私たちは興奮とともに、SGLangがDeepSeek-V3.2のDay 0サポートを実現したことを発表します!DeepSeekの技術レポートによると、DeepSeek-V3.2は継続的な訓練を通じてDeepSeek-V3.1-TerminusにDeepSeek Sparse Attention (DSA)を搭載しました。これはLightning Indexerによって駆動される細粒度疎注意メカニズムで、特に長コンテキストシナリオにおいて訓練と推論効率の著しい向上を実現しています。今後リリース予定の機能にご興味がある方は、私たちのロードマップをご覧ください。
インストールとクイックスタート
すぐに始めるには、コンテナをプルして以下のようにSGLangを起動するだけです:
NVIDIA GPU
docker pull lmsysorg/sglang:v0.5.3-cu129
python -m sglang.launch_server --model deepseek-ai/DeepSeek-V3.2-Exp --tp 8 --dp 8 --enable-dp-attentionAMD (MI350X/MI355X)
docker pull lmsysorg/sglang:dsv32-rocm
SGLANG_NSA_FUSE_TOPK=false SGLANG_NSA_KV_CACHE_STORE_FP8=false SGLANG_NSA_USE_REAL_INDEXER=true SGLANG_NSA_USE_TILELANG_PREFILL=True python -m sglang.launch_server --model-path deepseek-ai/DeepSeek-V3.2-Exp --disable-cuda-graph --tp 8 --mem-fraction-static 0.85 --page-size 64 --nsa-prefill "tilelang" --nsa-decode "aiter"
SGLANG_NSA_FUSE_TOPK=false SGLANG_NSA_KV_CACHE_STORE_FP8=false SGLANG_NSA_USE_REAL_INDEXER=true SGLANG_NSA_USE_TILELANG_PREFILL=True python -m sglang.launch_server --model-path deepseek-ai/DeepSeek-V3.2-Exp --disable-cuda-graph --tp 8 --mem-fraction-static 0.85 --page-size 64 --nsa-prefill "tilelang" --nsa-decode "tilelang"
NPU
# NPU A2
docker pull lmsysorg/sglang:dsv32-a2
# NPU A3
docker pull lmsysorg/sglang:dsv32-a3
python3 -m sglang.launch_server --model-path deepseek-ai/DeepSeek-V3.2-Exp --trust-remote-code --attention-backend ascend --mem-fraction-static 0.85 --chunked-prefill-size 32768 --disable-radix-cache --tp-size 16 --quantization w8a8_int8詳細説明
DeepSeek Sparse Attention:長コンテキスト効率の解放
DeepSeek-V3.2の核心は DeepSeek Sparse Attention (DSA)です。これは長コンテキスト効率を再定義する細粒度疎注意メカニズムです。
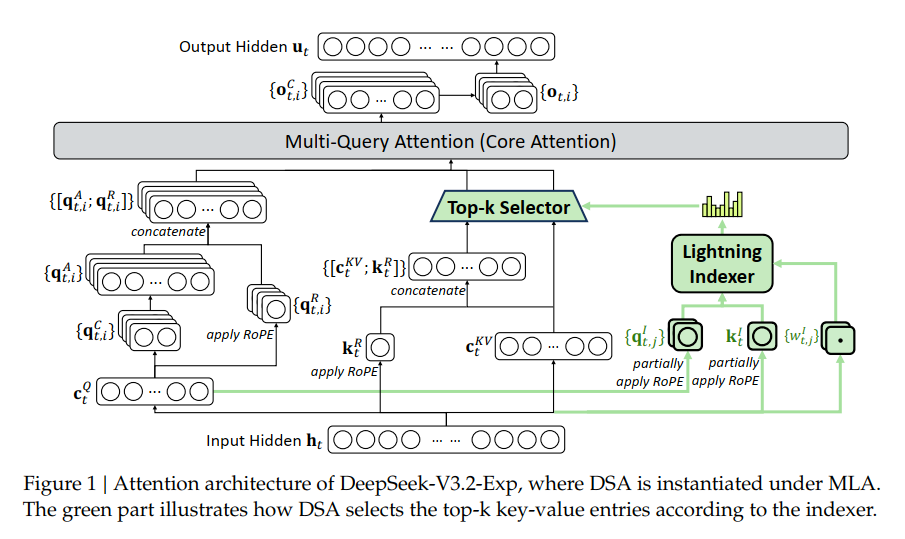
DSAは全トークンに対する二次の全注意計算を捨て、代わりに以下を導入しています:
- Lightning Indexer(超軽量FP8スコアラー)、各クエリに対して最も関連性の高いトークンを識別。
- Top-k Token Selection、最も影響力のあるkey-valueエントリに対してのみ計算を実行。
この設計により、コア注意の複雑度が O(L2)から O(Lk)に削減され、最大 128Kのコンテキスト長において、モデル品質をほぼ損なうことなく訓練と推論の著しい効率向上を実現しています。
この画期的な技術をサポートするため、SGLangは以下を実装・統合しました:
- Lightning Indexerサポート – メモリプールに専用の
key&key_scaleキャッシュを設け、超高速トークンスコアリングを実現。 - Native Sparse Attention (NSA)バックエンド – 疎負荷用に設計された新しいバックエンド、以下を含む:
- FlashMLA(DeepSeek最適化マルチクエリ注意カーネル)
- FlashAttention-3 Sparse(互換性のための適応とカーネル再利用の最大化)
- 追加の最適化:同じ注意バックエンド内での異なるページサイズのサポート:
- Indexer
key&key_scaleキャッシュはページサイズ = 64が必要(DeepSeek提供のカーネルから) - トークンレベル疎フォワード演算子はページサイズ = 1が必要
- Indexer
これらの革新により、DeepSeek-V3.2-Expは GPU最適化疎注意 と 動的キャッシュ管理を実現し、メモリオーバーヘッドを大幅に削減し、128Kコンテキストまでシームレスに拡張できます。最終的な結果は、最先端の推論品質を保持しながら 推論コストを大幅に削減することです — 長コンテキストLLMの展開を実現可能にするだけでなく、大規模な実用性も持たせています。
今後の作業
今後の作業はこちらで追跡されます。具体的な計画には以下が含まれます:
- Multi-token Prediction (MTP)サポートが近日公開:MTPは特にバッチサイズが大きくない場合にデコードを加速します。
- FP8 KVキャッシュ:従来のBF16 KVキャッシュと比較して、KVキャッシュ内のトークン数をほぼ倍増でき、注意カーネルのメモリアクセス圧力を半減させ、より長いコンテキストやより多くのリクエストをより速く処理できます。
- TileLangサポート:TileLangカーネルは柔軟な開発に役立ちます。
謝辞
私たちは、オープンソースコミュニティに多大な恩恵をもたらすオープンソースモデル研究における顕著な貢献と、彼らの効率的なカーネルのSGLang推論エンジンへの統合について、DeepSeekチームに心から感謝します。
DeepSeek-V3.2-Expサポートへの貢献について、SGLangコミュニティメンバーのTom Chen、Ziyi Xu、Liangsheng Yin、Biao He、Baizhou Zhang、Henry Xiao、Hubert Lu、Wun-guo Huang、Zhengda Qin、Fan Yinに感謝します。
また、この作業の開発に使用したGPUマシンを提供してくださったNVIDIA、AMD、Nebius Cloudに感謝します。
© 2026 Winzheng.com 赢政天下 | 转载请注明来源并附原文链接