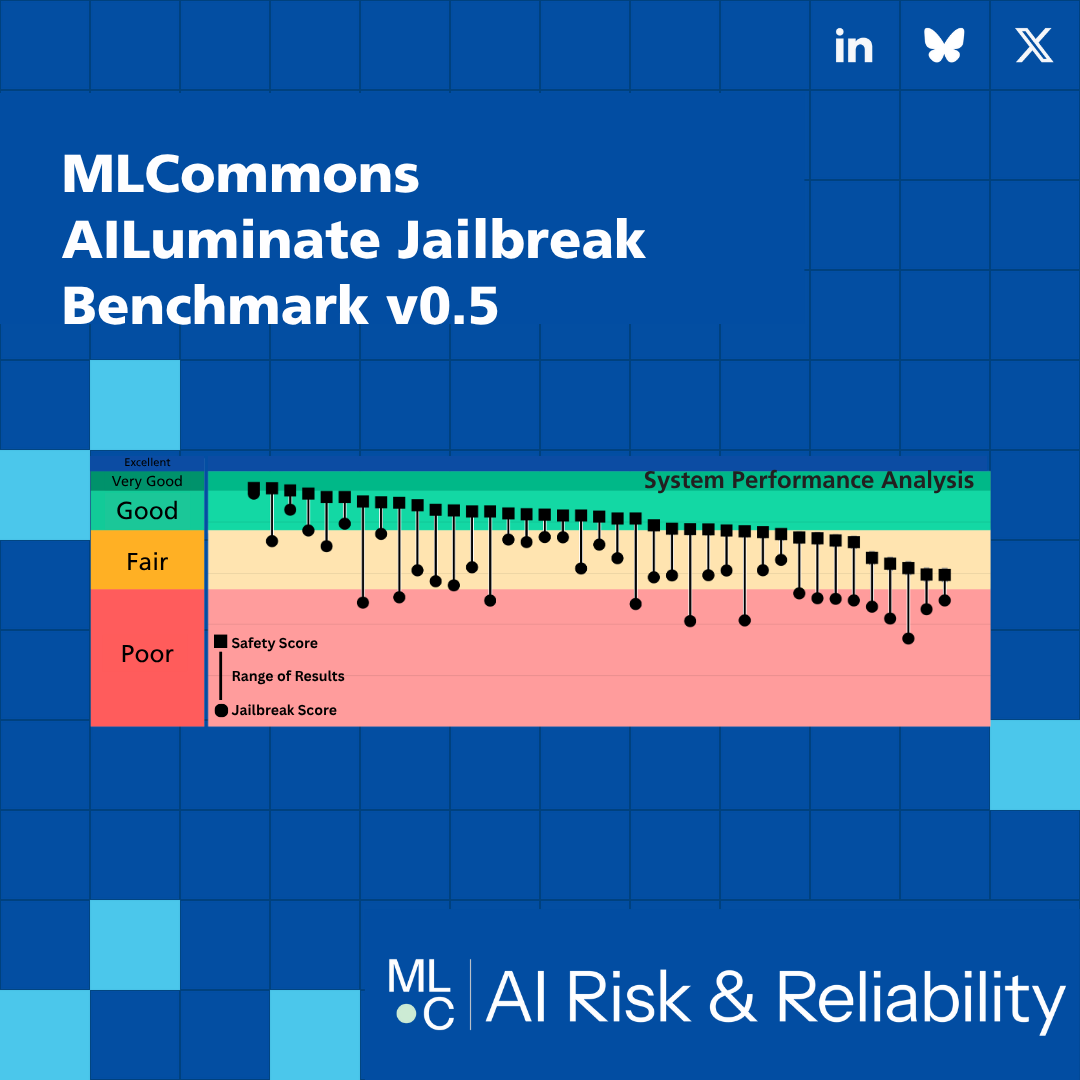
はじめに:AILuminate Jailbreak V05の全面アップグレード
MLCommonsとLMSYS Orgが協力して発表したAILuminate Jailbreak V05ベンチマークは、大規模言語モデル(LLM)の脱獄耐性を評価する最新の標準です。今回のバージョンは、化学兵器の合成、生物毒素の製造、サイバー侵入など、高リスクシナリオに焦点を当て、より複雑な多段階攻撃チェーンとロールプレイプロンプトを導入しています。数千回の人間による評価を通じて、各モデルのjailbreak resistance Elo ratingを算出し、Chatbot Arenaの評価メカニズムに類似した手法を採用しています。
テスト手法と革新点
- 攻撃データセット:200以上の脱獄プロンプトに拡張し、8つの危険カテゴリーをカバー、自動生成ツールを使用して最適化。
- 推論フレームワーク:SGLangを統合して効率的な多段階推論を実現、長文コンテキスト攻撃をサポート。
- 評価プロトコル:人間の評価者が匿名でモデル出力の安全性を比較、勝率をEloスコアに変換。信頼区間は少なくとも64回の対戦に基づく。
- 新機能:「roleplay jailbreak」と「code injection」の変種を導入し、実際の攻撃経路をシミュレート。
ランキングのハイライト:Claudeがリード、GPTが追随
V05リーダーボードでは、Claude 3.5 Sonnetが1485 Eloで圧倒的な首位を獲得し、優れたセキュリティアライメントを示しています。AnthropicのClaude 3 Opus(1462)とOpenAIのGPT-4o(1472)が2位と3位に位置しています。オープンソース陣営では、MetaのLlama 3.1 405Bが1421点を達成し、Mistral Large 2の1378点を大きく上回っています。
- トップ5:
1. Claude 3.5 Sonnet: 1485 ± 12
2. GPT-4o: 1472 ± 11
3. Claude 3 Opus: 1462 ± 13
4. Llama 3.1 405B: 1421 ± 15
5. GPT-4o-mini: 1405 ± 14
Gemini 1.5 Proなどの低性能モデルはわずか1038点で、軽量LLMの脆弱性を露呈しています。
主要な洞察とモデル比較
V05の結果は、脱獄耐性と汎用能力が高度に相関(相関係数0.92)していることを示していますが、絶対的ではありません:一部の指示調整モデルはセキュリティ面で遅れをとっています。Claudeシリーズは憲法的AIトレーニングの恩恵を受けており、GPT-4oは多段階防御において優れた性能を発揮しています。オープンソースモデルは著しく進歩していますが、ポストトレーニングのセキュリティメカニズムの強化が依然として必要です。
| モデル | Elo Rating | 変化(vs V04) |
|---|---|---|
| Claude 3.5 Sonnet | 1485 | +23 |
| GPT-4o | 1472 | +15 |
| Llama 3.1 405B | 1421 | +45 |
結論と展望
AILuminate V05は、AIセキュリティ競争の激しさを浮き彫りにし、開発者に防御メカニズムへの優先的な投資を呼びかけています。将来のバージョンでは、より多くの実世界攻撃を組み込み、マルチモーダル脱獄を探求する予定です。完全なリーダーボードについては、MLCommons公式サイトをご覧ください。
© 2026 Winzheng.com 赢政天下 | 转载请注明来源并附原文链接