概要
私たちはSGLangとAutoRoundの正式な連携を発表できることを嬉しく思います。この連携により、効率的なLLM推論のための低ビット量子化がサポートされます。この統合により、開発者はAutoRoundの符号勾配最適化技術を使用して大規模モデルを量子化し、SGLangの効率的なランタイムで直接デプロイすることで、精度損失を最小限に抑えながら大幅にレイテンシを削減した低ビットモデル推論を実現できます。
AutoRoundとは?
AutoRoundは、大規模言語モデル(LLMs)と視覚言語モデル(VLMs)向けに設計された先進的なポストトレーニング量子化(PTQ)ツールキットです。符号勾配降下法を利用して重み丸めとクリッピング範囲を共同最適化し、INT2からINT8などの低ビット量子化を実現し、ほとんどのシナリオで精度損失を最小限に抑えます。例えば、INT2精度では人気のベースラインと比較して相対精度が最大2.1倍高く、INT4精度でも優位性を維持しています。下図はAutoRoundのコアアルゴリズムの概要を示しています。
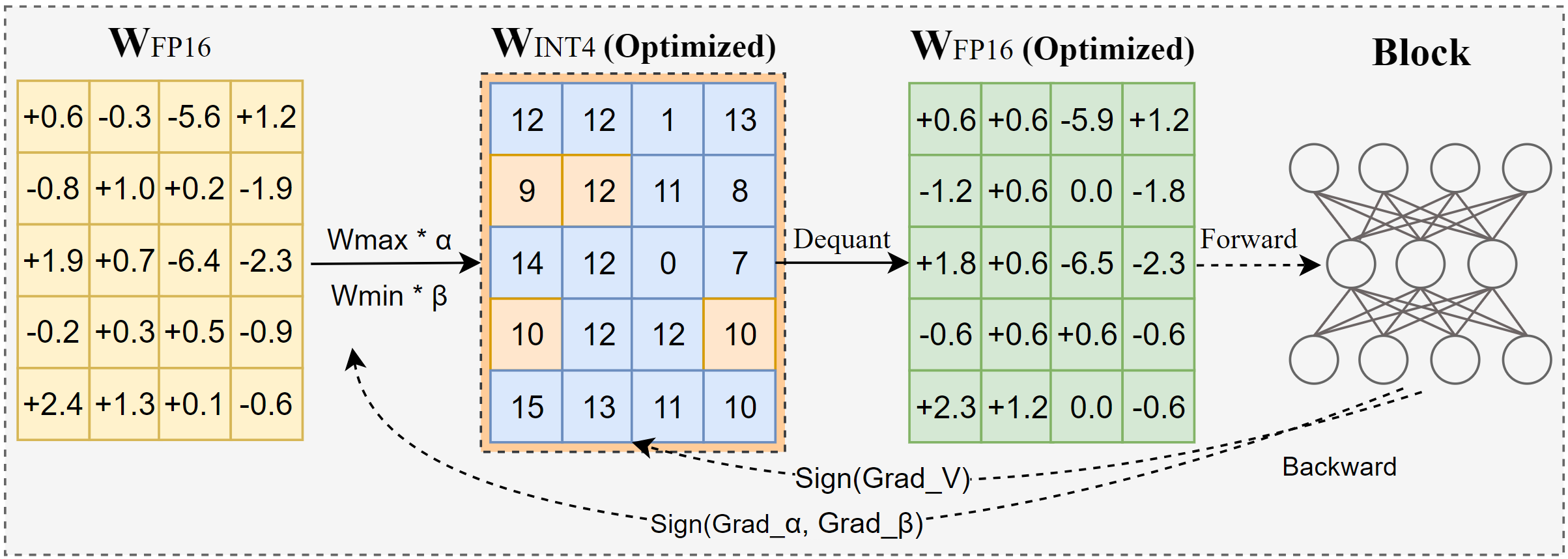
AutoRoundアルゴリズム概要
完全な技術詳細はAutoRoundの論文をご覧ください:Optimize Weight Rounding via Signed Gradient Descent for the Quantization of LLMs。
強力な性能にもかかわらず、AutoRoundは効率的で軽量です。軽量モードでは、単一GPUで72Bモデルの量子化がわずか37分で完了します。また、混合ビット調整、lm-head量子化、GPTQ/AWQ/GGUF形式のエクスポート、カスタム調整レシピもサポートしています。
AutoRoundのハイライト
AutoRoundはアルゴリズムの革新に注力するだけでなく、完全な量子化エンジニアリング能力で広く認められています。
- 精度:低ビット精度で卓越した精度を提供
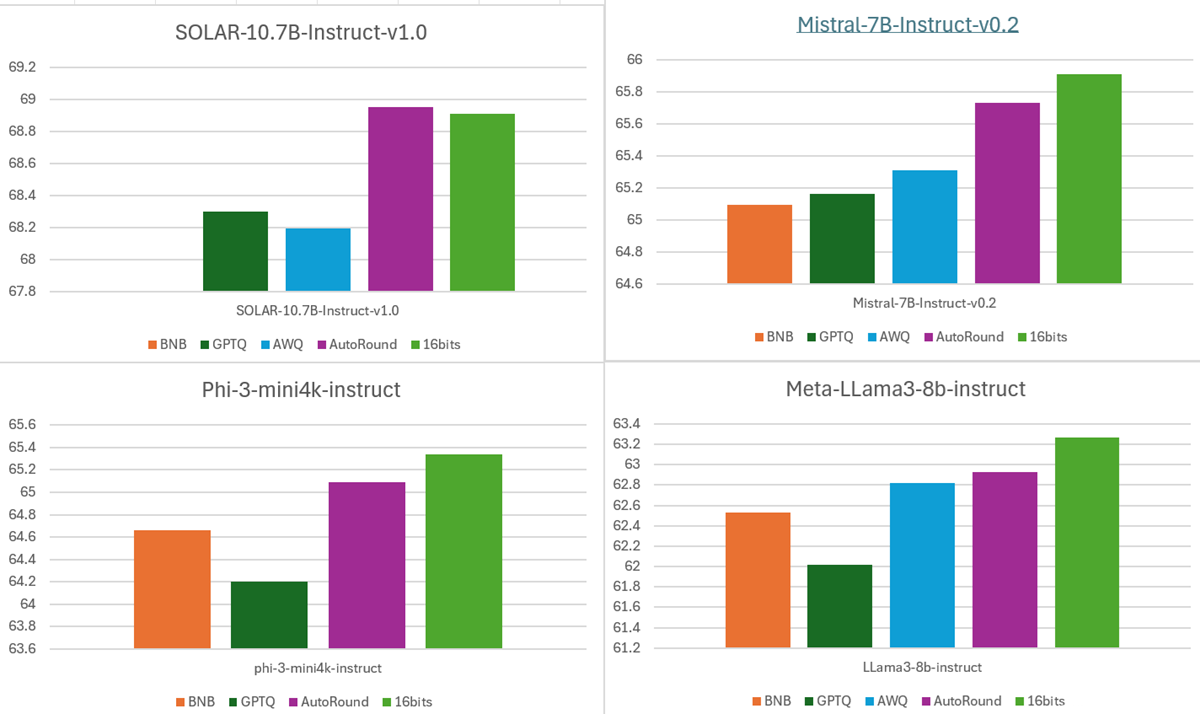
INT4重みでの10+タスク平均精度
- 量子化スキーム:重みのみの量子化、重みとアクティベーション量子化、およびアクティベーション量子化の動的/静的モードをサポート
- 混合ビット:数分で混合ビット/その他のデータ型スキームを生成する効果的なアルゴリズム
- 幅広い互換性:
- ほぼすべての人気LLMアーキテクチャと10以上のVLMsをサポート
- デバイス:CPU、Intel GPU、CUDA
- データ型:INT2-INT8、MXFP4、NVFP4、FP8、MXFP8
- 効率性:ブロック単位の調整によりVRAM使用率を削減し、高スループットと高速性を維持

量子化時間コスト比較
- コミュニティ採用:SGLang、TorchAO、Transformers、vLLMとのシームレスな統合;HuggingFaceモデルハブ(Intel、OPEA、Kaitchup、fbaldassarriなど)でのダウンロード数は約200万
- エクスポート形式:AutoRound、GPTQ、AWQ、GGUF、Compressed-tensor(初期サポート)
統合の概要
SGLangは、スケーラブルで低レイテンシのLLMデプロイメントをサポートする次世代推論ランタイムを提供します。マルチモーダル、マルチGPU、ストリーミング実行モデルは、チャットとエージェント推論タスクに適しており、優れた効率性を発揮します。
SGLangの柔軟なアーキテクチャは、ネイティブな量子化モデル読み込みフックを提供し、デプロイメントにおけるAutoRoundの完全な可能性を解放します。
1. AutoRoundを使用した量子化
AutoRoundは重み丸めを自動的に最適化し、SGLang互換の量子化重みをエクスポートします。
1.1 API使用
# for LLM
from auto_round import AutoRound
model_id = "meta-llama/Llama-3.2-1B-Instruct"
quant_path = "Llama-3.2-1B-Instruct-autoround-4bit"
# Scheme examples: "W2A16", "W3A16", "W4A16", "W8A16", "NVFP4", "MXFP4" (no real kernels), "GGUF:Q4_K_M", etc.
scheme = "W4A16"
format = "auto_round"
autoround = AutoRound(model_id, scheme=scheme)
autoround.quantize_and_save(quant_path, format=format) # quantize and save1.2 CMD使用
auto-round \
--model Qwen/Qwen2-VL-2B-Instruct \
--bits 4 \
--group_size 128 \
--format "auto_round" \
--output_dir ./tmp_autoround2. SGLangを使用したデプロイ
SGLang(バージョン >= v0.5.4.post2)はAutoRound量子化モデルを直接サポートし、一般的なLLM、VLM、MoEモデルと互換性があり、混合ビット量子化モデルの推論と評価をサポートします。
2.1 OpenAI互換推論
from sglang.test.doc_patch import launch_server_cmd
from sglang.utils import wait_for_server, print_highlight, terminate_process
# 等同于终端命令:
# python3 -m sglang.launch_server --model-path Intel/DeepSeek-R1-0528-Qwen3-8B-int4-AutoRound --host 0.0.0.0
server_process, port = launch_server_cmd(
"""
python3 -m sglang.launch_server --model-path Intel/DeepSeek-R1-0528-Qwen3-8B-int4-AutoRound \
--host 0.0.0.0 --log-level warning
"""
)
wait_for_server(f"http://localhost:{port}")2.2 オフラインエンジンAPI推論
import sglang as sgl
llm = sgl.Engine(model_path="Intel/DeepSeek-R1-0528-Qwen3-8B-int4-AutoRound")
prompts = ["Hello, my name is"]
sampling_params = {"temperature": 0.6, "top_p": 0.95}
outputs = llm.generate(prompts, sampling_params)
for prompt, output in zip(prompts, outputs):
print(f"Prompt: {prompt}\nGenerated text: {output['text']}")さらに多くの柔軟な設定とデプロイメントオプションがあなたを待っています!
量子化ロードマップ
AutoRound量子化ベンチマーク結果は、低精度でも精度が堅牢に維持されることを示しています。下表は、MXFP4、NVFP4、混合ビット量子化における優位性を強調しています。精度はlambada_openai、hellaswag、piqa、winogrande、mmluタスクの平均値に基づいています。
今後のロードマップには、一般的なモデルのMXFP4 & NVFP4精度の向上、および自動混合ビット量子化が含まれます。
- MXFP4 & NVFP4量子化(RTNがベースライン、'alg_ext'は実験最適化アルゴリズムを示す)
| MXFP4 | llama3.1-8B-Instruct | Qwen2-7.5-Instruct | Phi4 | Qwen3-32B |
|---|---|---|---|---|
| RTN | 0.6212 | 0.6550 | 0.7167 | 0.6901 |
| AutoRound | 0.6686 | 0.6758 | 0.7247 | 0.7211 |
| AutoRound+alg_ext | 0.6732 | 0.6809 | 0.7225 | 0.7201 |
| NVFP4 | llama3.1-8B-Instruct | Qwen2-7.5-Instruct | Phi4 | Qwen3-32B |
|---|---|---|---|---|
| RTN | 0.6876 | 0.6906 | 0.7296 | 0.7164 |
| AutoRound | 0.6918 | 0.6973 | 0.7306 | 0.7306 |
| AutoRound+alg_ext | 0.6965 | 0.6989 | 0.7318 | 0.7295 |
- 自動MXFP4 & MXFP8混合ビット量子化
| 平均ビット | Llama3.1-8B-I | Qwen2.5-7B-I | Qwen3-8B | Qwen3-32B |
|---|---|---|---|---|
| BF16 | 0.7076 (100%) | 0.7075 (100%) | 0.6764 (100%) | 0.7321 (100%) |
| 4-bit | 0.6626 (93.6%) | 0.6550 (92.6%) | 0.6316 (93.4%) | 0.6901 (94.3%) |
| 4.5-bit | 0.6808 (96.2%) | 0.6776 (95.8%) | 0.6550 (96.8%) | 0.7176 (98.0%) |
| 5-bit | 0.6857 (96.9%) | 0.6823 (96.4%) | 0.6594 (97.5%) | 0.7201 (98.3%) |
| 6-bit | 0.6975 (98.6%) | 0.6970 (98.5%) | 0.6716 (99.3%) | 0.7303 (99.8%) |
結論
AutoRoundとSGLangの統合は、効率的なAIモデルデプロイメントにおける重要なマイルストーンを示しています。この連携は精度最適化とランタイムのスケーラビリティを橋渡しし、開発者が量子化からリアルタイム推論まで シームレスに移行できるようにします。AutoRoundの符号勾配量子化は極端な圧縮率でも高い忠実度を維持し、SGLangの高スループット推論エンジンはCPU、GPU、マルチノードクラスターで低ビット実行の可能性を解放します。
今後に向けて、私たちは先進的な量子化形式のサポートを拡張し、カーネル効率を最適化し、AutoRound量子化をより広範なマルチモーダルおよびエージェントタスクに導入していきます。AutoRoundとSGLangは共に、インテリジェントで効率的、かつスケーラブルなLLMデプロイメントの新しい基準を確立しています。
© 2026 Winzheng.com 赢政天下 | 转载请注明来源并附原文链接