私たちはSGLang-Jaxを興奮を持って発表します。これはJaxとXLAに完全に基づいて構築された最先端のオープンソース推論エンジンです。
これはSGLangの高性能サーバーアーキテクチャを参考にし、Jaxを利用してモデルのフォワードパスをコンパイルします。SGLangとJaxを組み合わせることで、このプロジェクトは高速なネイティブTPU推論を実現しながら、連続バッチ処理(continuous batching)、プレフィックスキャッシュ(prefix caching)、テンソル並列(tensor parallelism)、エキスパート並列(expert parallelism)、推測デコード(speculative decoding)、カーネル融合(kernel fusion)、および高度に最適化されたTPUカーネルなどの高度な機能を保持しています。
ベンチマークテストでは、SGLang-Jaxの性能が他のTPU推論ソリューションに匹敵またはそれを上回ることが示されています。ソースコードはGitHubで入手可能です。
なぜJaxバックエンドを選ぶのか?
SGLangは当初PyTorchに基づいて構築されましたが、コミュニティは常にJaxサポートを期待してきました。私たちがJaxバックエンドを開発した主な理由は以下の通りです:
- Jaxは設計当初からTPU向けに最適化されており、究極の性能を追求するための最良の選択です。GoogleがTPUのパブリックアクセスを拡大するにつれ、Jax + TPUの組み合わせは広く採用され、コスト効率の高い推論を実現します。
- Google DeepMind、xAI、Anthropic、Appleなどの主要AIラボはすでにJaxに依存しています。トレーニングと推論のフレームワークを統一することで、メンテナンスコストを削減し、2段階のドリフトを回避できます。
- Jax + XLAは成熟したコンパイル駆動型スタックで、TPUで優れたパフォーマンスを発揮し、TPUに似た様々なカスタムAIチップにも適用できます。
アーキテクチャ
下図はSGLang-Jaxのアーキテクチャを示しており、スタック全体が純粋なJax実装で、コードは簡潔で依存関係は最小限です。
入力側ではOpenAI互換APIをサポートし、SGLangの効率的なRadixCacheを利用してプレフィックスキャッシュを実装し、オーバーラップスケジューラ(overlap scheduler)を採用して低オーバーヘッドのバッチ処理を実現しています。スケジューラは異なるバッチサイズに対してJax計算グラフを事前コンパイルします。モデル側はFlaxに基づいて実装され、shard_mapを使用して複数の並列戦略をサポートしています。コアオペレータ—アテンション(attention)とMoE—はカスタムPallasカーネルで実装されています。
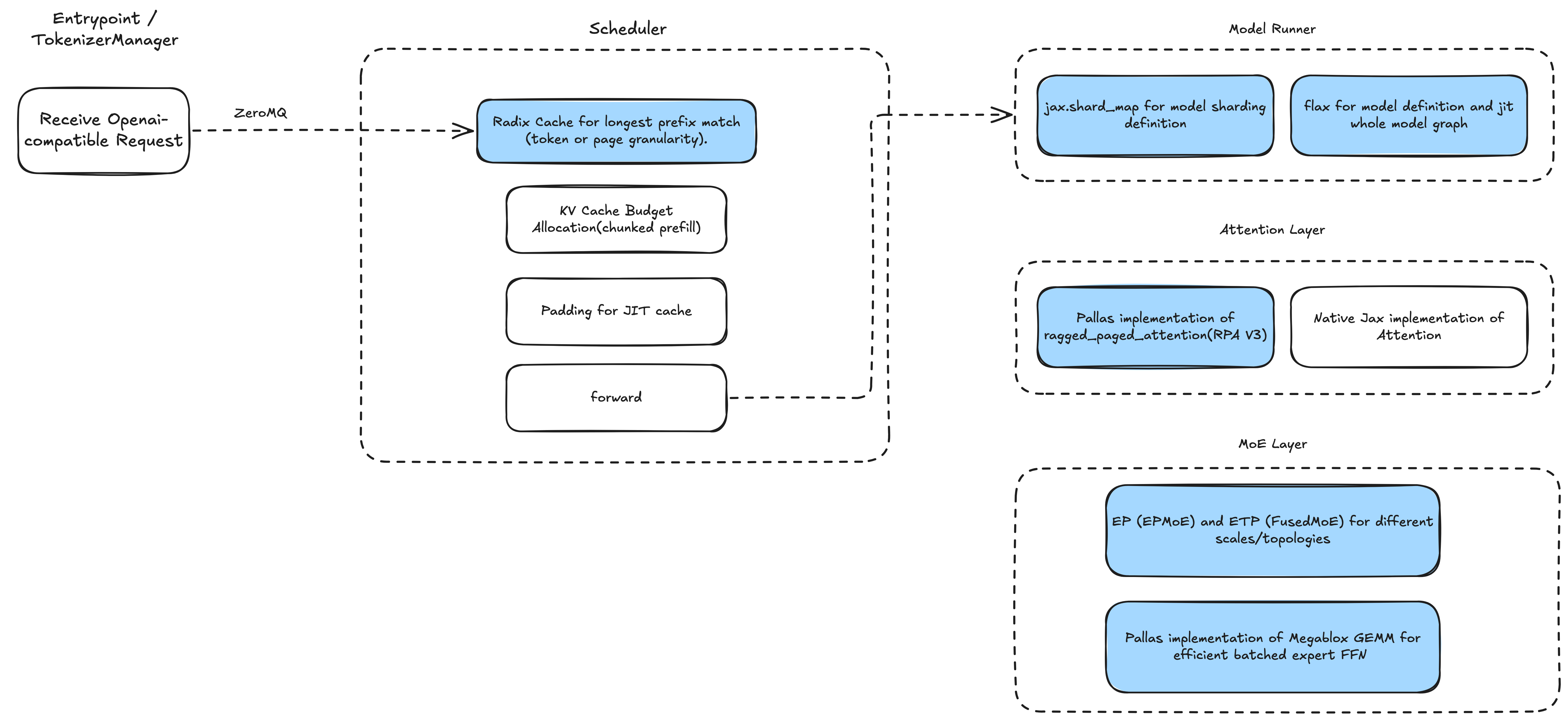
SGLang-Jaxアーキテクチャ図
主要な最適化
Ragged Paged Attention v3の統合
私たちはRagged Paged Attention v3(RPA v3)を統合し、SGLang機能のサポートを拡張しました:
- 異なるシナリオに応じてカーネルグリッドブロック構成を調整し、性能を向上させました。
- RadixCacheとの互換性。
- EAGLE推測デコードをサポートするため、検証段階でカスタムマスクを追加しました。
スケジューリングオーバーヘッドの削減
フォワードパスにおけるCPUとTPUの逐次操作は性能に影響を与える可能性があります。しかし、異なるデバイスの操作は分離できます。例えば、TPUが計算を開始すると同時に、CPUはすぐに次のバッチを準備できます。性能を向上させるため、スケジューラはCPU処理とTPU計算をオーバーラップさせます。
オーバーラップイベントループでは、スケジューラは結果キューとスレッドイベントを使用してCPUとTPUの作業をパイプライン化します。TPUがバッチNを処理している間、CPUはバッチN+1を準備します。プロファイリング結果を通じて操作シーケンスを最適化することで、Qwen/Qwen3-32Bの場合、プレフィルとデコード間のギャップは約12msから38μsに、約7msから24μsに短縮されました。詳細は前のブログ記事をご覧ください。

オーバーラップスケジューラを有効にしたプロファイル図、バッチ間のギャップは極めて小さい。
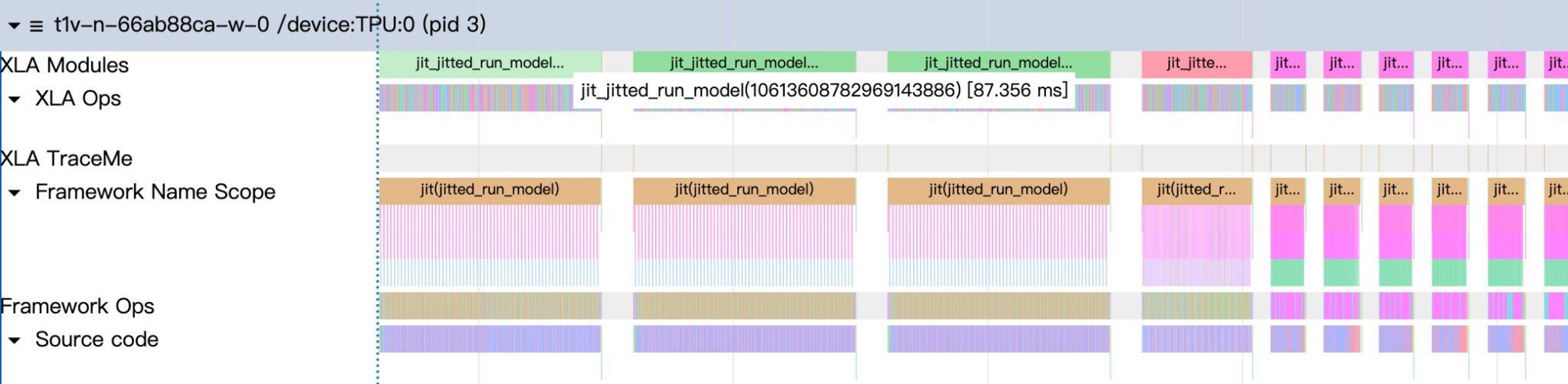
オーバーラップスケジューラを無効にしたプロファイル図、バッチ間に明らかなCPUオーバーヘッドギャップが存在。
MoEカーネル最適化
MoEレイヤーは2つの戦略をサポートしています:EPMoEとFusedMoE。EPMoEはMegablox GMMオペレータを統合し、以前のragged_dot実装を置き換えます。Megablox GMMはMoE専用に設計され、可変長エキスパートグループを効率的に処理し、不要な計算と非連続メモリアクセスを回避し、エンドツーエンド(e2e)ITL速度を3〜4倍向上させます。効率的なトークン配置、ragged_all_to_allエキスパート並列通信、適応タイリングと組み合わせることで、スループットが大幅に向上し、特にデバイス間の複数エキスパートシナリオに適しています。FusedMoEはすべてのエキスパート計算を融合し、密なeinsum操作を使用し、通信オーバーヘッドがなく、個々のエキスパートが大きいが総数が少ない(<64)シナリオに適しており、軽量デバッグの代替手段としても機能します。
推測デコード
SGLang-JaxはEAGLEに基づく推測デコード、つまりマルチトークン予測(Multi-Token Prediction、MTP)を実装しています。この技術は軽量ドラフトヘッドを使用してマルチトークンを予測し、単一の完全モデルパスで並列検証を行って生成を高速化します。ツリー状のMTP-Verifyを実現するため、Ragged Paged Attention V3に非因果マスクサポートを追加し、検証段階での並列デコードをサポートしています。現在Eagle2とEagle3をサポートしており、将来的にカーネルを最適化し、アテンションバックエンドのサポートを拡張する予定です。
TPU性能
最適化後、SGLang-Jaxは他のTPU推論ソリューションに匹敵またはそれを上回り、GPUソリューションと比較しても非常に競争力があります。完全なベンチマーク結果と説明はGitHub issueをご覧ください。
使用ガイド
SGLang-Jaxのインストールとサーバーの起動
インストール:
# uvを使用
uv venv --python 3.12 && source .venv/bin/activate
uv pip install sglang-jax
# ソースから
git clone https://github.com/sgl-project/sglang-jax
cd sglang-jax
uv venv --python 3.12 && source .venv/bin/activate
uv pip install -e python/サーバーの起動:
MODEL_NAME="Qwen/Qwen3-8B" # または "Qwen/Qwen3-32B"
jax_COMPILATION_CACHE_DIR=/tmp/jit_cache \
uv run python -u -m sgl_jax.launch_server \
--model-path ${MODEL_NAME} \
--trust-remote-code \
--tp-size=4 \
--device=tpu \
--mem-fraction-static=0.8 \
--chunked-prefill-size=2048 \
--download-dir=/tmp \
--dtype=bfloat16 \
--max-running-requests 256 \
--page-size=128GCPコンソール経由でのTPU使用
メニュー→Compute EngineでTPUの作成を選択します。特定のリージョンでのみ特定のTPUバージョンがサポートされていることに注意し、ソフトウェアバージョンをv2-alpha-tpuv6eに設定します。Compute Engine→Settings→MetadataでSSH公開鍵を追加します。作成後、コンソールに表示される外部IPと公開鍵のユーザー名を使用してログインします。詳細はGCPドキュメントをご覧ください。
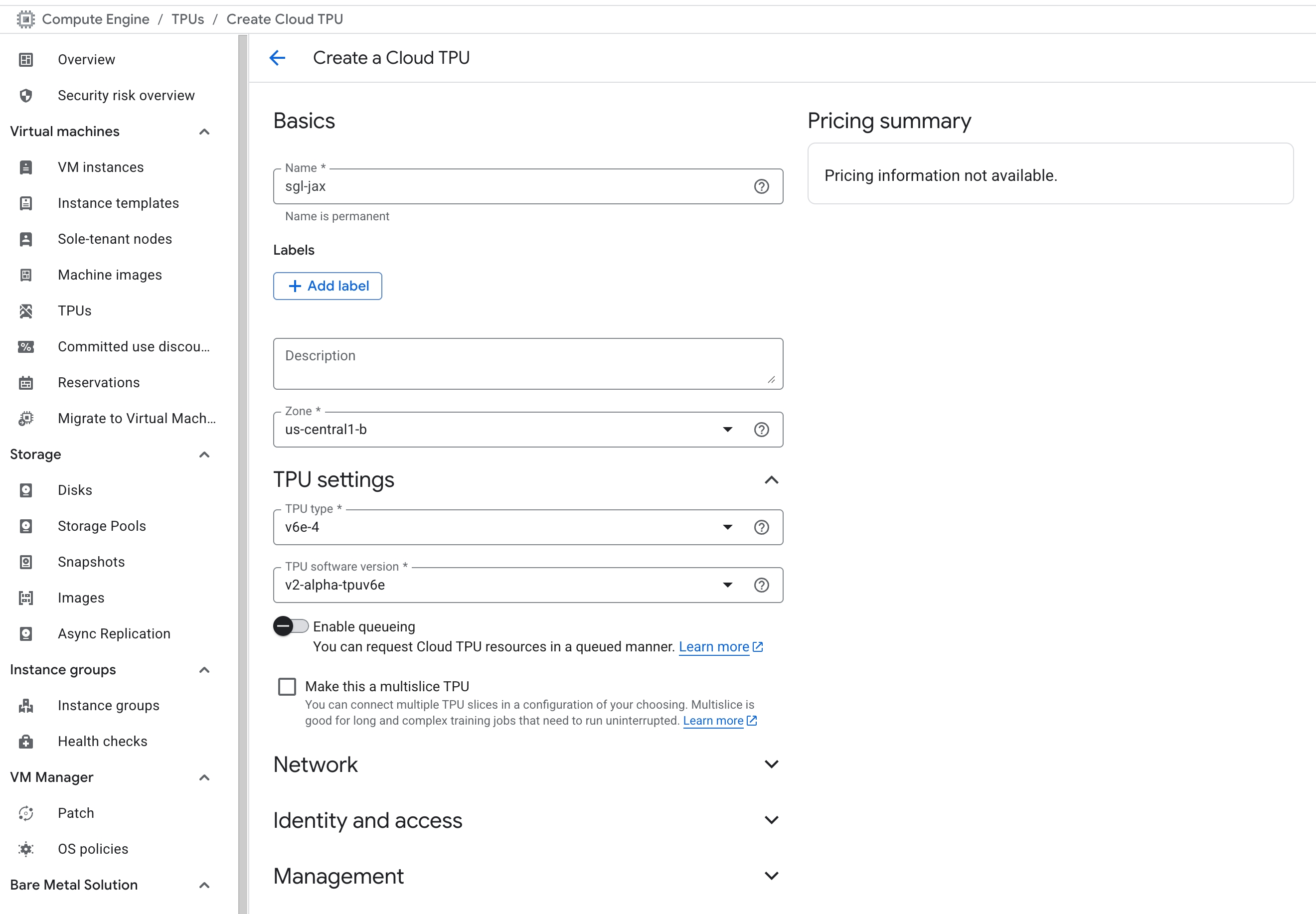
SkyPilot経由でのTPU使用
日常的な開発にはSkyPilotの使用を推奨します。GCP版SkyPilotをインストール後、リポジトリ内のsgl-jax.sky.yamlを実行します:
sky launch sgl-jax.sky.yaml --cluster=sgl-jax-skypilot-v6e-4 --infra=gcp -i 30 --down -y --use-spotこのコマンドは自動的に最も低コストのTPUスポットインスタンスを選択し、30分間アイドル状態になると停止し、sglang-jax環境を事前インストールします。完了後、直接ssh cluster_nameでログインできます。
将来のロードマップ
コミュニティはGoogle Cloudおよびパートナーと協力して以下の計画を推進しています:
- モデルサポートと最適化:Grok2、Ling/Ring、DeepSeek V3、GPT-OSSの最適化;MiMo-Audio、Wan 2.1、Qwen3 VLのサポート。
- TPU最適化カーネル:量子化カーネル、通信計算オーバーラップカーネル、MLAカーネル。
- RL統合とtunix:ウェイト同期、Pathwaysおよびマルチホストサポート。
- 高度なサービング機能:プレフィル-デコード分離、階層化KVキャッシュ、マルチLoRAバッチ処理。
謝辞
SGLang-Jaxチーム:sii-xinglong, jimoosciuc, Prayer, aolemila, JamesBrianD, zkkython, neo, leos, pathfinder-pf, Jiacheng Yang, Hongzhen Chen, Ying Sheng, Ke Bao, Qinghan Chen
Google:Chris Yang, Shun Wang, Michael Zhang, Xiang Li, Xueqi Liu
InclusionAI:Junping Zhao, Guowei Wang, Yuhong Guo, Zhenxuan Pan
© 2026 Winzheng.com 赢政天下 | 转载请注明来源并附原文链接