(12月2日更新)
SGLangに重要な新機能が追加されたことを喜んでお知らせします:NVIDIA Model Optimizerのネイティブ量子化サポート!この統合により、モデルの最適化とデプロイメントのプロセス全体が最適化され、SGLangエコシステム内でフルプレシジョンモデルから高性能量子化エンドポイントに直接変換できるようになりました。
大規模言語モデル(LLM)の効率的なサービング提供は、本番環境における最大の課題の一つです。モデル量子化は、メモリ使用量を削減し、推論速度を向上させる重要な技術です。これまで、このプロセスには複数ステップのワークフローと独立したツールが必要でした。今回の最新アップデート(PRs #7149、#9991、#10154)により、これらの複雑さを完全に解消しました。
Model OptimizerとSGLangの最適化の組み合わせにより、NVFP4およびFP8推論において、単一GPUで最大2倍のスループット向上を実現できます。
新機能:SGLangにおける直接ModelOpt API
SGLangはNVIDIA Model Optimizerを直接統合し、SGLangコード内でその強力な量子化APIを呼び出せるようになりました。
この新機能により、簡素化された3ステップのワークフローが可能になります:
- 量子化:SGLang-ModelOptインターフェースを使用して高度な量子化技術を適用し、NVFP4、MXFP4、FP8などの低精度推論の高速化をサポート。
- エクスポート:最適化されたモデルファイルを保存し、SGLangランタイムと完全に互換性を維持。
- デプロイ:量子化モデルをSGLangランタイムで直接ロードし、NVIDIAプラットフォームでサービング提供し、即座により低いレイテンシとメモリ節約を享受。
パフォーマンス成果
新しいAPIで最適化されたモデルは、著しいパフォーマンス向上をもたらします。これらの最適化は、他のNVIDIAソフトウェア・ハードウェアスタックコンポーネントと組み合わせることができ、DGX SparkからGB300 NVL72まで、最新のBlackwellアーキテクチャの様々な形態に適用できます。
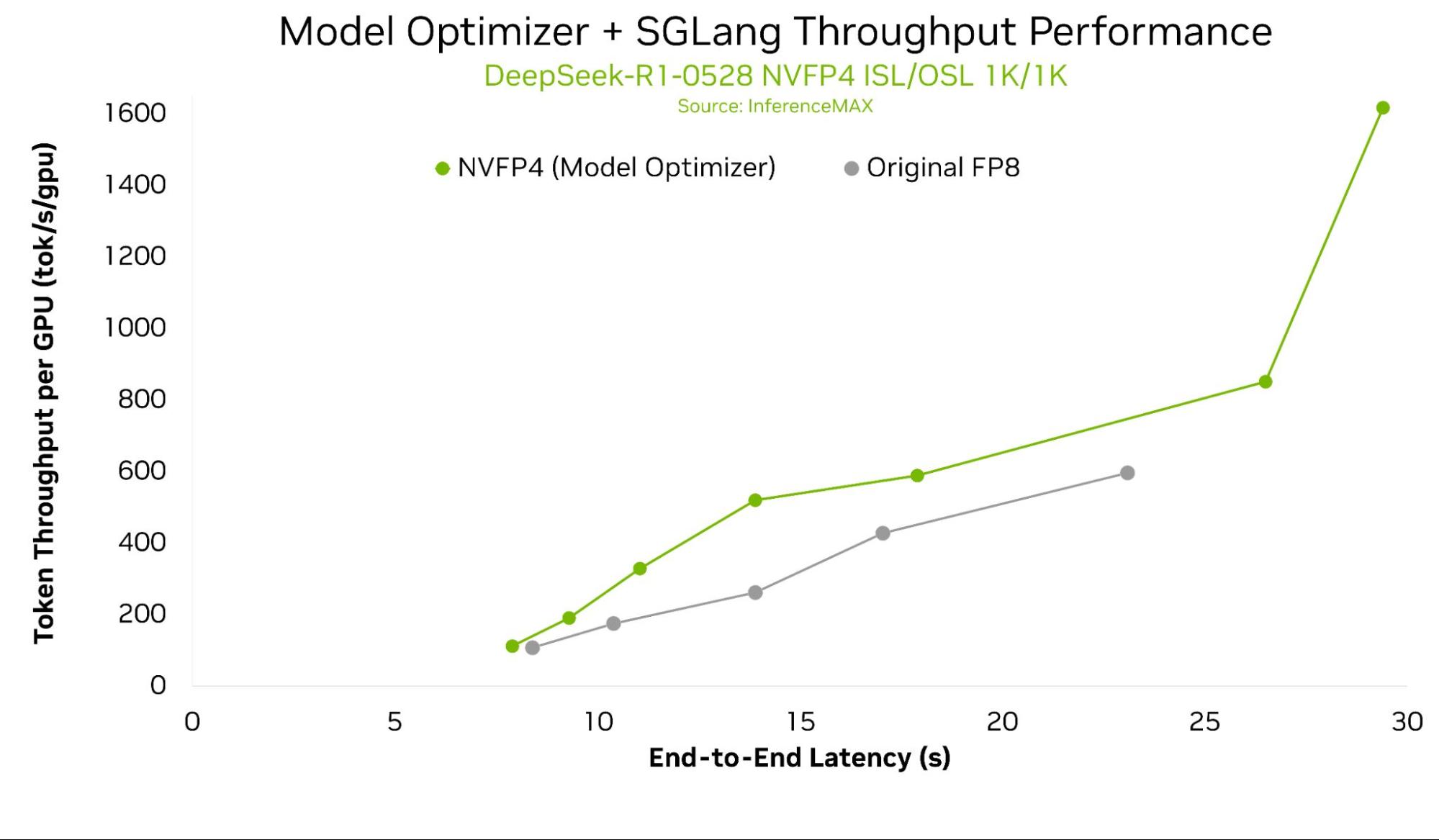
上図は、NVIDIA B200単一GPUスループット vs エンドツーエンドレイテンシを示しており、DeepSeek-R1-0528の複数構成について、Model Optimizer NVFP4量子化モデルを使用し、ネイティブFP8およびNVFP4と比較しています。(DeepSeek-R1-0528は本APIの初期リリースでは現在サポートされていません)
根据InferenceMAX最新结果,Model OptimizerとSGLangの最適化により、ネイティブFP8ベースラインと比較して最大2倍の単一GPUスループットを実現できます。これらのパフォーマンス向上は、本ブログで説明するネイティブ統合によってまもなく実現される予定です。
クイックスタートガイド
SGLangは完全なModel Optimizer量子化とエクスポートのプロセスを示すサンプルスクリプトを提供しています。SGLang環境でnvidia-modeloptとaccelerateをインストールしてから、以下のコードスニペットを実行してください:
import sglang as sgl
from sglang.srt.configs.device_config import DeviceConfig
from sglang.srt.configs.load_config import LoadConfig
from sglang.srt.configs.model_config import ModelConfig
from sglang.srt.model_loader.loader import get_model_loader
# モデルを設定し、ModelOptで量子化してエクスポート
model_config = ModelConfig(
model_path="Qwen/Qwen3-8B",
quantization="modelopt_fp8", # または "modelopt_fp4"
trust_remote_code=True,
)
load_config = LoadConfig(
modelopt_export_path="./quantized_qwen3_8b_fp8",
modelopt_checkpoint_save_path="./checkpoint.pth", # オプション、疑似量子化チェックポイント
)
device_config = DeviceConfig(device="cuda")
# モデルをロードして量子化(エクスポートは自動的に実行)
model_loader = get_model_loader(load_config, model_config)
quantized_model = model_loader.load_model(
model_config=model_config,
device_config=device_config,
)量子化後のエクスポートが完了したら、SGLangでモデルをデプロイできます:
# エクスポートされた量子化モデルをデプロイ
python -m sglang.launch_server \
--model-path ./quantized_qwen3_8b_fp8 \
--quantization modelopt \
--port 30000 --host 0.0.0.0またはPython APIを使用:
import sglang as sgl
from transformers import AutoTokenizer
def main():
# エクスポートされたModelOpt量子化モデルをデプロイ
llm = sgl.Engine(
model_path="./quantized_qwen3_8b_fp8",
quantization="modelopt"
)
# Qwen3-8Bチャットテンプレートでプロンプトをフォーマット
tokenizer = AutoTokenizer.from_pretrained("./quantized_qwen3_8b_fp8")
messages = [
[{"role": "user", "content": "Hello, how are you?"}],
[{"role": "user", "content": "What is the capital of France?"}]
]
prompts = [
tokenizer.apply_chat_template(m, tokenize=False, add_generation_prompt=True)
for m in messages
]
# 推論を実行
sampling_params = {"temperature": 0.8, "top_p": 0.95, "max_new_tokens": 512}
outputs = llm.generate(prompts, sampling_params)
for i, output in enumerate(outputs):
print(f"Prompt: {prompts[i]}")
print(f"Output: {output['text']}")
if __name__ == "__main__":
main()まとめ
このネイティブModel Optimizer統合は、SGLangがLLM推論のためのシンプルで強力なプラットフォームであるという約束を強化します。私たちは高性能モデル最適化とデプロイメント間のギャップを縮小し続けます。
この新機能で実現されるパフォーマンス向上を楽しみにしています!GitHubリポジトリにアクセスして最新版をプルし、お試しください。
専用のSlackチャンネル#modeloptに参加して、modelopt、量子化、低精度数値に関するトピックについて議論しましょう!ワークスペースに参加していない場合は、こちらから参加してください。
謝辞
NVIDIAチーム:Zhiyu Cheng, Jingyu Xin, Huizi Mao, Eduardo Alvarez, Pen Chung Li, Omri Almog
SGLangチームとコミュニティ:Qiaolin Yu, Xinyuan Tong
© 2026 Winzheng.com 赢政天下 | 转载请注明来源并附原文链接