TL;DR:本記事では、SGLangが決定論的推論を実現するための取り組みと、slimeとの協力による再現可能なRL訓練の進展を共有します。
最近、Thinking Machines Labがブログを発表し、その研究成果を詳述しました。その後、業界から熱い反響があり、オープンソース推論エンジンが安定的で実用的な決定論的推論を実現し、さらには完全に再現可能なRL訓練を実現することへの期待が高まりました。現在、SGLangとslimeが手を組んで解決策を提供しています。
Thinking Machines Labのbatch-invariant演算子を基に、SGLangは完全な決定論的推論を実現し、同時にchunked prefill、CUDA graphs、radix cache、non-greedy samplingとの互換性を保っています。CUDA graphsを有効にすると、SGLangは2.8倍の高速化をもたらし、性能オーバーヘッドは34.35%に低下しました(TMLの61.5%と比較)。
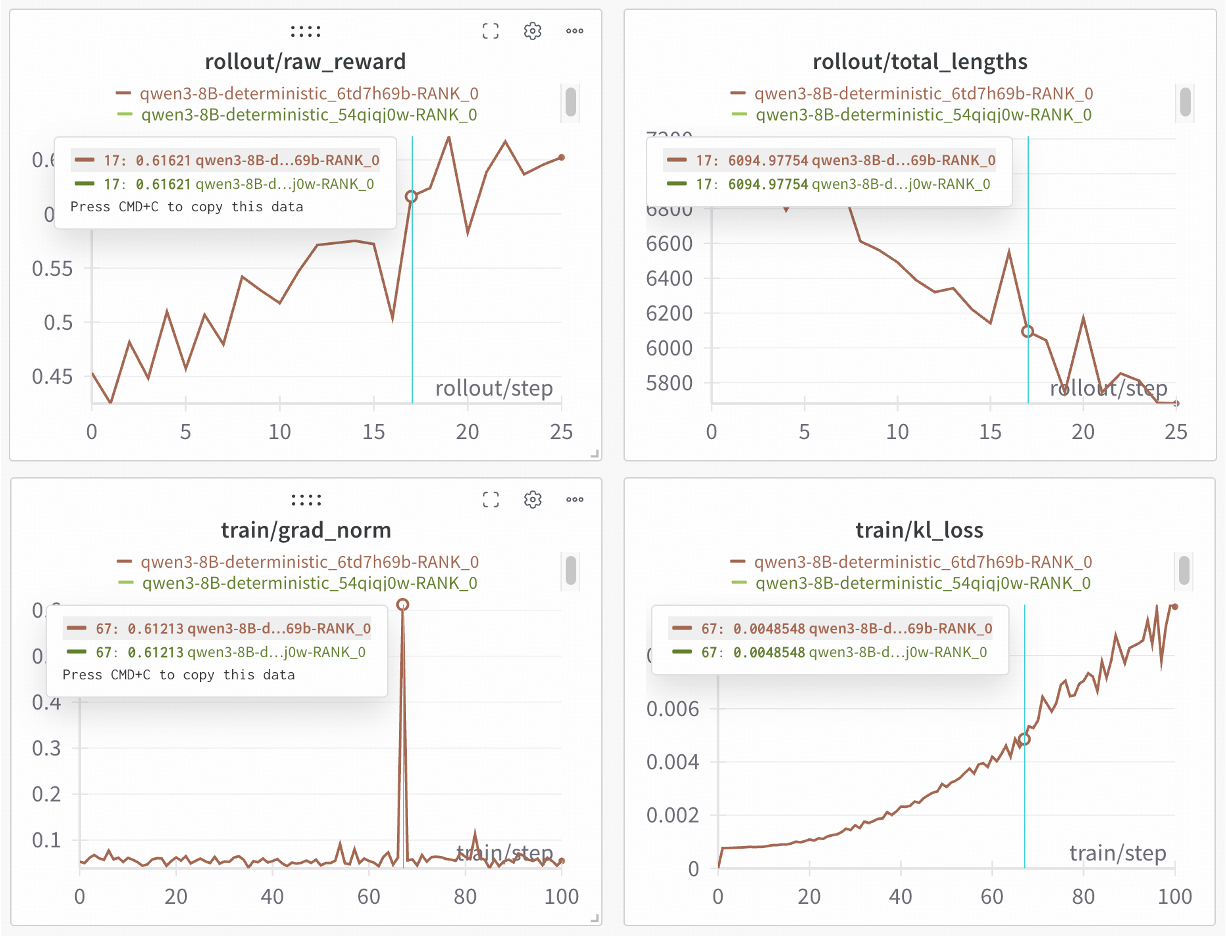
この基盤の上で、SGLangとslimeチームが協力し、さらに100%再現可能なRL訓練を解き放ちました——わずかなコード修正だけで実現できます。Qwen3-8Bでの検証実験では、2回の独立した訓練が完全に同じ曲線を生成し、厳密な科学実験に信頼できる保証を提供しています。
なぜ決定論的推論がこれほど重要なのか
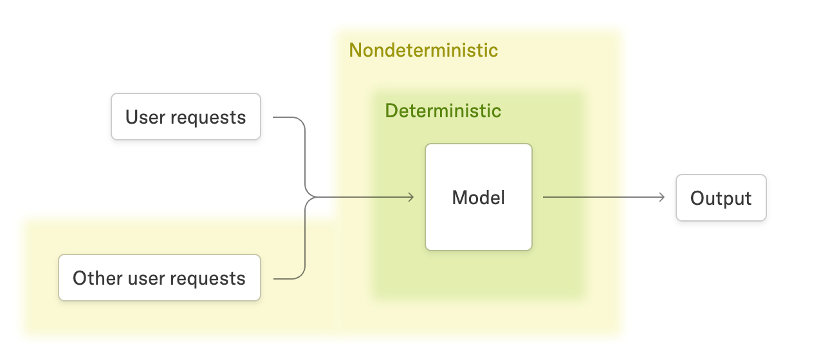
大規模言語モデル(LLMs)推論の一貫した出力能力がますます重要になっています。例えば、推論結果の不確定性により、on-policy強化学習(RL)が暗黙的にoff-policy RLに変換される可能性があります(研究者が指摘するように)。SGLangでtemperatureを0に設定しても、動的バッチ処理とradix cacheの影響により、サンプリングは依然として非決定論的です(過去の議論はこちら)。
TMLブログで述べられているように、最大の不確定性の源はバッチサイズの変化です:ユーザーが同じプロンプトを繰り返し送信する際、他のリクエストとバッチ処理されることで、バッチサイズの違いが非決定論的な出力を引き起こします。具体的には、異なるバッチサイズがカーネルのreduction splittingに影響を与え、reduction blockの順序とサイズの変化を引き起こし、浮動小数点演算の非結合性により、非決定論的な出力が生成されます。この問題を解決するために、彼らはreductionカーネル(RMSNorm、行列乗算、アテンションなど)をbatch-invariant実装で置き換え、コンパニオンライブラリとしてオープンソース化しました。
He, Horace and Thinking Machines Lab, "Defeating Nondeterminism in LLM Inference", Thinking Machines Lab: Connectionism, Sep 2025.
TMLの作業を基に、SGLangは高スループットの決定論的LLM推論ソリューションを提供し、batch-invariantカーネル、CUDA graphs、radix cache、chunked prefillを組み合わせ、高性能を実現しています。包括的なテストとRL訓練実験により決定論性を検証しました。
主な拡張には以下が含まれます:
- TMLのbatch-invariantカーネルの統合:mean、log-softmax、行列乗算カーネルを含む。
- batch-invariantアテンションカーネルの実装:固定split-KVサイズ、FlashInfer、FlashAttention 3、Tritonなど複数のバックエンドをサポート。
- 一般的な推論機能との完全な互換性:chunked prefill、CUDA graph、radix cacheなど、決定論的モードですべてサポート。
- per-requestシードの公開:temperature > 0の場合でも決定論的推論を有効化。
- 性能最適化:TMLブログの61.5%のスローダウンと比較して、SGLangはFlashInferとFlashAttention 3バックエンドで平均わずか34.35%、CUDA graphsで2.8倍の高速化を達成。
実験結果
決定論的動作の検証
決定論的テストスイートを導入し、異なるバッチ処理条件下での推論結果の一貫性を検証しました。テストは簡単なものから複雑なものまで3つのサブテストをカバーしています:
- Single:同じプロンプトを異なるバッチサイズで実行し、出力の一貫性をチェック。
- Mixed:同じバッチに短い/長いプロンプトを混在させ、一貫性を検証。
- Prefix:同じ長いテキストから異なる接頭辞長のプロンプトを派生させ、ランダムにバッチ処理し、再現性をテスト。
50回のサンプリング試行の結果、数字は各サブテストの一意の出力数を表します(低いほど決定論的)。
| Attention Backend | Mode | Single Test | Mixed Test (P1/P2/Long) | Prefix Test (prefix_len=1/511/2048/4097) |
|---|---|---|---|---|
| FlashInfer | Normal | 4 | 3 / 3 / 2 | 5 / 8 / 18 / 2 |
| FlashInfer | Deterministic | 1 | 1 / 1 / 1 | 1 / 1 / 1 / 1 |
| FA3 | Normal | 3 | 3 / 2 / 2 | 4 / 4 / 10 / 1 |
| FA3 | Deterministic | 1 | 1 / 1 / 1 | 1 / 1 / 1 / 1 |
| Triton | Normal | 3 | 2 / 3 / 1 | 5 / 4 / 13 / 2 |
| Triton | Deterministic | 1 | 1 / 1 / 1 | 1 / 1 / 1 / 1 |
*QWen3-8Bでテスト。CUDA graphとchunked prefillを有効化、FlashInferとTritonはradix cacheを無効化(サポートは開発中)。
CUDA Graph高速化
CUDA graphsは複数のカーネル起動を単一の起動に結合することで推論を高速化します。16リクエスト(入力/出力各1024トークン)の総スループットを評価した結果、すべてのアテンションカーネルで少なくとも2.79倍の高速化が示されました。
| Attention Backend | CUDA Graph | Throughput (tokens/s) |
|---|---|---|
| FlashInfer | Disabled | 441.73 |
| FlashInfer | Enabled | 1245.51 (2.82x) |
| FA3 | Disabled | 447.64 |
| FA3 | Enabled | 1247.64 (2.79x) |
| Triton | Disabled | 419.64 |
| Triton | Enabled | 1228.36 (2.93x) |
*構成:QWen3-8B, TP1, H100 80GB。すべてのパフォーマンスベンチマークでradix cacheを無効化。
オフライン推論性能測定
3つの一般的なRL rolloutワークロード(256リクエスト、異なる入力/出力長)を使用してエンドツーエンドレイテンシを測定しました。決定論的モードのオーバーヘッドは25%-45%で、FlashInferとFA3は平均34.35%です。主なオーバーヘッドは最適化されていないbatch-invariantカーネルから来ており、最適化の余地が大きいです。
| Attention Backend | Mode | Input 1024 Output 1024 | Input 4096 Output 4096 | Input 8192 Output 8192 |
|---|---|---|---|---|
| FlashInfer | Normal | 30.85 | 332.32 | 1623.87 |
| FlashInfer | Deterministic | 43.99 (+42.6%) | 485.16 (+46.0%) | 2020.13 (+24.4%) |
| FA3 | Normal | 34.70 | 379.85 | 1438.41 |
| FA3 | Deterministic | 44.14 (+27.2%) | 494.56 (+30.2%) | 1952.92 (+35.7%) |
| Triton | Normal | 36.91 | 400.59 | 1586.05 |
| Triton | Deterministic | 57.25 (+55.1%) | 579.43 (+44.64%) | 2296.60 (+44.80%) |
*構成:QWen3-8B, TP1, H200 140GB。radix cacheを無効化。
決定論的推論は通常モードより遅いですが、デバッグと再現性のために使用することを推奨します。将来の作業は高速化に焦点を当て、オーバーヘッドを20%以下または通常モードと同等にすることを目標としています。
使用方法
環境設定
SGLang ≥0.5.3バージョンをインストール:
pip install "sglang[all]>=0.5.3"
サーバーの起動
SGLangは複数のモデルで決定論的推論をサポートしています。例えばQwen3-8Bの場合、--enable-deterministic-inferenceフラグを追加するだけです:
python3 -m sglang.launch_server \
--model-path Qwen/Qwen3-8B \
--attention-backend <flashinfer|fa3|triton> \
--enable-deterministic-inference
技術詳細
Chunked Prefill
SGLangのchunked prefill技術は長いコンテキストリクエストを処理するために使用されますが、デフォルトのチャンク戦略はアテンションカーネルの決定論的要件に違反します。図に示すように、長さ6000の2つのシーケンスseq_aとseq_bを考慮し、最大チャンクサイズ8192、決定論的アテンションに必要なsplit-KVサイズ2048の場合、各シーケンスはチャンク処理できます...
© 2026 Winzheng.com 赢政天下 | 转载请注明来源并附原文链接