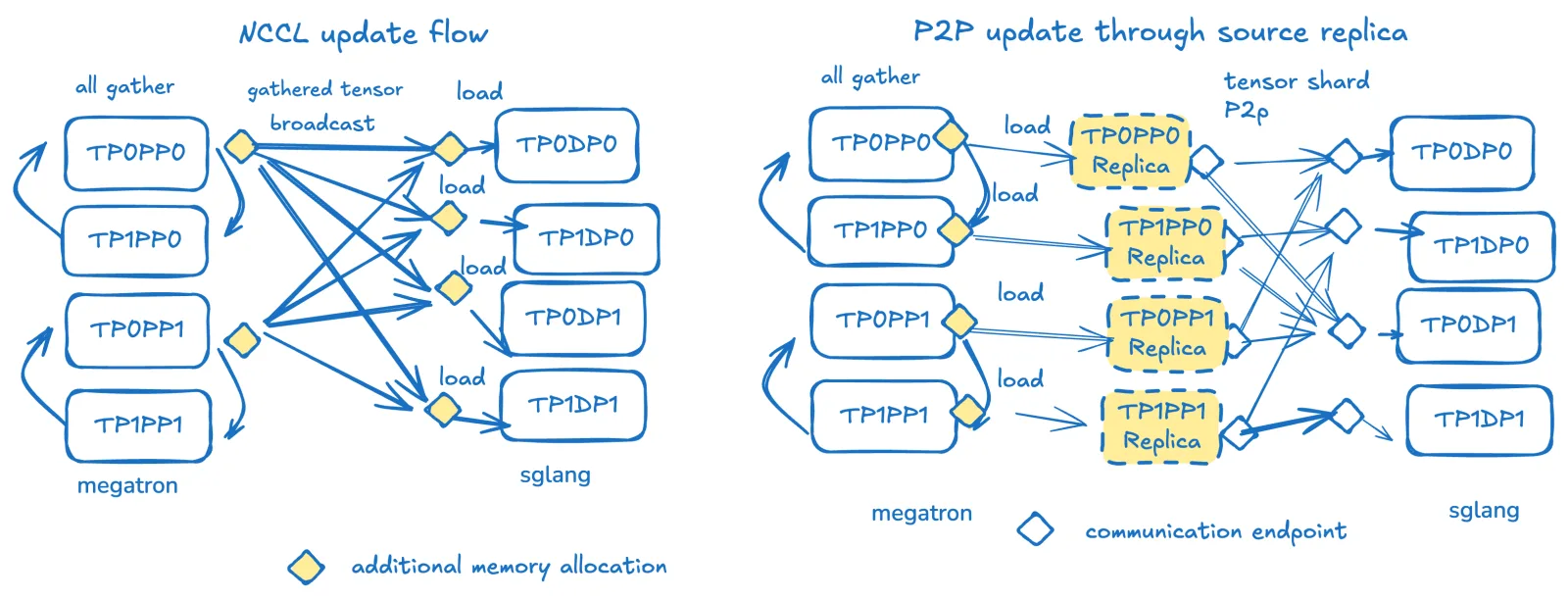
左図:miles分散トレーニング/推論RLにおける現在の重み転送ワークフロー。送信元側では、すべてのノードがTPおよびEP次元でall gatherに参加し、各PP rankの先頭rankが集約テンソルを取得します。先頭rankはupdate_weight_from_distributed APIを通じて分散更新グループに参加し、完全な重みを各エンジンrankにブロードキャストし、ローカルrankが対応するシャードをロードします。このプロセスは各PP rankおよび各バケット化された重みテンソルに対して実行されます。
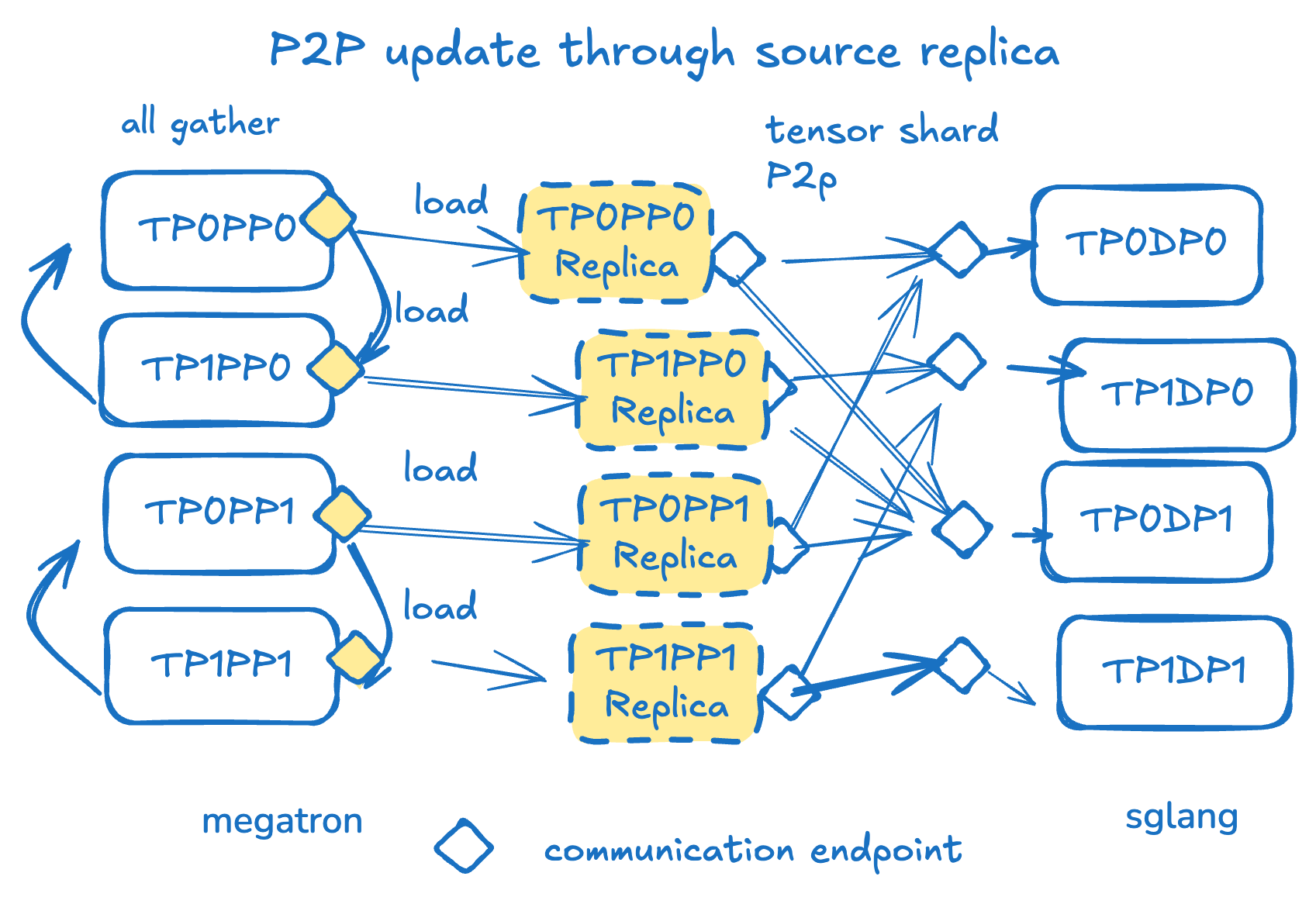
右図:P2P更新設計は送信元側のエンジンレプリカを仲介として依存します。バケット化された重み更新の最初のall gatherステップはmilesと同じです。しかしその後、重みはCPUメモリ上のローカルsglangエンジンシャードレプリカにロードされ、レプリカが正しい形状でsglangに重みを送信します。各レプリカの重みは複数のsglang rankに送信できます。各ターゲットsglang TP rankは、各PP送信元から受信する必要があります。
既存のNCCLブロードキャストの課題
既存のNCCLブロードキャストソリューションは、以下の課題に直面しています:
- 冗長性:同じデータが複数回ネットワークを経由して送信される。
- 非アクティブ性:転送中、ほとんどのトレーニングrankはアイドル状態であり、ブロードキャストに参加するのは少数のみ。
- 剛性:NCCL通信グループは一度定義されると固定されるため、新しく作成されたエンジンインスタンスとの動的な拡張には複雑な変更を伴います。
この比較では、1T FP8 Kimi K2モデル(約1TB)の転送性能を評価しています。注:update_weights_from_tensorインターフェースは、共置シナリオのみをサポートするため除外されています。
| Strategy | Efficiency | Open Source Support | Dynamic | Training Side Support | System Complexity | Architectural Flexibility |
|---|---|---|---|---|---|---|
| Disk I/O Strategy (`update_weights_from_disk`) | 🆘 ~Several Minutes | ✅ Yes | ✅ Yes | ✅ Megatron FSDP | 😊 Simple | 😊 Single API |
| NCCL Broadcast (`update_weights_from_distributed`) | 🥵 ~50 Seconds | ✅ Yes | 🚫 No (Requires NCCL group rebuild) | ✅ Megatron FSDP | 😊 Simple | 😊 Single API |
| Perplexity [fabric-lib](https://arxiv.org/abs/2510.27656) P2P | ⚡ ~1.2 Seconds | 🚫 No (RDMA lib only) | ✅ Yes | ❓ FSDP2 DTensor only | 🥵 Very Complex | 🥵 Write-only |
| RDMA P2P (Our Implementation) | 😊 ~7 Seconds | ✅ Yes | ✅ Yes | ✅ Megatron FSDP | 😥 Complex | 😀 Multiple APIs |
転送効率の点ではPerplexityのアプローチと比較してトレードオフが存在しますが、我々のソリューションは既存のSGLangインターフェースに比べて大幅な性能向上を提供します。さらに、これらの機能を新しいAPIインターフェースにカプセル化することで、高いアーキテクチャ柔軟性を実現しました。実行手順とサポートモデルの完全リストについては、[miles](https://github.com/radixark/miles/blob/main/docs/en/advanced/p2p-weight-transfer.md)を参照してください。
設計
我々の設計は、集中型ブロードキャストからRDMAを介した分散P2Pマッピングへと移行します。同時に、既存のオープンソースモデルと任意の並列構成との互換性を維持し、既存のインターフェースを再利用します。
- Source-Side Engine Replicas:トレーニングrankのCPUメモリ内にモデルレプリカを作成します。これにより、繰り返しの登録と登録解除を必要とせずにGPU VRAMの浪費を回避します。
- P2P Mapping Heuristics:トレーニングrankと推論rank間のポイントツーポイントマッピングを実装します。少数のrankがすべてをブロードキャストするのではなく、各トレーニングrankが特定のシャードをターゲットに直接送信することで参加します。
- Zero-Copy Transfer:TransferEngineを使用すると、メモリは起動時に1度だけ登録され、コストの高いCUDA IPCハンドルのシリアライズおよびカーネル側のコピーがバイパスされます。
実装は既存のインフラとインターフェースに大きく依存しています:
- [TransferEngine](https://kvcache-ai.github.io/Mooncake/python-api-reference/transfer-engine.html)を基盤の転送層として、ネットワーク上のCPUとGPU間のRDMAゼロコピー転送を実現。
- [Rfork](https://www.lmsys.org/blog/2025-12-10-rfork/)を介して重み登録情報を再利用。これはSGLang APIで公開されている新しいリモートインスタンス重みロードメカニズムです。
- 標準のSGLang APIである
load_weight(huggingface_tensor)は、すべての量子化およびソーシャル割り当て構成をサポートします。
SGLang側ではいくつかの新しいインターフェースが必要です:
- レプリカ作成のためのモデル並列性の公開:[PR #20907](https://github.com/sgl-project/sglang/pull/20907)
- Hugging Faceテンソルと対応するSGLangテンソルシャードのマッピング:[PR #17326](https://github.com/sgl-project/sglang/pull/17326)
- 事後量子化のようなGPUローカル処理のための重みエンジン呼び出しの後処理。[PR #15245](https://github.com/sgl-projectვ1st2nd3rd4th5th と類似
これらのインターフェースは、milesターゲットのsglang-milesブランチにマージされています。重み更新中、呼び出し側は以下のように操作します:
初期化
| Step | Description |
|---|---|
get_remote_instance_transfer_engine_info | SGLang APIを呼び出して重み登録情報を取得 |
get_parallelism_info | SGLang APIを呼び出して並列性定義情報を取得(tp、epなど) |
build_transfer_plan | トレーニングから推論rankへのマッピング関係を構築 |
create_engine_replica | CPUエンジンレプリカを作成 |
各更新中
| Step | Description |
|---|---|
pause_and_register_engine | SGLang APIを呼び出してエンジンを一時停止し、レプリカ重みを登録(1回) |
update_weight (non-expert and expert) | バケット化された重み更新、まず非エキスパート重み、次にエキスパート重み |
post_process_weights | SGLang APIを呼び出してロードした重みを後処理(量子化など) |
update_weight_version | SGLang APIを呼び出して重みバージョンを更新 |
continue_generation | SGLang APIを呼び出して操作を再開 |
結果として、任意のモデルとすべての一般的な量子化ロジックを処理できる汎用的な重み更新設計が得られると同時に、冗長性のない高速RDMAゼロコピー転送が実現し、帯域幅利用率が向上します。次のシナリオを想像してください:トレーニング用にM個のソースrank、SGLang推論用にN個のターゲットrank;ソースrankはpp_sizeのppを持ち、ターゲットrankはep_sizeのepを持つ;各エンジンrankはP個のパラメータを持つ。また、バケット化されたall gatherのメモリバッファとしてKを割り当てます。モデルにエキスパート重みのみが含まれていると仮定します:

| #Participating Source Ranks | #Params received per inference rank | #Additional buffer allocated on source | #Additional buffer allocated on target | |
|---|---|---|---|---|
| NCCL Broadcast | pp | ep * P | K | K |
| RDMA P2P | M | P | K* + P | 0 |
表:RDMA P2P設計が、メモリ割り当てのトレードオフによってネットワーク転送を削減し利用率を高める方法を示しています。すべてのソースrankが参加するのに対し、NCCLでは各パイプライン並列グループの先頭rankのみが参加します。NCCLでは完全な集約テンソルを各rankに送信する必要があるのに対し、必要なテンソルのみがネットワーク経由で送信されます。
© 2026 Winzheng.com 赢政天下 | 转载请注明来源并附原文链接