はじめに
最近、SGLang RLチームはRLトレーニングの安定性、効率性、応用シナリオにおいて重要な進展を遂げました:
- INT4 QATエンドツーエンドトレーニング:トレーニングから推論までの完全なQAT INT4クローズドループソリューションを実現し、詳細な技術レシピを提供し、デプロイ効率と安定性を大幅に向上させました。
- 統一マルチターンVLM/LLMトレーニング:VLMマルチターンサンプリングパラダイム実装ブログを提供し、開発者はカスタム
rollout関数を書くだけで、LLMトレーニングと同様に簡単にVLMマルチターンRLを開始できます。 - Rollout Router Replay:Rollout Router Replayメカニズムを実装し、MoEモデルのRLトレーニング安定性を大幅に向上させました。
- FP8エンドツーエンドトレーニング:RLシナリオでエンドツーエンドFP8トレーニングとサンプリングを成功裏に実装し、ハードウェアパフォーマンスをさらに解放しました。
- RLにおける投機的デコーディング:RLシナリオでspeculative samplingを成功裏に実践し、大規模トレーニングの無損失加速を実現しました。
これらの基盤の上で、我々はさらに一歩進み:slimeフレームワークでエンドツーエンドINT4 QATソリューションを再現・デプロイしました:INT4 Quantization-Aware Training (QAT)。このソリューションはKimiチームのK2-Thinking技術レポートおよびそのW4A16 QAT実践に深く触発されました:W4A16 QAT。先駆者への敬意とコミュニティへの還元として、本稿ではオープンソースエコシステム下での完全パイプライン構築の技術詳細を解析し、安定性とパフォーマンスを兼ね備えた実用的な参考を提供します。
主要な利点一覧:
- メモリボトルネックの打破:重み圧縮と低ビット量子化により、約1TB規模のK2系モデルを単一H200(141GB)GPUに圧縮し、ノード間通信ボトルネックを回避。
- トレーニングと推論の一貫性:トレーニングではQATで重みをINT4フレンドリーな分布に形成;推論ではW4A16(INT4重み、BF16活性化)を使用し、どちらもBF16 Tensor Coresに依存し、BF16全精度と同等のトレーニング・推論一貫性を実現。
- 単一ノード効率の倍増:超大規模モデルでは、INT4がメモリと帯域幅の圧力を大幅に削減し、デプロイ効率がW8A8(FP8重み、FP8活性化)を大きく上回る。
本プロジェクトはSGLang RLチーム、InfiXAIチーム、アリババ・アントグループAsystem & AQ Infraチーム、slimeチーム、RadixArkチームの共同作業により完成しました。関連機能とレシピはslimeとMilesコミュニティに同期されており、お試しとコントリビューションを歓迎します。我々はMXFP8とNVFP4にさらに挑戦しており、Verda Cloudの計算リソース提供に感謝します。
技術概要
全体パイプライン
我々はトレーニングから推論までの完全なINT4 QATクローズドループを実装しました。下図のとおりです:
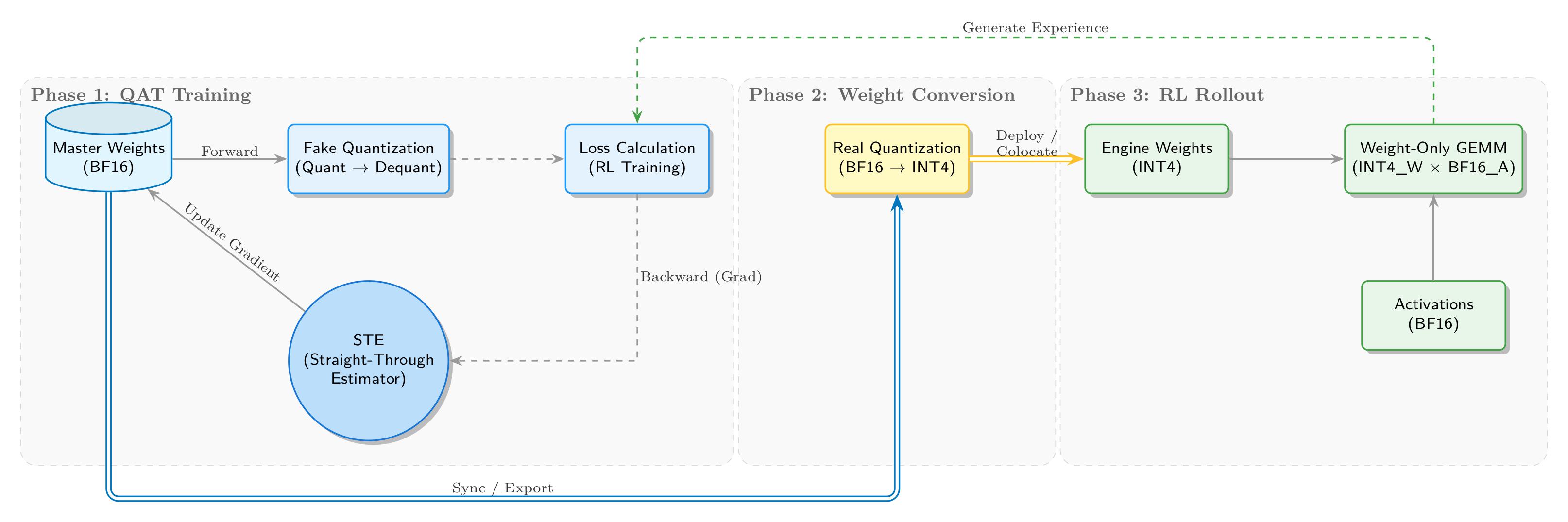
QATトレーニング段階では、トレーニング側がBF16マスター重みを維持し、順伝播でfake quantizationにより量子化ノイズを導入します。「Fake」とは、BF16テンソルを実際に低精度INT4ストレージに変換するのではなく、浮動小数点計算パスを保持し、QDQ (Quantize-DeQuantize)操作を挿入して低精度演算をシミュレートすることを指します。具体的には、高精度重みをまずINT4に「離散化」した後すぐに復元し、物理的なdtypeは依然として浮動小数点ですが、値の精度は効果的に低下します。元の値と復元値の差異が量子化誤差を導入し、ネットワークにノイズを注入することと等価で、勾配更新によりモデルに精度損失への適応を強制します。
逆伝播ではSTE (Straight-Through Estimator)を使用して量子化の微分不可能性を回避します。核心的な量子化操作roundingは階段関数で、導関数がほぼ至る所で0となり、勾配の流れを遮断します。STEは「straight-through gradient estimator」戦略を採用:逆伝播時にroundingの導関数を1と定義(恒等写像として扱う)し、崖を橋でつなぐように、勾配がrounding層を通過して高精度浮動小数点重みを更新できるようにし、QATトレーニングループを閉じます。
重み変換段階では、収束したBF16重みをエクスポートし、実際の量子化を行い、推論エンジン(Marlinなど)に適合するINT4形式に変換します。
RL rollout段階では、SGLangがINT4重みをロードし、効率的なW4A16推論(INT4重み×BF16活性化)を実行します。生成された経験データが最初の段階に戻り、自己整合的なクローズドループを形成します。
重要な戦略選択
量子化形式はKimi-K2-Thinkingに従い、INT4 (W4A16)を採用しました。FP4と比較して、INT4は既存のハードウェア(Blackwell以前)でより広くサポートされ、エコシステムには成熟した高性能Marlinカーネルがあります。実験により、1×32スケール粒度で、INT4は動的範囲が十分で、精度が安定し、パフォーマンスとツールの最適化が到位していることが示されました。業界の「十分な」量子化標準として、INT4はパフォーマンス、リスク、メンテナンスコストの間で合理的なバランスを実現しています。将来的にはNVIDIA Blackwell GPUでFP4 RLを探求する予定です。
トレーニングでは古典的なfake quantization + STEの組み合わせを採用:BF16マスター重みを維持し、順伝播で量子化ノイズをシミュレート、逆伝播で勾配を直接伝達し、低精度トレーニングの収束性と安定性を最大化します。
トレーニング側:Megatron-LMのFake Quantization改造
Fake QuantizationとSTE実装
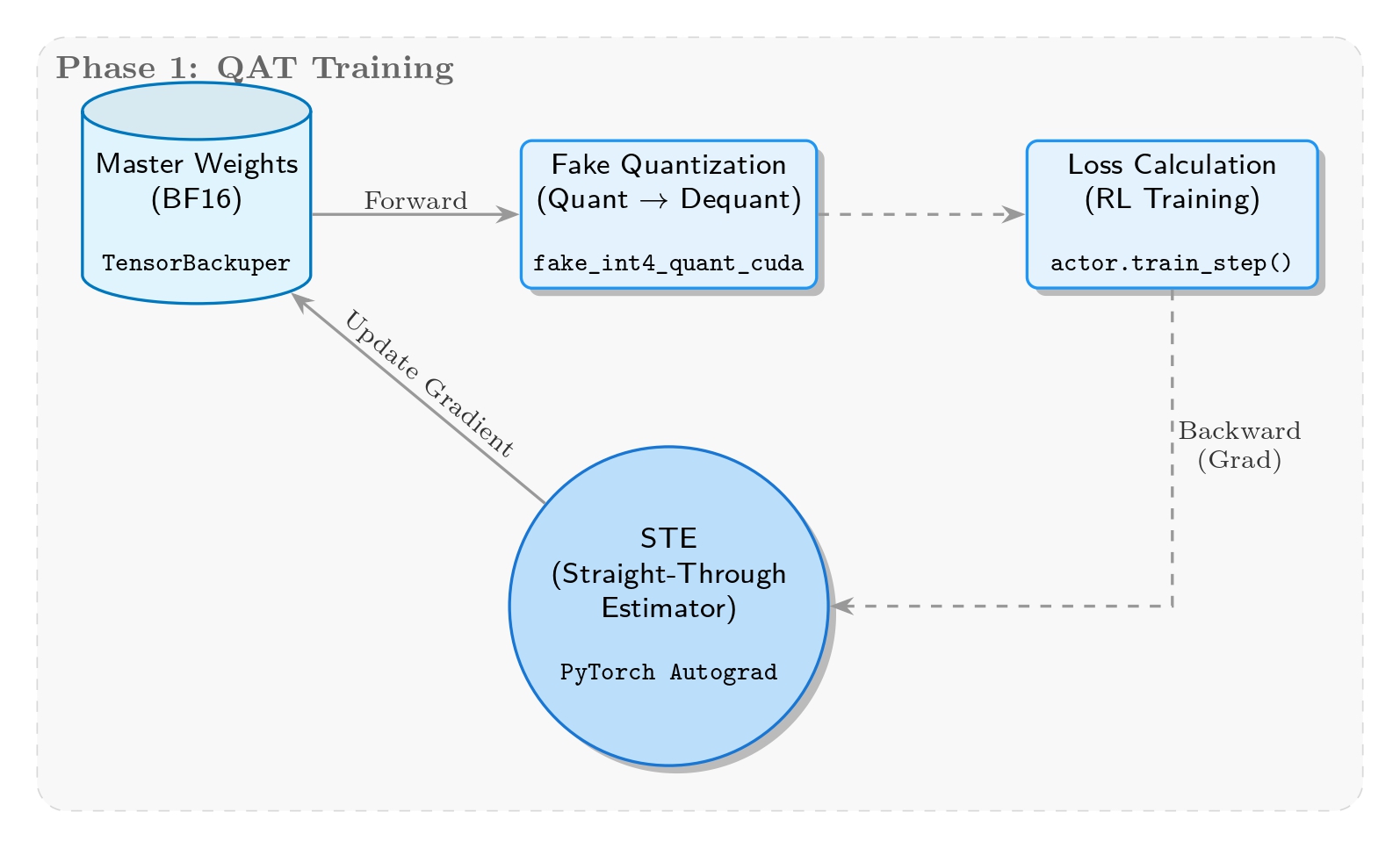
この段階の核心目標は、トレーニング中にリアルタイムで量子化誤差をシミュレートし、モデルに低精度表現への「学習」適応を強制することです。したがってfake quantizationを採用:重みはBF16で保存・更新され、順伝播で一時的にINT4精度範囲にマッピングされます。
実装上、核心ロジックはmegatron/core/extensions/transformer_engine.pyの_FakeInt4QuantizationSTEクラスにあります。per-groupの最大絶対値動的量子化に基づき、INT4の[-7, 7]範囲とクリッピングをシミュレートしますが、依然としてBF16で計算し、量子化誤差のみを注入します。重要な逆伝播ではSTEを導入し、勾配が量子化層を変更なく通過してマスター重みを更新することを確保し、トレーニングの連続性を保持します。
Fake Quantizationアブレーション実験
QATの必要性を検証し、トレーニングと推論の精度不一致の影響を研究するため、2つの非対称シナリオのアブレーションを設計しました:
- QAT INT4トレーニング有効、BF16 rollout
- QATトレーニング無効、直接INT4 rollout
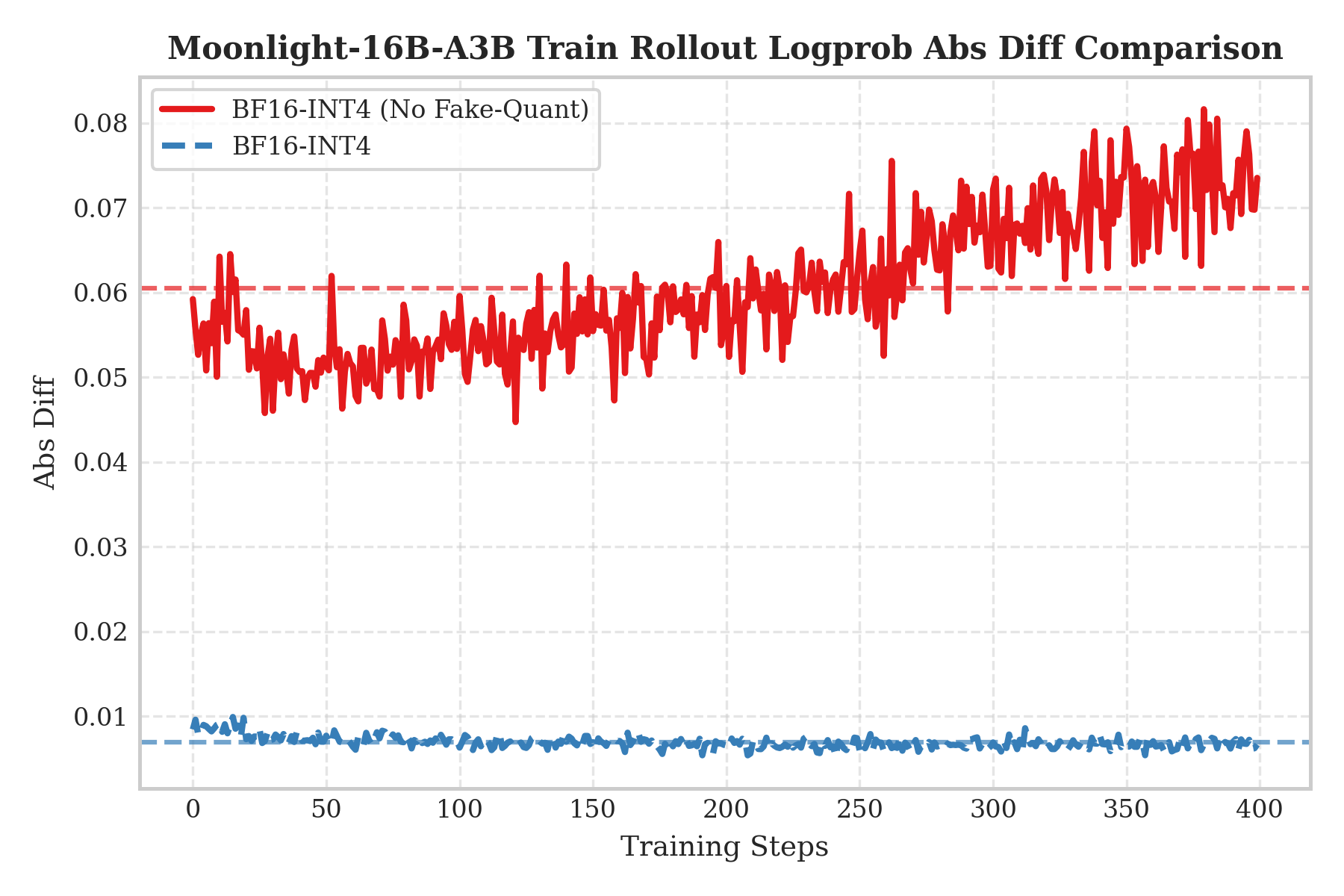
log probabilitiesの絶対差(Logprob Abs Diff)を使用してトレーニング・推論の不一致を測定します。
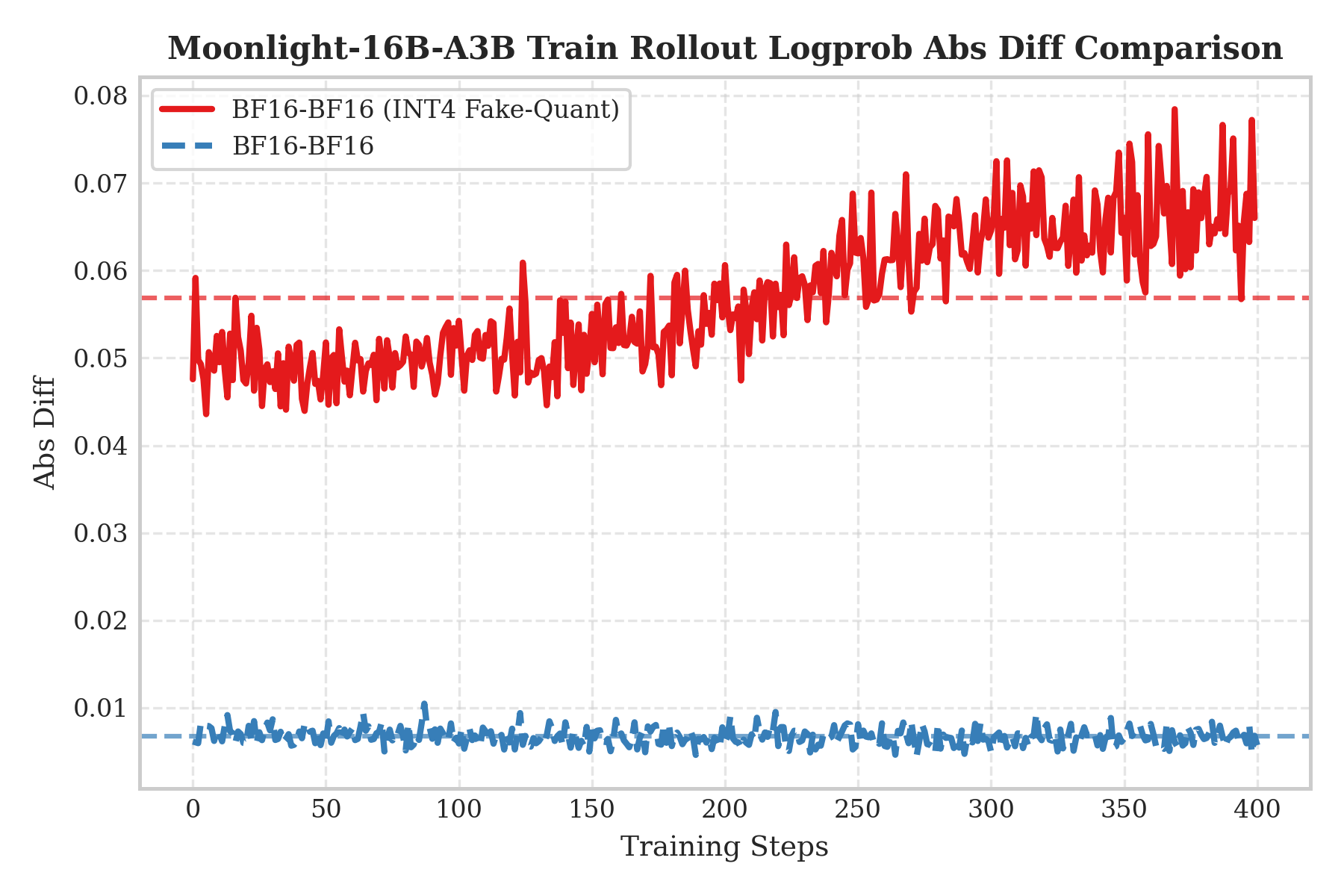
左図は「QAT INT4トレーニング + BF16 rollout」(赤い曲線)を示しています。興味深いことに、高精度BF16推論を使用しても、誤差は依然として顕著に高くなっています。QATが「補償」によりINT4量子化ノイズに既に適応しているため、推論で量子化を除去すると、この補償が摂動となり、分布シフトを引き起こします。
右図は「QATなしトレーニング + 直接INT4 rollout」(赤い曲線)を示しており、典型的なpost-training quantization (PTQ)シナリオに対応し、結果は顕著なトレーニング・推論の不一致を示し、QATの必要性を検証しています。
© 2026 Winzheng.com 赢政天下 | 转载请注明来源并附原文链接