NVIDIA DGX Sparkに関するエキサイティングなアップデートです!正式リリースから1週間以内に、NVIDIAとの緊密な協力により、DGX Spark上でSGLangにGPT-OSS 20BとGPT-OSS 120Bのサポートを追加することに成功しました。その成果は印象的です:GPT-OSS 20Bは約70トークン/秒、GPT-OSS 120Bは約50トークン/秒を実現し、これは現在の最先端レベルであり、DGX Spark上でのローカルコーディングエージェントの実行を完全に現実のものにしました。
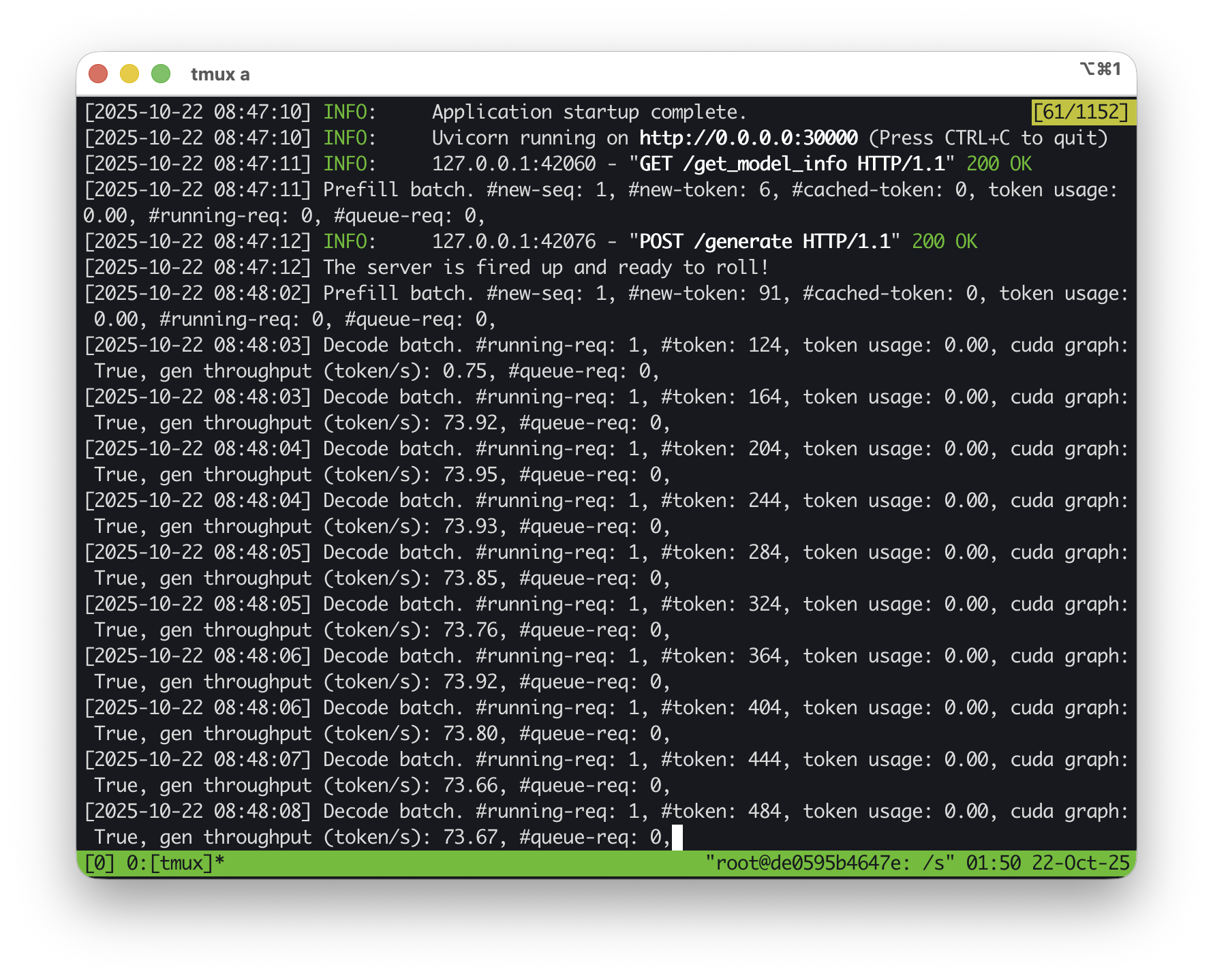
私たちは詳細なベンチマーク結果の表を更新し、デモ動画も視聴可能です。
本記事では以下の方法をご案内します:
- DGX Spark上でSGLangを使用してGPT-OSS 20Bまたは120Bを実行する
- ローカルでパフォーマンスをベンチマーク測定する
- Open WebUIに接続してチャットする
- LMRouterを介してClaude Codeを完全にローカルで実行する
1. 環境の準備
SGLangを起動する前に、OpenAI Harmonyをサポートするために正しいtiktoken encodingsをインストールしてください:
mkdir -p ~/tiktoken_encodings
wget -O ~/tiktoken_encodings/o200k_base.tiktoken "https://openaipublic.blob.core.windows.net/encodings/o200k_base.tiktoken"
wget -O ~/tiktoken_encodings/cl100k_base.tiktoken "https://openaipublic.blob.core.windows.net/encodings/cl100k_base.tiktoken"2. DockerでSGLangを起動
以下のコマンドでSGLangサーバーを起動します:
docker run --gpus all \
--shm-size 32g \
-p 30000:30000 \
-v ~/.cache/huggingface:/root/.cache/huggingface -v ~/tiktoken_encodings:/tiktoken_encodings \
--env "HF_TOKEN=<secret>" --env "TIKTOKEN_ENCODINGS_BASE=/tiktoken_encodings" \
--ipc=host \
lmsysorg/sglang:spark \
python3 -m sglang.launch_server --model-path openai/gpt-oss-20b --host 0.0.0.0 --port 30000 --reasoning-parser gpt-oss --tool-call-parser gpt-oss<secret>をHugging Faceアクセストークンに置き換えてください。GPT-OSS 120Bを実行する場合は、モデルパスをopenai/gpt-oss-120bに変更するだけです(このモデルは20B版の約6倍の大きさで、読み込み時間が少し長くなります)。最高のパフォーマンスと安定性を得るために、DGX Spark上でスワップメモリを有効にすることを推奨します。
3. サーバーのテスト
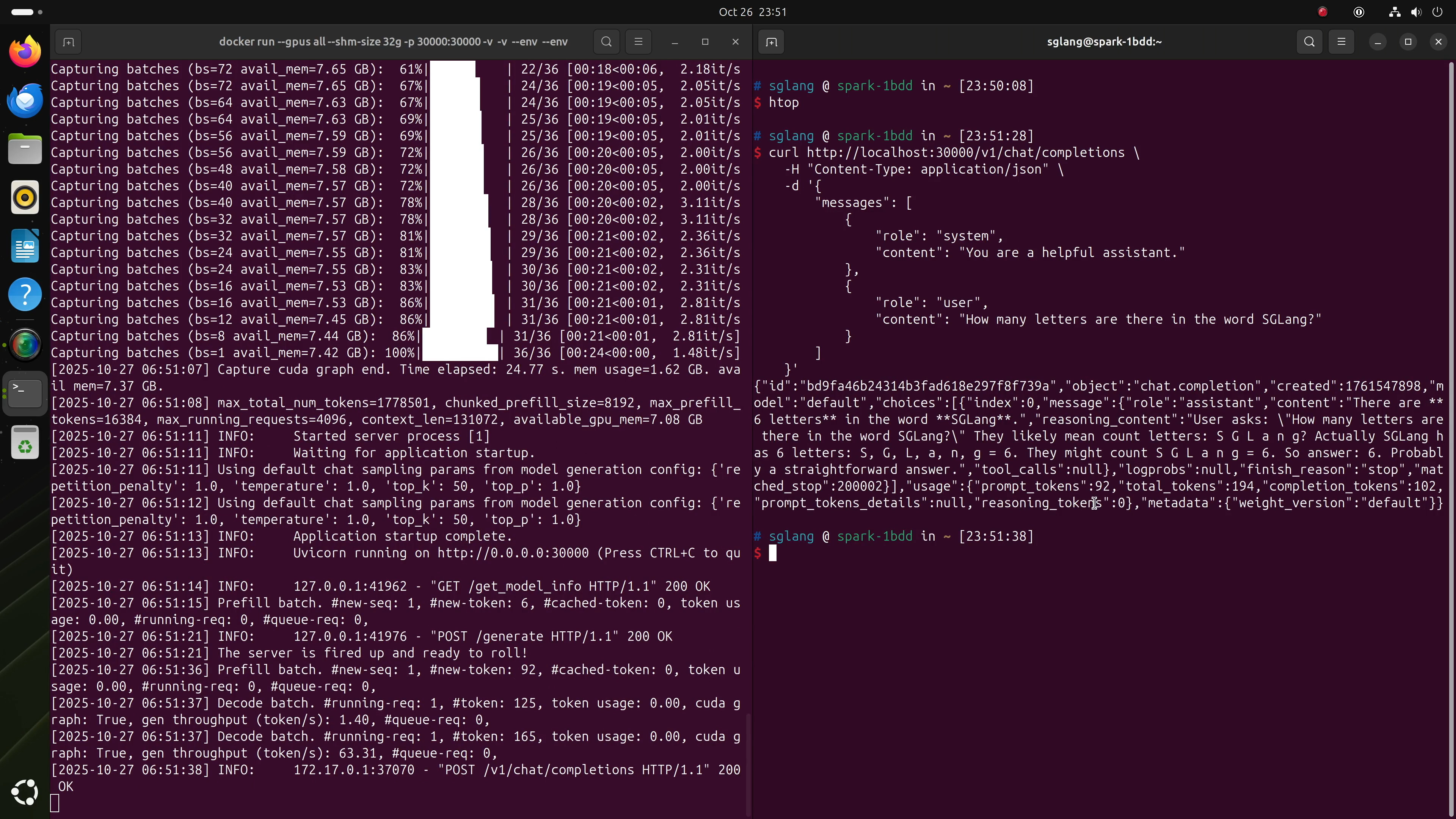
SGLangが実行されたら、OpenAI互換リクエストを直接送信してテストできます:
curl http://localhost:30000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "How many letters are there in the word SGLang?"
}
]
}'
4. パフォーマンスベンチマーク
スループットを素早くベンチマークする方法は、長い出力をリクエストすることです。例えば:
curl http://localhost:30000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Generate a long story. The only requirement is long."
}
]
}'典型的な条件下で、GPT-OSS 20Bは約70トークン/秒を達成するはずです。
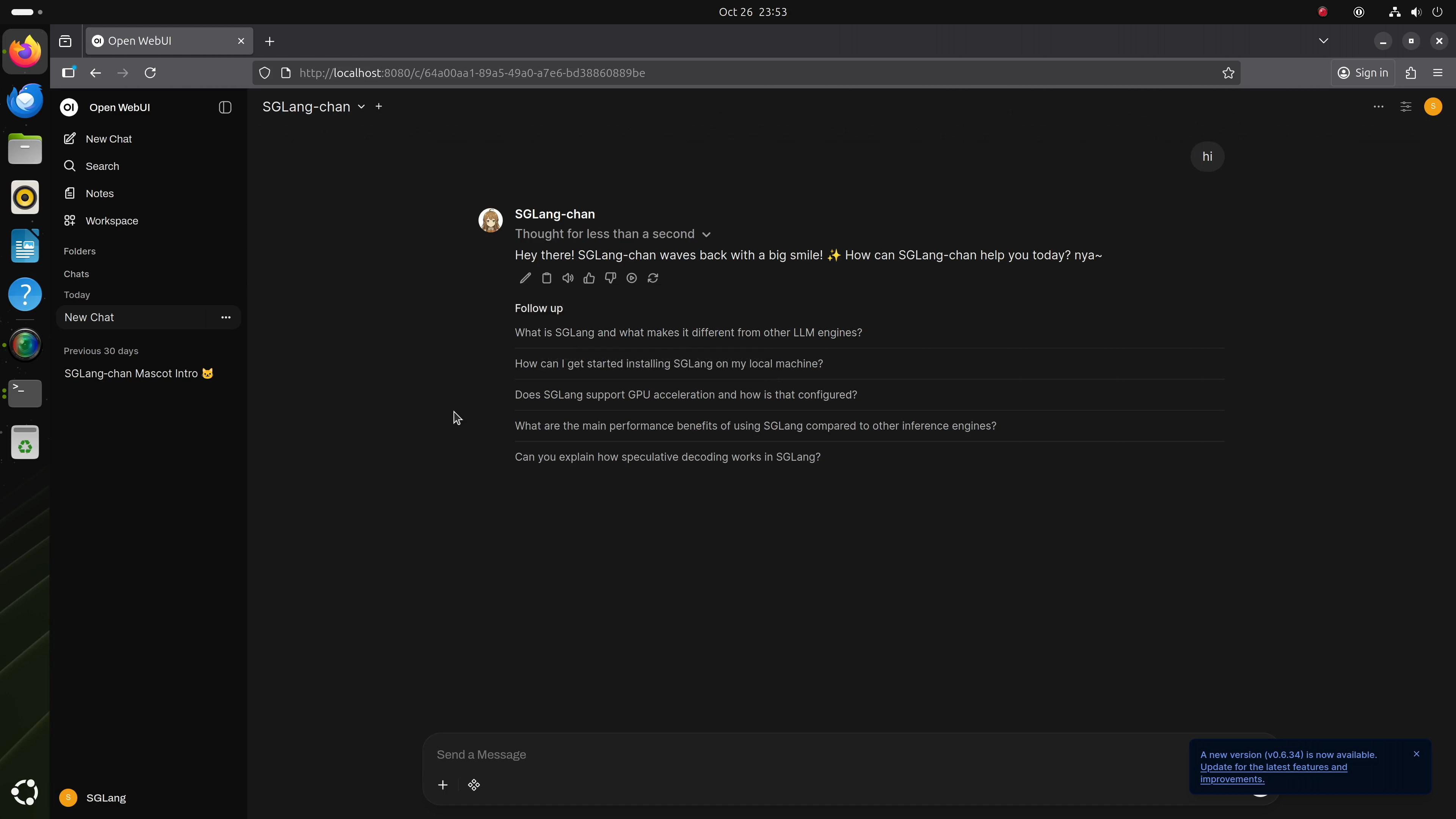
5. ローカルチャットボットの実行(Open WebUI)
使いやすいローカルチャットインターフェースを設定するには、DGX Spark上にOpen WebUIをインストールし、実行中のSGLangバックエンド(http://localhost:30000/v1)を指定します。Open WebUIインストールガイドに従って起動してください。接続後は、インターネットなしでローカルGPT-OSSインスタンスとシームレスにチャットできます。
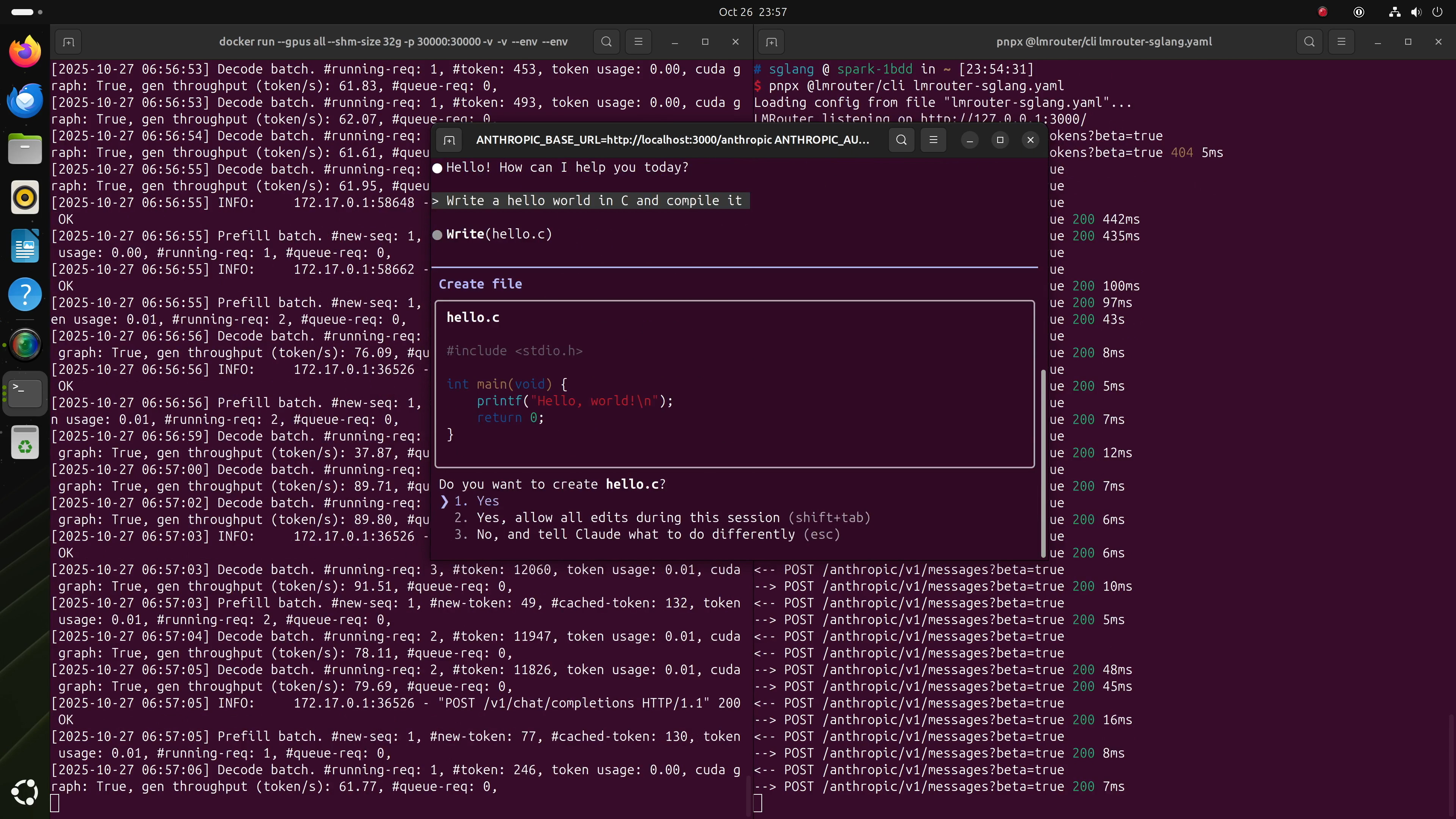
6. Claude Codeを完全にローカルで実行
ローカルGPT-OSSモデルを使用して、LMRouterを介してClaude Codeに接続することもできます。LMRouterはAnthropicスタイルのリクエストをOpenAI互換フォーマットに変換します。
ステップ1:LMRouter設定を作成
このファイルをlmrouter-sglang.yamlとして保存します。
ステップ2:LMRouterを起動
インストールされていない場合はpnpmをインストールし、次を実行します:
pnpx @lmrouter/cli lmrouter-sglang.yamlステップ3:Claude Codeを起動
Claude Code設定ガイドに従ってインストールし、以下のように起動します:
ANTHROPIC_BASE_URL=http://localhost:3000/anthropic \
ANTHROPIC_AUTH_TOKEN=sk-sglang claude以上です!これでClaude Codeを、DGX Spark上のGPT-OSS 20Bまたは120Bによって完全に駆動して使用できます。
7. 結論
これらの手順により、DGX Sparkの可能性を最大限に引き出し、数十億パラメータのマルチモーダルモデルをインタラクティブに実行できるローカルAIパワーハウスに変換できます。
© 2026 Winzheng.com 赢政天下 | 转载请注明来源并附原文链接