本稿では、**SGLang**で全く新しいサービスパラダイム**PD-Multiplexing**をサポートする初期成果を紹介します。このパラダイムは、LLMサービスにより高いgoodputをもたらすことを目的としています。これは**GreenContext**—NVIDIA GPUの新技術を十分に活用し、同一プロセス内でGPUリソースの軽量で細粒度な分割をサポートし、タスク間の効率的なリソース共有を実現します。私たちは、これがModel-as-a-Service (MaaS)デプロイメントの強力な新しい道筋となり、より強力なSLO保証とより高いgoodputを提供できると考えています。
LLMサービスにおけるGoodputの課題:根強い難題
大規模なMaaSデプロイメントは、LLMサービスシステムがスループットを犠牲にすることなく、厳格なService Level Objectives (SLO)を継続的に満たすことを要求します。実際には、これは推論の2つのフェーズのレイテンシSLOを同時に保証する必要があることを意味します:prefillフェーズのTime-to-First-Token (TTFT)と、decodeフェーズのInter-Token Latency (ITL、Time-Between-Tokens、TBTとも呼ばれる)です。難しい点は、prefillとdecodeが同じサービスインスタンスで交互に実行され、GPUリソースの競合を引き起こすことです。現在の一般的なソリューションには以下が含まれます:
- インスタンスレベルのPD分離:prefillとdecodeを異なるインスタンスに配置します。しかし、これにはGPUリソースの静的な分割が必要であり、**KVキャッシュのインスタンス間移行**により複雑性が生じ、高性能な相互接続と通信ライブラリが必要です。
- シーケンスレベルのchunked-prefill:長いシーケンスを小さなチャンクに分割し、ITLを制御するためにdecodeイテレーションと融合します。しかし、チャンクサイズのトレードオフが必要です:小さすぎるとITL保証に影響し、大きすぎるとGPU利用率が低下します。
特に実際のLLMサービスの厳しいSLO閾値に対して、これら2つの方法の制限はますます明らかになっています。
PD-Multiplexing:効率的なサービスの新パラダイム
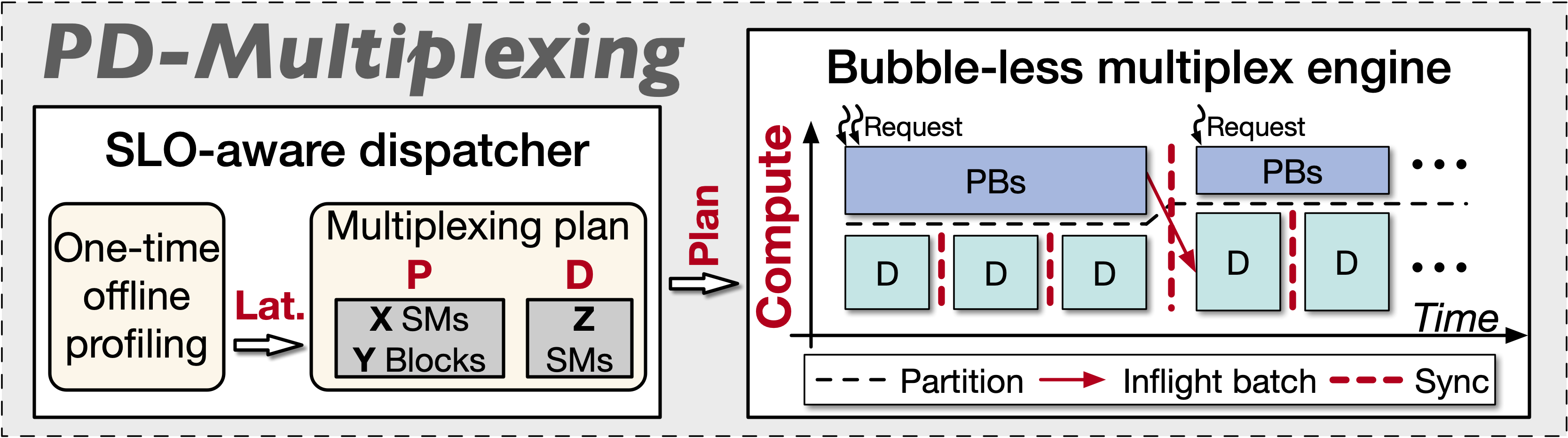
そこで、私たちは**PD-Multiplexing**という新しいパラダイムを提案し、同一インスタンス内のintra-GPU空間共有を通じて、prefillとdecodeの多重化を実現します。主な利点には以下が含まれます:
- prefillとdecodeが同じインスタンスのKVキャッシュプールを共有し、**高コストなインスタンス間移行を回避**します。
- GPU計算リソース(SM)は**動的に流動**でき、負荷の変化に応じてprefillとdecode間で割り当てられます。
- **分離された実行**により、厳格なITL SLOを満たしながらprefillパフォーマンスが影響を受けないことを保証します。
図1に示すように、このパラダイムの核心には、バブルのない多重化エンジン(prefill/decodeを独立して効率的に実行)とSLO対応スケジューラ(準拠した多重化計画を反復的に生成)が含まれます。
GreenContextによるバブルのない多重化エンジンの実現
私たちは**GreenContext**(CUDA 12.4から導入、12.6で複数CUDAストリーム専用SM割り当てをサポート)に基づいてこのパラダイムを構築し、intra-process空間共有を実現します。GPUリソースはリアルタイムで動的に分割でき、SLOやワークロードなどのニーズに適応できます。
既存のアーキテクチャを維持するため、私たちは単一スレッドスケジューリングでprefill/decodeを多重化し(Python GIL制限を回避)、非同期特性を利用して専用のGreenContextストリームを切り替えます。
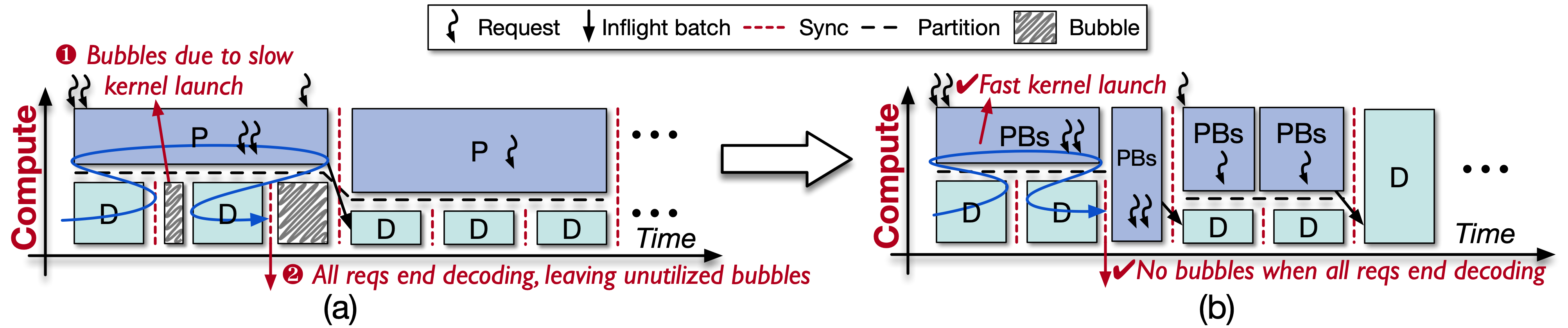
しかし、GreenContextを直接統合するとGPUバブルが発生します(図2(a)のように):(1) prefillの起動時間はdecode(単一CUDA graph)よりもはるかに長い、(2) decodeイテレーションは不確定で、早期に終了するとSMがアイドル状態になります。そのため、私たちはprefillを小さなチャンクに分割します(図2(b)のように)。prefillは計算集約的なため、このオーバーヘッドは微小で、バブルを効果的に排除します。
パフォーマンスプロファイリングとスケジューリング戦略の設計
バブルのないエンジンを装備した後の次のステップは、prefillチャンクとdecodeバッチのスケジューリングです。オフラインプロファイリングは、2つのフェーズがGreenContextでリソースを競合することを示しています(SMは分割されているがメモリ帯域幅は共有)。私たちは代表的なワークロードをオフラインでプロファイリングし、レイテンシ予測器を訓練してSLO対応スケジューリングを駆動します(詳細はモデル/ハードウェアに依存し、将来チュートリアルを提供予定)。
スケジューリングの直感:**ITL SLOを満たすのに必要なだけのSMをdecodeに割り当て、残りはすべてprefillに割り当て、同時にprefillチャンク数を決定します**。このように、decodeは厳格に準拠し、prefillは最大限に進行してdecodeバッチを拡張します。
ベンチマークテスト
私たちは複数のベースラインと比較し、複数のワークロード/デバイスでPD-Multiplexingを評価しました。まず再現しやすい実験を示し、次に実際のトレースで優位性を示し、最後にスケジューリングの詳細を視覚化します。包括的な評価では、PD-Multiplexingのgoodputは最大**3.06倍**向上しました。
* 以下の結果は研究目的です。実際のアプリケーションでは、SLOはより具体的であり、ここではPD-Multiplexingの可能性を示しています。異なるチャンクサイズのChunked-prefillとの比較
単一H200でCodeLlama-34b-hfを実行し、異なるチャンクサイズのchunked-prefillと比較しました。図3はP99 TTFTとITLを報告し、ITL SLO目標は60ms(TTFTは制約なし、P99のみ報告)です。実線の点はITL SLOを満たすことを示し、中空の点は違反を示します。
PD-Multiplexingは最速のTTFTを提供し、同時に厳格なITL SLOを安定的に満たします。chunked-prefillはチャンクサイズを1024以下に下げる必要があり準拠しますが、prefillパフォーマンスとGPU利用率を損ない、特に長いコンテキスト(LooGLEなど)でより明らかです。再現の詳細はこちらをご覧ください。
実際のワークロードでの結果
実際のトレースMooncake-Tool&Agentを使用して評価し、chunked-prefill(chunk=512)とPD-disaggregation(P:D=1:1、いずれもSGLangベース)と比較し、8xA100sで、Llama3.1-70B、プレフィックスキャッシュ共有を有効にしました。
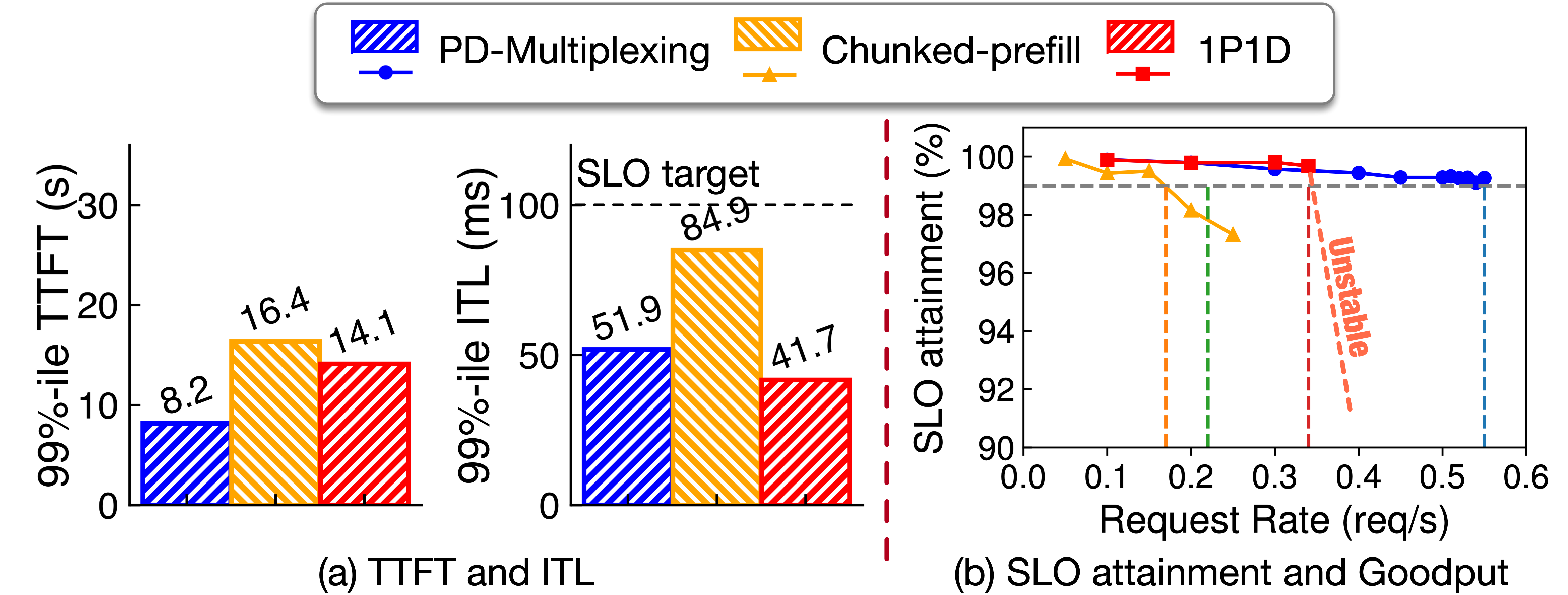
図4(a)はTTFTとITLを示しています:PD-Multiplexingはchunked-prefillよりも優れています。PD-disaggregationと比較して、TTFTはより短く、両方ともdecode SLOを満たします。goodputを評価するために、私たちは徐々にリクエストレートを増加させ、SLO達成率を測定しました。図5に示すように、PD-Multiplexing...
© 2026 Winzheng.com 赢政天下 | 转载请注明来源并附原文链接