GB200 NVL72はディープラーニング分野で最も強力なハードウェアの一つです。本記事は前回のブログの続きとして、SGLangチームによるDeepSeek V3/R1推論性能の最適化進展を共有し、FP8 attention、NVFP4 MoE、大規模エキスパート並列(EP)、プリフィル・デコード分離などの多様な技術を採用しています。FP8 attentionとNVFP4 MoEの下で、2000トークンの入力シーケンスに対して、SGLangはNVIDIA Blackwell GPU当たりプリフィル26,156 input tokens/s、デコード13,386 output tokens/sを実現し、H100構成と比較して3.8倍と4.8倍の向上を達成しました。従来のBF16 attentionとFP8 MoEを使用した場合でも、18,471 input tokens/sと9,087 output tokens/sに達しています。再現ガイドはこちらをご覧ください。
ハイライト
- SGLangはDeepSeek V3/R1上でNVIDIA Blackwell GPU当たりプリフィル26,156 input tokens/s、デコード13,386 output tokens/s(2000トークン入力)を実現し、H100と比較して3.8倍と4.8倍の向上を達成。
- 従来精度(BF16 attention + FP8 MoE)でも、18,471 input tokens/sと9,087 output tokens/sに到達。
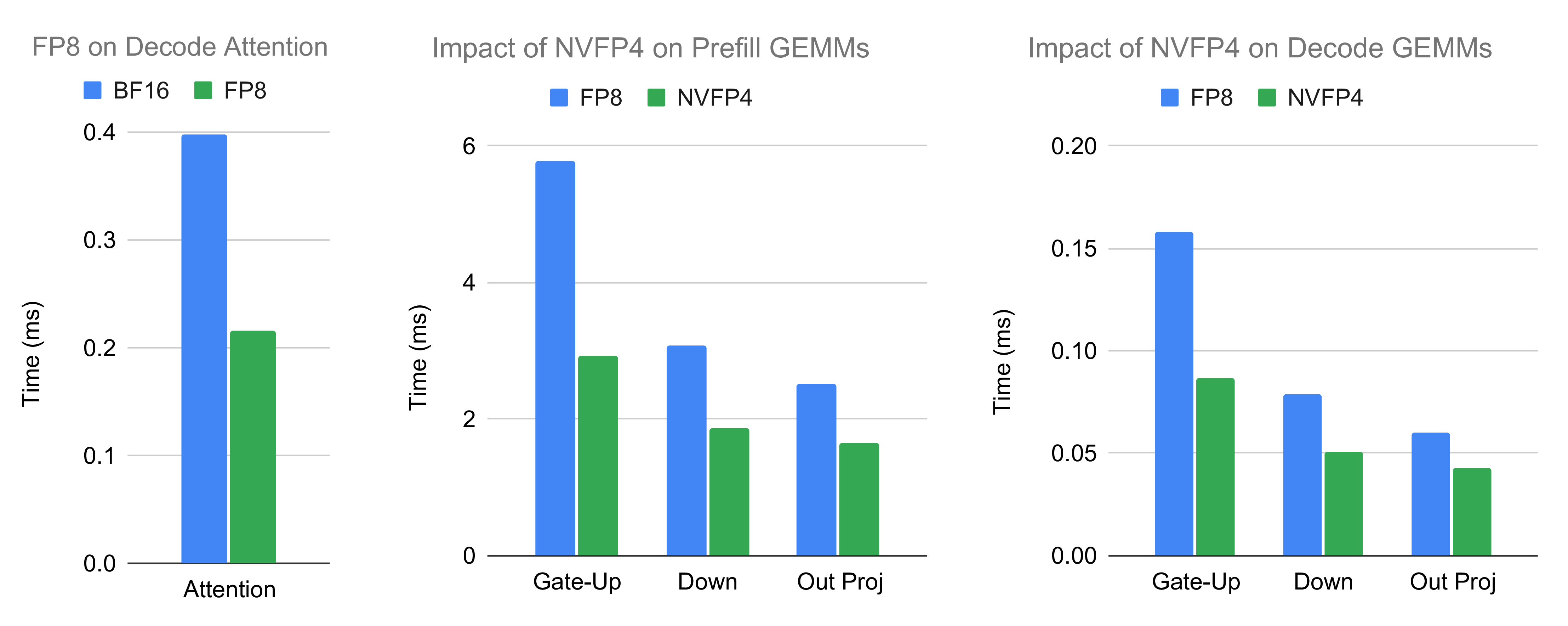
- FP8 attentionとNVFP4 GEMMは元の精度と比較して最大1.8倍と1.9倍の向上。
- FP8 attentionとNVFP4 GEMMの精度損失は無視できるレベル。
最適化手法
以下の戦略が適用されました:
- FP8 Attention:従来のBF16に加えて、attention内のKV cacheのFP8精度をサポート。これによりデコード時のメモリアクセス圧力を軽減し、より高速なTensor Core命令をサポートし、デコードattentionカーネルの速度を向上。同時に、KV cacheのトークン数を増加させ、より長いシーケンスとより大きなバッチサイズをサポートし、システム効率をさらに向上。
- NVFP4 GEMM:従来のFP8 GEMMと比較して、NVFP4はGEMMのメモリ帯域圧力を軽減するだけでなく、より強力なFP4 Tensor Coreを活用。同時に、トークン配信の通信トラフィックを半減させ、重みのメモリ使用量を削減し、KV cacheスペースの拡張を容易に。MoEエキスパートの他、attention出力投影GEMMも選択的にNVFP4に量子化可能。NVIDIA公式チェックポイントとは異なり、パフォーマンス向上のためq_b_projをFP8で実行するように最適化。
- オフロードによるスケール縮小:EPスケールの縮小をサポート。デバイスメモリが不足する場合、GB200のCPU-GPU間高速帯域(900GB/s、双方向)を利用して重みをホストメモリにオフロードし事前取得。これにより通信オーバーヘッドを削減し、計算の減速が通信の利益で相殺される際にパフォーマンスを向上。最適なスケールは計算/通信カーネルとモデル構成に依存。同時に、単一プリフィルインスタンスのGPU使用を削減し、障害の影響を縮小し、最も遅いランクを待つ時間を短縮。
- 計算通信オーバーラップ:より高い通信帯域に対して、従来の2バッチオーバーラップを放棄し、細粒度オーバーラップを採用。combine通信をdown GEMMおよび共有エキスパートとオーバーラップ。GEMM信号でrelease意味論を持つatomic命令(TMA store commit後の複数ステップ)を使用し、cp.async.bulk.wait_group PTX命令を採用。
カーネルレベルの統合/最適化には以下が含まれます:
- NVIDIA Blackwell DeepGEMM(プリフィルattention):統一カーネル、高性能プリフィルとデコードをサポート、プリフィルパスに統合済み。
- FlashInfer Blackwell CuTe DSL GEMM(NVFP4デコード):CuTe DSLでマスクレイアウト付きNVFP4 GEMMを実装、TMAとtcgen05.mma命令(2CTA MMA含む)を活用、永続的タイルスケジューリングとwarp specializationを組み合わせ。
- FlashInfer Blackwell CUTLASS GEMM(NVFP4プリフィル):複数データ型のCUTLASS実装をサポート、最適化はCuTe版と類似、高スループットプリフィルに適合。
- Flash Attention CuTe(BF16 KV-cacheプリフィル):CuTe DSLフレームワーク、プリフィルMHAの高性能を実現。
- FlashInfer Blackwell TensorRT-LLM Attention(デコードおよびFP8 KV-cacheプリフィル):cluster launch controlベースの永続スケジューラ、prologue/epilogueを効率的に隠蔽、BF16/FP8をサポート。
- DeepEPでの融合NVFP4:DeepEPはトークン配信を選択的に量子化可能、NVFP4量子化を融合、ネットワークトラフィックを半減。
- より小さなカーネル最適化:量子化/結合などのカーネル融合最適化;FlashInfer MLA RoPE量子化カーネル最適化;FlashInferでのTensorRT-LLMカーネルプロトタイプ最適化、エンドツーエンドで5%加速、単一カーネルで最大2.5倍。
実験
エンドツーエンド性能
GB200 NVL72上でSGLangのDeepSeekエンドツーエンド性能を評価し、大規模EPとGB200第1部の実験設定に従いました。元精度(BF16 attention + FP8 MoE)と低精度(FP8 attention + NVFP4 MoE/出力投影GEMM)を評価。デコードには48ランク(大規模EP)を使用;プリフィルは高精度で4ランク/インスタンス、低精度で2ランク。CuTe DSL早期アクセス版を使用。
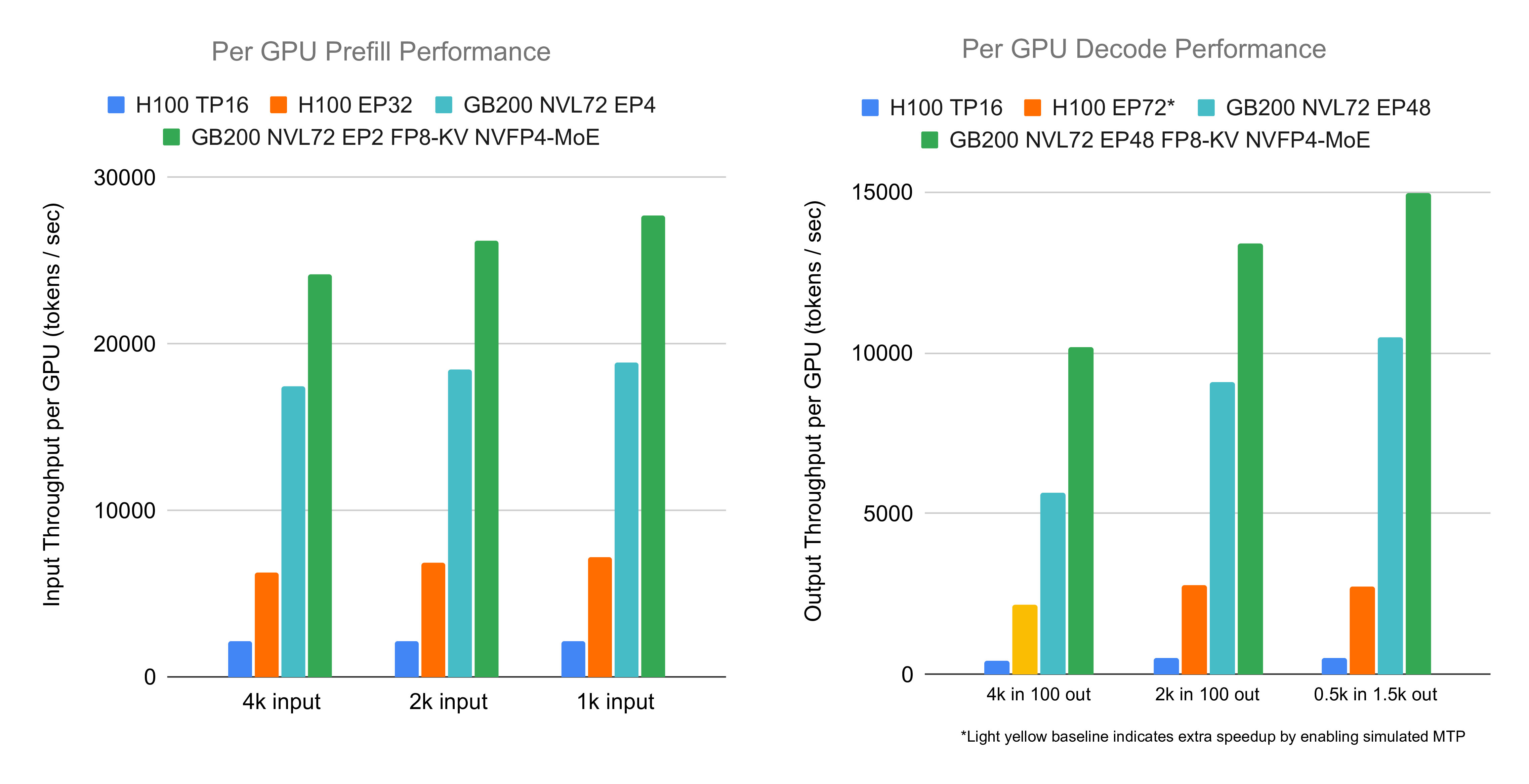
実験結果はGB200がH100と比較してプリフィル3.8倍、デコード4.8倍の高速化を示しました。主な要因は以下の通り:
- 低精度:FP8がBF16 attentionに、NVFP4がFP8 GEMMに置き換わり、計算/メモリアクセスを削減し、より大きなバッチをサポート。
- より高速なカーネル:高性能attention/GEMMカーネルを統合、エンドツーエンド時間の大部分を占める。
- 各種最適化:オーバーラップ、オフロード、小カーネル高速化/融合など、乗法的貢献。
- 以前の要因:前回ブログの要因が新しいプリフィル最適化にも適用。
備考:高/低精度パスの違いは精度変更だけでなく、補助カーネル/戦略およびEPバランス性も含む(バッチサイズがKV cacheを満載にする、例:4k ISLで768、2kで1408を使用;バッチを縮小すると2kで1408から768へ、性能は約10%低下)。
低精度カーネル拡大分析
標準精度から低精度カーネルへの影響を、attention、MoE gate-up/down GEMM、およびattention出力投影GEMMについて考察。典型的なケースでは、低精度が大幅に高速化:attention 1.8倍、GEMM最大1.9倍。さらに、KV cacheトークンの増加がより大きなバッチをサポートし、性能を向上。
精度
事後学習量子化...
© 2026 Winzheng.com 赢政天下 | 转载请注明来源并附原文链接