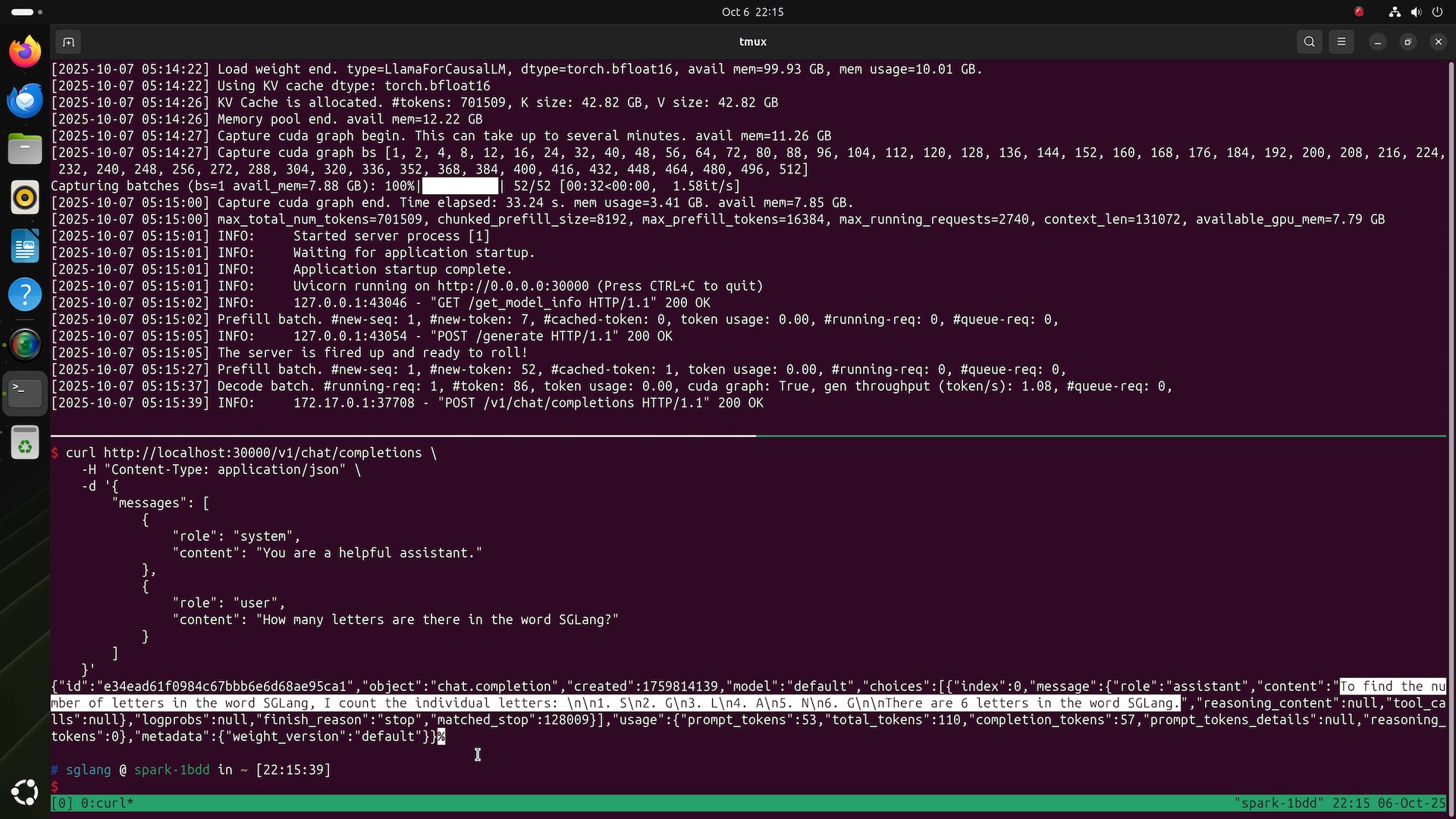
NVIDIAの早期アクセスプログラムのおかげで、私たちはNVIDIA DGX™ Sparkを実際に触る機会を得ました。これは非常に珍しいシステムです。なぜなら、NVIDIAがこれほどコンパクトなオールインワンマシンを発表することは稀で、スーパーコンピューティングレベルの性能をデスクトップワークステーション形態に凝縮しているからです。
過去1年間、SGLangはデータセンター分野で開発者コミュニティを急速に拡大し、優れた推論性能で知られるようになりました。Prefill-decode Disaggregation (PD)とExpert Parallelism (EP)を使用してDeepSeekを成功裏にデプロイし、96枚のNVIDIA H100 GPUクラスタと最新のGB200 NVL72システム上で動作させ、大規模推論性能と開発者の生産性の限界を絶えず押し上げています。
DGX Sparkに触発され、SGLangは初めてデータセンターからコンシューマー市場へと拡張し、成熟した推論フレームワークを世界中の開発者と研究者に直接提供します。本レビューでは、この美しいデバイスを外観の美学から性能、応用シナリオまで詳細に検証します。
ビデオレビューもご覧ください こちら。

外観デザイン
DGX Sparkはエンジニアリング美学の傑作です。オールメタルボディはシャンパンゴールドのブラッシュ仕上げを採用し、前後パネルには金属フォーム工法を使用しており、NVIDIA DGX A100とH100のデザインを彷彿とさせます。
背面のインターフェースは豊富です:電源ボタン、4つのUSB-Cポート(最左端は最大240W電力出力をサポート)、HDMIポート、10 GbE RJ-45イーサネットポート、そしてNVIDIA ConnectX-7 NICによって駆動される2つのQSFPポート(最大200 Gbps)があります。これらのインターフェースにより、2台のDGX Sparkを相互接続して、より大きなAIモデルを実行できます。
USB Type-C給電設計は独特で、他のデスクトップマシンではほとんど見られません。Mac MiniやMac StudioのC5/C7電源プラグと比較して、USB-Cは電源を外部に配置し、内部の冷却スペースを確保します。ただし、誤って電源を抜かないよう注意が必要です。

ハードウェア仕様
ハードウェア面では、DGX Sparkはコンパクトな体積と消費電力で優れた性能を発揮します。コアは本機専用に設計されたNVIDIA GB10 Grace Blackwell Superchipで、10個のCortex-X925パフォーマンスコアと10個のCortex-A725効率コアを統合し、合計20個のCPUコアを持ちます。
GPU側では、GB10は最大1 PFLOP スパースFP4テンソル性能を提供し、AI能力はRTX 5070と5070 Tiの間に位置します。ハイライトは128 GBのコヒーレント統合システムメモリで、CPUとGPUがシームレスに共有し、システムからVRAMへのデータ転送オーバーヘッドを回避します。デュアルQSFPイーサネットポート(集約200 Gb/s帯域幅)により、2台のデバイスで小規模クラスタを構成し、より大きなモデルの分散推論をサポートできます。NVIDIAによると、相互接続された2台のDGX Sparkは最大4050億パラメータのFP4モデルを処理できます。
唯一の弱点はメモリ帯域幅で、統合メモリはLPDDR5xで最大273 GB/s、CPU/GPUで共有されており、後続のテストでこれがAI推論の主なボトルネックであることが確認されました。それでも、128 GBのメモリにより、ほとんどのデスクトップシステムでは扱えない大規模モデルを実行できます。

性能テスト
私たちはSGLangとOllamaを使用してDGX Spark上で複数のオープンソース大規模言語モデルのベンチマークテストを実施しました。結果は、GPT-OSS 120BやLlama 3.1 70Bなどの超大型モデルをロード・実行できることを示していますが、本番環境よりもプロトタイプ開発と実験により適していることがわかりました。小型モデルでは、特にバッチ処理を有効にした場合、優れた性能を発揮します。
テスト方法
⚠️ 注意:ソフトウェアサポートはまだ初期段階にあり、ベンチマーク結果は将来のアップデートで古くなる可能性があります。
テスト機器
- NVIDIA DGX Spark
- NVIDIA RTX PRO™ 6000 Blackwell Workstation Edition
- NVIDIA GeForce RTX 5090 Founders Edition
- NVIDIA GeForce RTX 5080 Founders Edition
- Apple Mac Studio (M1 Max, 64 GB 統合メモリ)
- Apple Mac Mini (M4 Pro, 24 GB 統合メモリ)
ベンチマークモデル
SGLangとOllamaを使用して複数のオープンソースLLMを評価:
| フレームワーク | バッチサイズ | モデル & 量子化 |
|---|---|---|
| SGLang | 1–32 | Llama 3.1 8B (FP8) Llama 3.1 70B (FP8) Gemma 3 12B (FP8) Gemma 3 27B (FP8) DeepSeek-R1 14B (FP8) Qwen 3 32B (FP8) |
| Ollama | 1 | GPT-OSS 20B (MXFP4) GPT-OSS 120B (MXFP4) Llama 3.1 8B (q4_K_M / q8_0) Llama 3.1 70B (q4_K_M) Gemma 3 12B (q4_K_M / q8_0) Gemma 3 27B (q4_K_M / q8_0) DeepSeek-R1 14B (q4_K_M / q8_0) Qwen 3 32B (q4_K_M / q8_0) |
また、一部のモデルでspeculative decoding (EAGLE3) with SGLangをテストし、メモリ容量を超えるモデルは除外しました。
テスト結果
完全な結果は こちらをご覧ください。
全体的な性能
DGX Sparkは体積と消費電力の点でエンジニアリングが優れていますが、生の性能は独立GPUシステムに及びません。例えば、Ollama GPT-OSS 20B (MXFP4)では、Sparkは2,053 tps prefill / 49.7 tps decodeを達成しましたが、RTX Pro 6000 Blackwellは10,108 tps / 215 tpsを達成し、約4倍高速です。RTX 5090も8,519 tps / 205 tpsを達成しました。統合LPDDR5x帯域幅が主な制限要因です。
小型モデルのLlama 3.1 8Bでは、SGLang batch 1で7,991 tps prefill / 20.5 tps decodeを達成し、batch 32では線形にスケールして7,949 tps / 368 tpsとなり、バッチ処理効率が優れています。
統合メモリの利点
128 GBのコヒーレント統合メモリが核心的な特徴で、CPUとGPUがアドレス空間を共有します。Llama 3.1 70B、Gemma 3 27B、GPT-OSS 120Bなどの大規模モデルを転送オーバーヘッドなしで直接ロードできます。Llama 3.1 70B (FP8)は803 tps prefill / 2.7 tps decodeを達成し、デスクトップレベルでは驚異的です。プロトタイプ開発、モデル実験、エッジAI研究に適しています。
投機的デコーディングによる高速化
SGLang EAGLE 3投機的デコーディングを有効にすると、小型モデルが「ドラフト」トークンを事前生成し、大型モデルが並列に検証することで、Llama 3.1 8Bなどの複数モデルでエンドツーエンドのスループットが最大2倍向上します。ソフトウェア最適化が帯域幅ボトルネックを効果的に緩和します。
効率と放熱
高負荷下でも熱スロットリングは発生せず、例えばSGLang DeepSeek-R1 14B (FP8) batch 8では2,074 tps / 83.5 tpsを達成し、ファンノイズと温度は安定しています。これは金属フォーム冷却と最適化された電源供給によるものです。USB-C 240W入力 + 外部PSUはより大きな熱的余裕を提供し、Mac Mini/Studioより優れています。

まとめ
DGX Sparkはフルサイズのe Blackwell/Ada GPUと正面から競うためのものではなく、DGX体験を開発者にとって親しみやすいコンパクトな形態に凝縮したものです。理想的な用途:
- モデルのプロトタイピングと実験
- 軽量デバイス端末推論
- メモリコヒーレントGPUアーキテクチャ研究
これは使いやすさと引き換えに生の性能を犠牲にした、美しくエンジニアリングされたミニスーパーコンピューターです。
© 2026 Winzheng.com 赢政天下 | 转载请注明来源并附原文链接